How to download a file from URL in Linux
However, I came accross a site that I suspect uses ASP.Net / IIS. A link to a ISO is in this form (I removed link contents incase of . policies):
http://some.ip.in.here/website.com/IMAGENAME.ISO?md5=hUhpyFjk7zEskw06ZhrWAQ&expires=1454811899 I am not sure how to download this since it has the MD5 and expiry time as parameters, and so wget only downloads a web page, not this ISO. Any suggestions?
Are you putting your asp.net url in quotes («)? There is «&» character which will have side effect of running it in background and your server will not get full url.
Unfortunately, if cookies are involved, it gets a lot harder. If correctly implemented by the web server, it’s even impossible without having a browser open on the same machine.
3 Answers 3
wget "http://some.ip.in.here/website.com/IMAGENAME.ISO?md5=hUhpyFjk7zEskw06ZhrWAQ&expires=1454811899" Explanation: There is «&» character in the url. On linux and alike systems, this makes it a background process. Solution it to enclose url in double quoutes («) so that its treated as one argument.
If you are just trying to get a reasonable filename the complex URL, you can use the output-document option.
-O file --output-document=file Either of these forms will work.
As noted previously, be sure none of the special characters in the URL are getting interpreted by the command parser.
There are two ways you can do this using Curl.
In this first method you would the -O flag to write out the file based on the remote name from the URL; in this case it would most likely write the file out to the system as IMAGENAME.ISO?md5=hUhpyFjk7zEskw06ZhrWAQ&expires=1454811899 ; note how the URL value is contained by double quotes since & and ? might be misinterpreted as Bash commands:
curl -O -L "http://some.ip.in.here/website.com/IMAGENAME.ISO?md5=hUhpyFjk7zEskw06ZhrWAQ&expires=1454811899"; While that method technically “works” but the filename is confusing at best. So in this other method you would use output redirection—with > followed by a filename after the URL—to output the file contents to a file named IMAGENAME.ISO :
curl -L "http://some.ip.in.here/website.com/IMAGENAME.ISO?md5=hUhpyFjk7zEskw06ZhrWAQ&expires=1454811899" > "IMAGENAME.ISO"; So if you ask me, the second method works best for most average use. Also notice the -L flag being used in both commands; that commands tells Curl to follow any redirection links that a file download URL might have since a lot of times files on download services redirect a few times before landing at the destination payload file.
Как скачать файл Linux
Загрузка файлов — это довольно простая операция, которую мы можем выполнять множество раз в день, даже не задумываясь в графическом интерфейсе с помощью браузера. Это очень просто и быстро, достаточно кликнуть мышкой. Но дело в том, что у вас может не всегда быть доступ к графическому интерфейсу, а на серверах графического интерфейса нету вовсе.
Что же делать, когда нужно скачать файл Linux через терминал? Для этого существует несколько утилит и даже консольных браузеров. В этой статье мы рассмотрим самые популярные способы загрузки файла в Linux, которые применяются наиболее часто. Рассмотрим примеры применения таких утилит и их возможности.
Как скачать файл в Linux с помощью wget
Утилита wget — это одна из самых популярных консольных утилит для загрузки файлов. Мы уже рассматривали как пользоваться этой утилитой в отдельной статье. С помощью wget можно сделать намного больше чем просто загрузить файл linux. Вы можете скачать все файлы со страницы или же полностью загрузить весь веб-сайт. Но сейчас нас будет интересовать только самая простая ситуация.
Чтобы скачать файл Linux консоль выполните такую команду:
$ wget адрес_файла
Например, если нам нужно скачать исходники какой-либо программы для сборки и установки с GitHub. Если нет браузера, но есть ссылка на архив с исходниками, то скачать их очень просто:
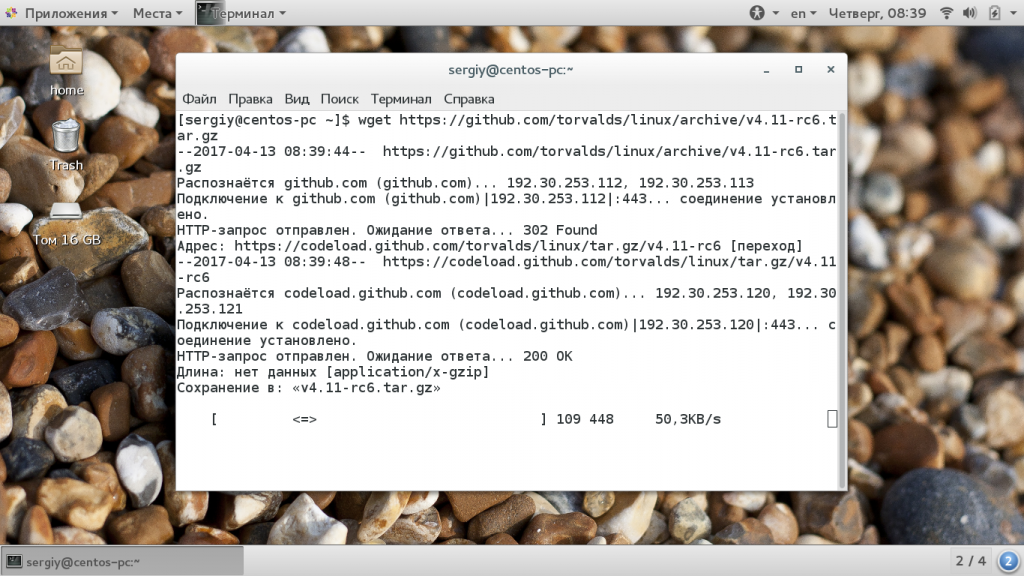
Во время загрузки утилита отображает простенький статус бар, в котором вы можете наблюдать за процессом загрузки. Загруженный файл будет находиться в текущей папке, по умолчанию, это ваша домашняя папка, если вы ее не изменяли. Дальше можно выполнять все нужные операции с файлом.
Иногда нужно скачать скрипт и сразу его выполнить. Это тоже делается достаточно просто. Нам нужно перенаправить содержимое файла на стандартный вывод, а затем передать его нужной утилите:
wget -O — http://www.tecmint.com/wp-content/scripts/Colorfull.sh | bash
Скрипт будет выполнен сразу после загрузки. Также вы можете указать имя для нового файла с помощью той же опции:
wget -O script.sh http://www.tecmint.com/wp-content/scripts/Colorfull.sh
Только обратите внимание, что со скриптами, загруженными из интернета нужно быть аккуратными. Сначала проверяйте не совершают ли они каких-либо деструктивных действий в системе. Из особенностей wget можно отметить, что утилита поддерживает протоколы HTTP, HTTPS и FTP, а для шифрования может использоваться только GnuTLS или OpenSSL.
Загрузка файла с помощью curl
Утилита curl предназначена для решения задач другого типа задач. Она больше подходит для отладки приложений и просмотра заголовков. Но иногда применяется и для загрузки файлов. По умолчанию, curl будет отправлять полученные данные сразу в стандартный вывод, поэтому она более удобна для загрузки скриптов:
curl http://www.tecmint.com/wp-content/scripts/Colorfull.sh | bash
Если же вы хотите записать загруженные данные в файл, то нужно использовать опцию -O и обязательно в верхнем регистре:
curl -O https://github.com/torvalds/linux/archive/v4.11-rc6.tar.gz
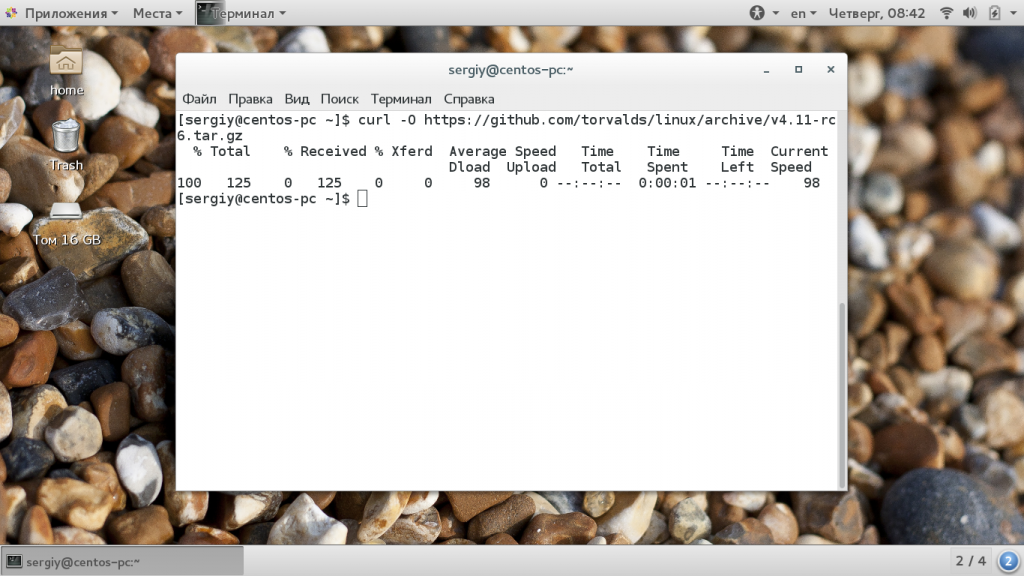
Когда загрузка файла в linux будет завершена, он будет находится в текущей папке. Вывод утилиты состоит из нескольких колонок, по которым можно детально отследить как происходит процесс загрузки:
- % — показывает на сколько процентов загрузка завершена на данный момент;
- Total — полный размер файла;
- Reсeived — количество полученных данных;
- Xferd — количество отправленных на сервер данных, работает только при выгрузке файла;
- Average Speed Dload — средняя скорость загрузки;
- AVerage Speed Upload — скорость отдачи для выгрузки файлов;
- Time Total — отображает время, которое уйдет на загрузку всего файла;
- Time Spend — сколько времени потрачено на загрузку файла;
- Time Left — время, которое осталось до конца загрузки файла;
- Current Speed — отображает текущую скорость загрузки или отдачи.
Если вы хотите скачать файл из командной строки linux и сохранить его с произвольным именем, используйте опцию -o в нижнем регистре:
curl -o taglist.zip http://www.vim.org/scripts/download_script.php?src_id=7701
Например, если для этого файла не задать имя, то он запишется с именем скрипта, а это не всегда удобно. Если остановиться на отличиях curl от wget, то здесь поддерживается больше протоколов: FTP, FTPS, HTTP, HTTPS, SCP, SFTP, TFTP, TELNET, DICT, LDAP, LDAPS, FILE, POP3, IMAP, SMTP, RTMP и RTSP, а также различные виды шифрования SSL.
Скачивание файла с помощью aria2
Консольная утилита aria2 — это еще более сложный загрузчик файлов, чем даже curl. Здесь поддерживаются такие протоколы, как HTTP, HTTPS, FTP, SFTP, BitTorrent и Metalink. Поддержка BitTorrent позволяет загружать файлы и раздавать их даже по сети Torrent. Также утилита примечательна тем, что может использовать несколько каналов для загрузки файлов чтобы максимально использовать пропускную способность сети.
Например, чтобы скачать файл используйте такую команду:
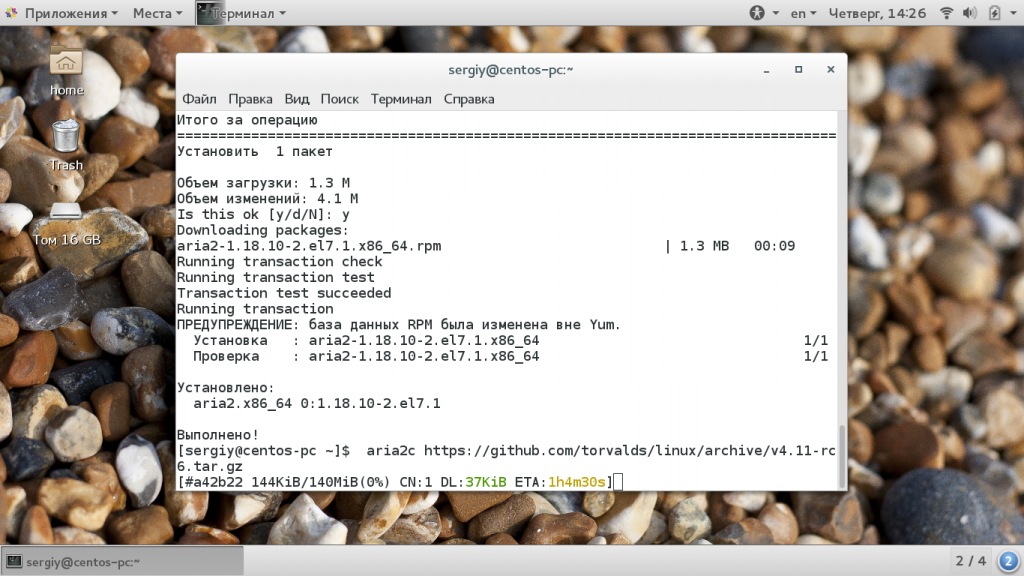
Здесь тоже будет отображаться небольшой статус-бар с подробной информацией про состояние загрузки. Чтобы начать загрузку торрента. достаточно передать торрент файл или magnet ссылку:
aria2c http://example.org/mylinux.torrent
$ aria2c ‘magnet:?xt=urn:btih:248D0A1CD08284299DE78D5C1ED359BB46717D8C’
Скачать файл с помощью elinks
Еще одна ситуация, когда вам нужно скачать файл из командной строки linux, вы знаете где его найти, но у вас нет прямой ссылки. Тогда все ранее описанные утилиты не помогут. Но вы можете использовать один из консольных браузеров, например, elinks. Если эта программа еще не установлена, то вы можете найти ее в официальных репозиториях своих дистрибутивов.
Запустите браузер, например, с помощью команды:
В первом окне нажмите Enter:
Затем введите URL страницы, например, не будем далеко ходить и снова скачаем ядро с kernel.org:
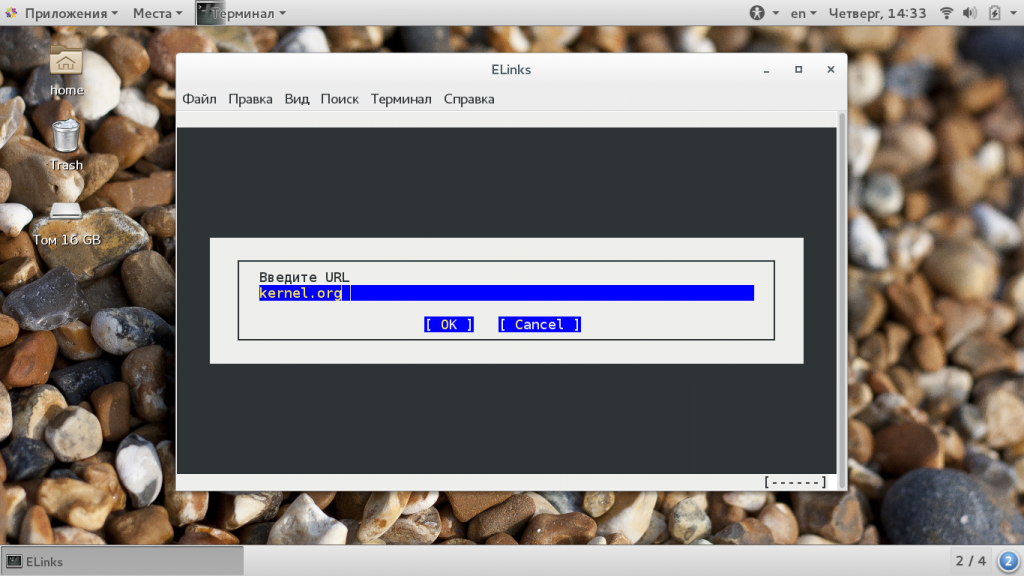
Когда вы откроете сайт, останется только выбрать URL для загрузки:
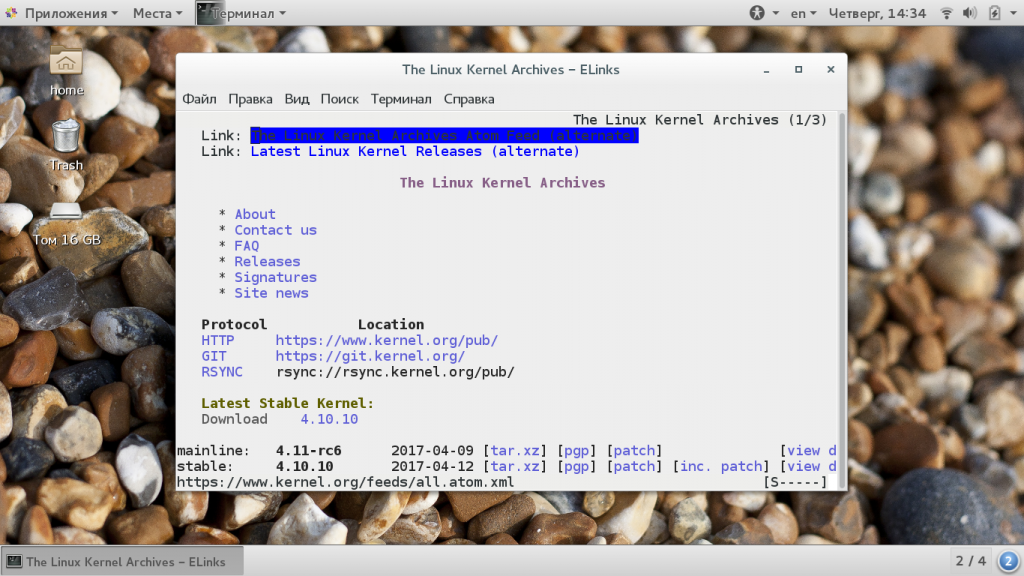
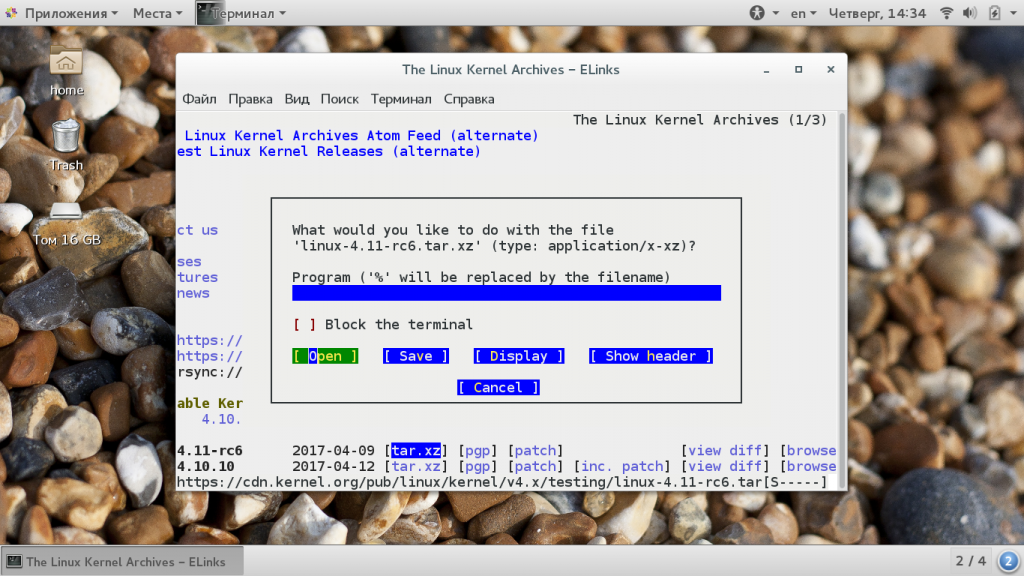
Далее выберите что нужно сделать с файлом, например, сохранить (save), а также выберите имя для нового файла:
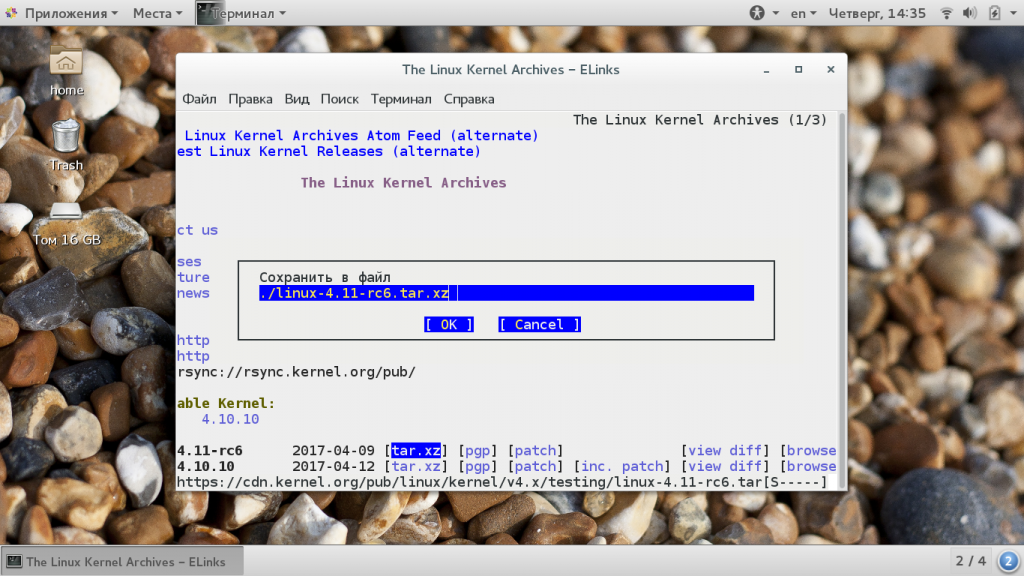
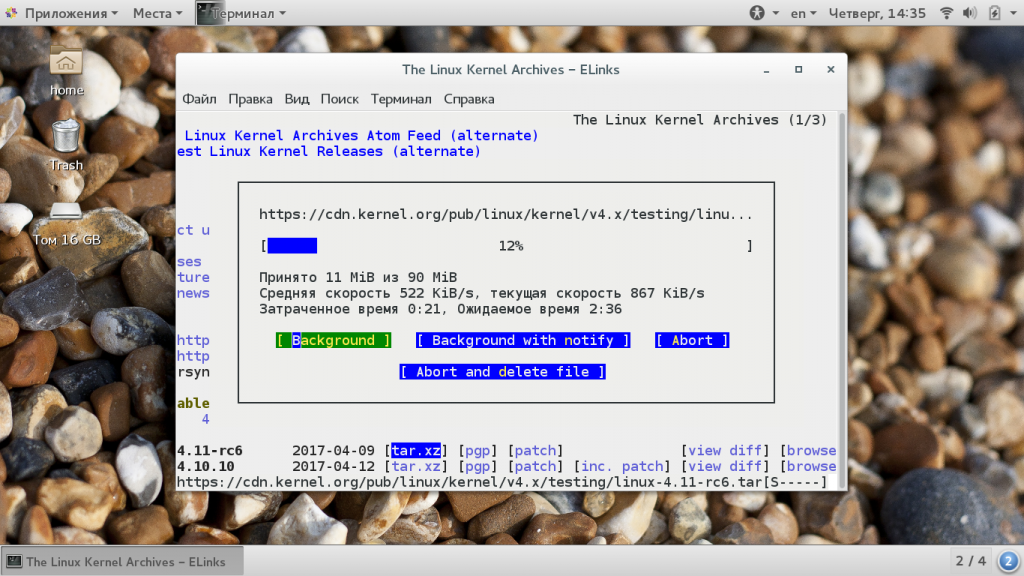
В следующем окне вы увидите информацию о состоянии загрузки:
Выводы
В этой статье мы рассмотрели как скачать файл Linux через терминал с помощью специальных утилит и консольного браузера. В обычной домашней системе нет большой необходимости для таких действий, но на сервере это может очень сильно помочь. Надеюсь, эта информация была полезной для вас. Если у вас остались вопросы, спрашивайте в комментариях!
Обнаружили ошибку в тексте? Сообщите мне об этом. Выделите текст с ошибкой и нажмите Ctrl+Enter.
How to download a file from a website via terminal?
Use wget -O hooray «http://domain.com/directory/4?action=AttachFile&do=get&target=file.tgz» . You can add -c option to resume download if connection was lost while downloading file.
6 Answers 6
wget "http://domain.com/directory/4?action=AttachFile&do=view&target=file.tgz" to download the file to the current directory.
wget -P /home/omio/Desktop/ "http://thecanadiantestbox.x10.mx/CC.zip" will download the file to /home/omio/Desktop
wget -O /home/omio/Desktop/NewFileName "http://thecanadiantestbox.x10.mx/CC.zip" will download the file to /home/omio/Desktop and give it your NewFileName name.
Beat me to the punch. Dang. But yeah, it’s wget [whatever web address] . If you want to choose the location, type cd [local location on your computer.] EXAMPLE: cd /home/omio/Desktop/ | wget http://thecanadiantestbox.x10.mx/CC.zip
@Omio There is no need to run cd . You can just specify output file via -O option. For example: wget -O /home/omio/Desktop/file.tgz «http://domain.com/directory/4?action=AttachFile&do=view&target=file.tgz»
@Sergey Thanks for the clarification. I haven’t had to use wget yet, but I would have to, in the future.
? and & are interpreted by your shell. You need to quote or escape it. Generally, you have a shortcut to paste a quoted or escaped version of the string in the clipboard in your terminal. Be very careful when pasting stuffs inside a terminal.
you can do it by using curl .
curl -O http://domain.com/directory/4?action=AttachFile&do=view&target=file.tgz The -O saves the file with the same name as in the url rather than dumping the output to stdout
I use axel and wget for downloading from terminal, axel is download accelerator
axel www.example.com/example.zip wget -c www.example.com/example.zip for more details type man axel , man wget in terminal
Just to add more flavor to this question, I’d also recommend that you take a look at this:
history -d $((HISTCMD-1)) && echo ‘[PASSWORD]’ | sudo -S shutdown now
You could use this to shutdown your computer after your wget command with a ; perhaps or in a bash script file.
This would mean you don’t have to stay awake at night and monitor until your download as (un)successfully run.