- How to list the first or last 10 lines from a file without decompressing it in linux [closed]
- 2 Answers 2
- 5 Commands to View the Content of a File in Linux Command Line
- 5 commands to view files in Linux
- 2. nl
- 3. Less
- 4. Head
- 5. Tail
- Bonus: Strings command
- Conclusion
- How to Display Contents of a File in Linux
- How to Display Contents of a File in Linux
- Cat
- Head
- Tail
- Flags
- More
- Less
- Tac
- Grep
- Conclusion
- Related Articles:
- About the Author: Dwight Kraft
- How can I get a specific line from a file? [duplicate]
- 6 Answers 6
How to list the first or last 10 lines from a file without decompressing it in linux [closed]
I have a .bz2 file. I want to list the first or last 10 lines without decompress it as it is too big. I tried the head -10 or tail -10 but I see gibberish. I also need to compare two compressed file to check if they are similar or not. how to achieve this without decompressing the files ? EDIT: Similar means identical (have the same content).
What do you mean by similar? BZ2 is a block-based format, so it is possible to decompress only small chunks of a file without reading the whole.
For comparing two compressed files, you may find something on this page, although the question does specifically asks for .zip files. stackoverflow.com/questions/587442/…
The files must get decompressed. I think what you’re actually asking is «without having to save a copy of the decompressed file.»
2 Answers 2
While bzip2 is a block-based compression algorithm, so in theory you could just find the particular blocks you want to decompress, this would be complicated (e.g. what if the last ten lines you ultimately want to see actually spans two or more compressed blocks?).
To answer your immediate question, you can do this, which does actually decompress the entire file, so is in a sense wasteful, but it doesn’t try to store that file anywhere, so you don’t run into storage capacity issues:
bzcat file.bz2 | head -10 bzcat file.bz2 | tail -10 If your distribution doesn’t include bzcat (which would be a bit unusual in my experience), bzcat is equivalent to bzip2 -d -c .
However, if your ultimate goal is to compare two compressed files (that may have been compressed at different levels, and so comparing the actual compressed files directly doesn’t work), you can do this (assuming bash as your shell):
This will decompress both files and compare the uncompressed data byte-by-byte without ever storing either of the decompressed files anywhere.
5 Commands to View the Content of a File in Linux Command Line
Here are five commands that let you view the content of a file in Linux terminal.
If you are new to Linux and you are confined to a terminal, you might wonder how to view a file in the command line.
Reading a file in Linux terminal is not the same as opening file in Notepad. Since you are in the command line mode, you should use commands to read file in Linux.
Don’t worry. It’s not at all complicated to display a file in Linux. It’s easy as well essential that you learn how to read files in the line.
Here are five commands that let you view the content of a file in Linux terminal.
5 commands to view files in Linux
Before you how to view a file in Unix like systems, let me clarify that when I am referring to text files here. There are different tools and commands if you want to read binary files.
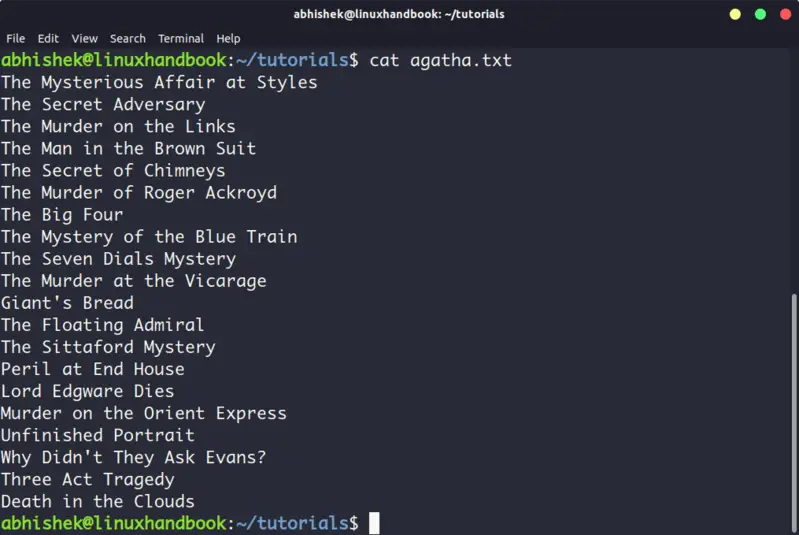
Cat becomes a powerful command when used with its options. I recommend reading this detailed tutorial on using cat command.
The problem with cat command is that it displays the text on the screen. Imagine if you use cat command with a file that has 2000 lines. Your entire screen will be flooded with the 200 lines and that’s not the ideal situation.
So, what do you do in such a case? Use less command in Linux (explained later).
2. nl
The nl command is almost like the cat command. The only difference is that it prepends line numbers while displaying the text in the terminal.
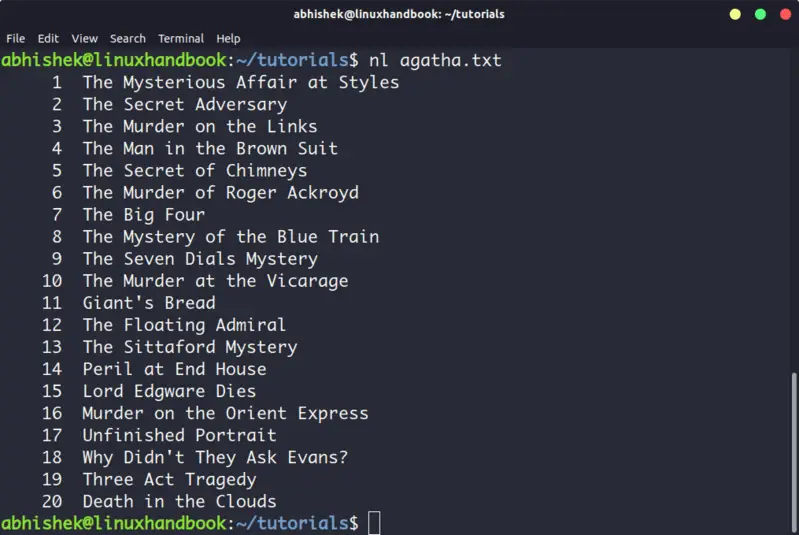
There are a few options with nl command that allows you to control the numbering. You can check its man page for more details.
3. Less
Less command views the file one page at a time. The best thing is that you exit less (by pressing q), there are no lines displayed on the screen. Your terminal remains clean and pristine.
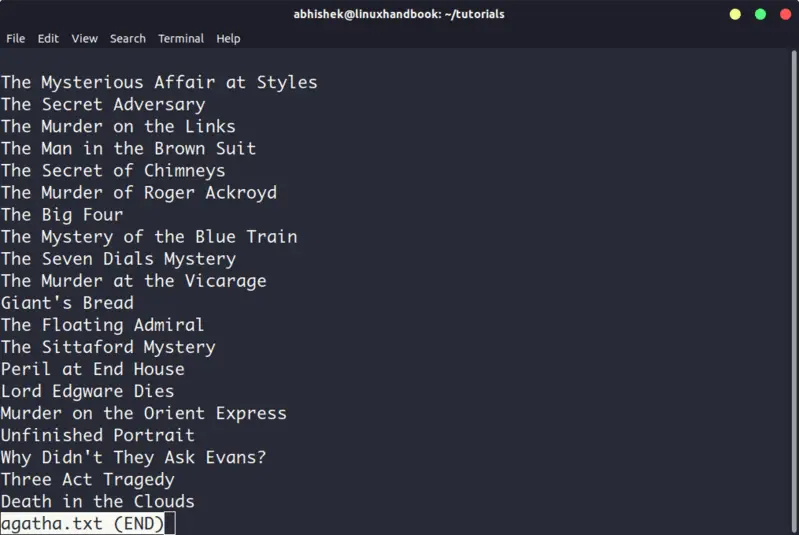
I strongly recommend learning a few options of the Less command so that you can use it more effectively.
There is also more command which was used in olden days but less command has more friendly features. This is why you might come across the humorous term ‘less is more’.
4. Head
Head command is another way of viewing text file but with a slight difference. The head command displays the first 10 lines of a text file by default.
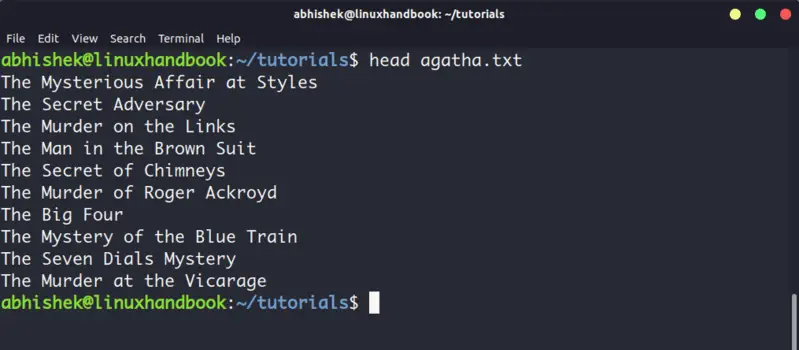
You can change this behavior by using options with head command but the fundamental principle remains the same: head command starts operating from the head (beginning) of the file.
5. Tail
Tail command in Linux is similar and yet opposite to the head command. While head command displays file from the beginning, the tail command displays file from the end.
By default, tail command displays the last 10 lines of a file.
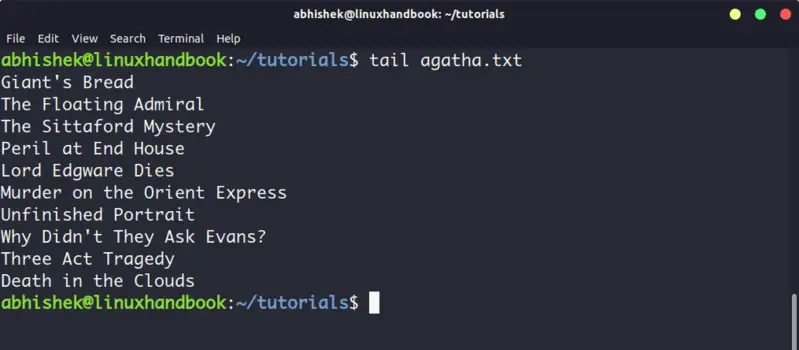
Head and Tail commands can be combined to display selected lines from a file. You can also use tail command to see the changes made to a file in real time.
Bonus: Strings command
Okay! I promised to show only the commands for viewing text files. And this one deals with both text and binary files.
The Strings command displays the readable text from a binary file.
No, it doesn’t convert binary files into text files. If the binary file consists of actual readable text, the strings command displays those text on your screen. You can use the file command to find the type of a file in Linux.
Conclusion
Some Linux users use Vim to view the text file. Of course, you can easily move from the beginning to the end of the lines and edit the file but it’s overkill for just reading a file. My favorite command to open a file in Linux is the less command. It leaves the screen clear and has several options that makes viewing text file a lot easier.
Since you now know ways to view files, maybe you would be interested in knowing how to edit text files in Linux. Cut and Paste are two such commands that you can use for editing text in Linux terminal. You may also read about creating files in Linux command line.
Which command do you prefer?
How to Display Contents of a File in Linux
Whether you are a regular user or an experienced system administrator, sooner or later, you will need to interact with files in Linux through the command line. For example, you might need to troubleshoot an issue by checking the log files, viewing your system’s details, or even customizing it by editing the configuration files.
Knowing how to display the contents of a file in Linux can make your life easier and save you time from constantly opening text editors. Many built-in functions make viewing files easy, fast, and tailored to your needs.
How to Display Contents of a File in Linux
Cat
The simplest way to view text files in Linux is the cat command. It displays the complete contents in the command line without using inputs to scroll through it.
Here is an example of using the cat command to view the Linux version by displaying the contents of the /proc/version file.

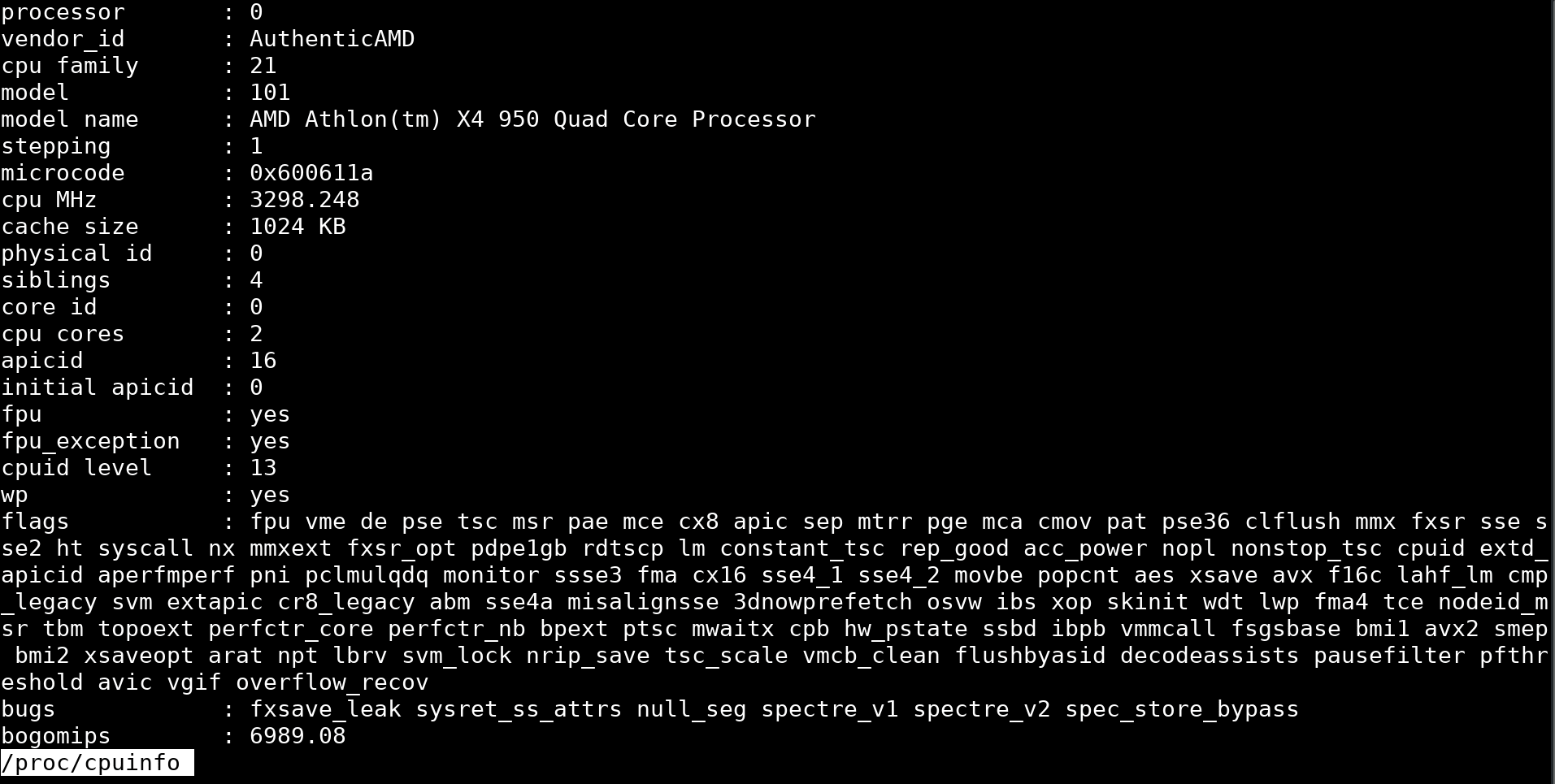
Head
Sometimes the information needed is in the first lines of a file. In that case, use the head command to view the first ten lines of a file in Linux. For example, users can display basic information about the CPU used by viewing the beginning of the /proc/cpuinfo file.

Like the tail command, use the -n flag with the head command to display the desired number of lines, starting from the beginning of a given file. For example, head -5 shows the first five lines of a given file.
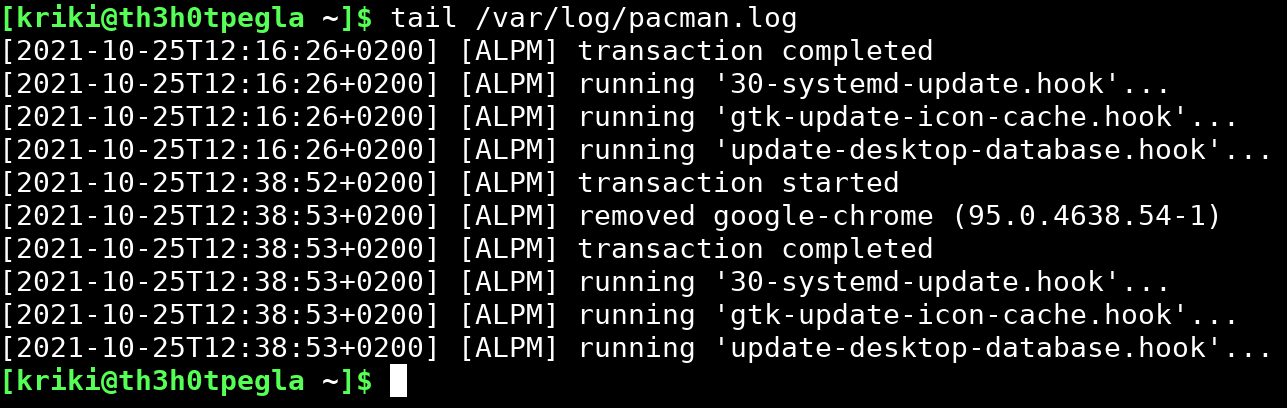
Tail
While the cat command is helpful when dealing with a small file, it is not the best way to view large log files. The tail command allows viewing the last ten lines of a file by default instead of filling your terminal window with a wall of text, making it the perfect command to use if you want to check the last log entries.
Here is the output of the tail command.
Flags
A user can select how many lines the command should display by passing the —n flag (where n is an integer). For example, the tail -15 command will output the last 15 lines on a given file.
Another helpful flag used with the tail command is -f. It outputs the last ten lines of a file by default, but it also keeps displaying new entries as the file is updated. This function is beneficial when viewing the latest updates in log files to troubleshoot an issue. If you only want to use this functionality, you can use the tail -f command, and it will only display the entries that appeared in the file after running the command.
More
Another way to view file contents in Linux is the more command. It displays a file in the terminal, one page at a time. While using the more command, the Enter key scrolls through the file line by line, or the Space key scrolls one full screen at a time. Finally, you can close the file by pressing the Q key.
Here is an example of using more to display the contents of the cpuinfo file in Linux.
Less
While more is a handy command, it does come with a drawback. After closing a file, its contents stay written in the terminal window, filling it with text, forcing users to either clear the window or scroll back up to find something. It can also be slow, as it loads the entire file though displaying only one page at a time.
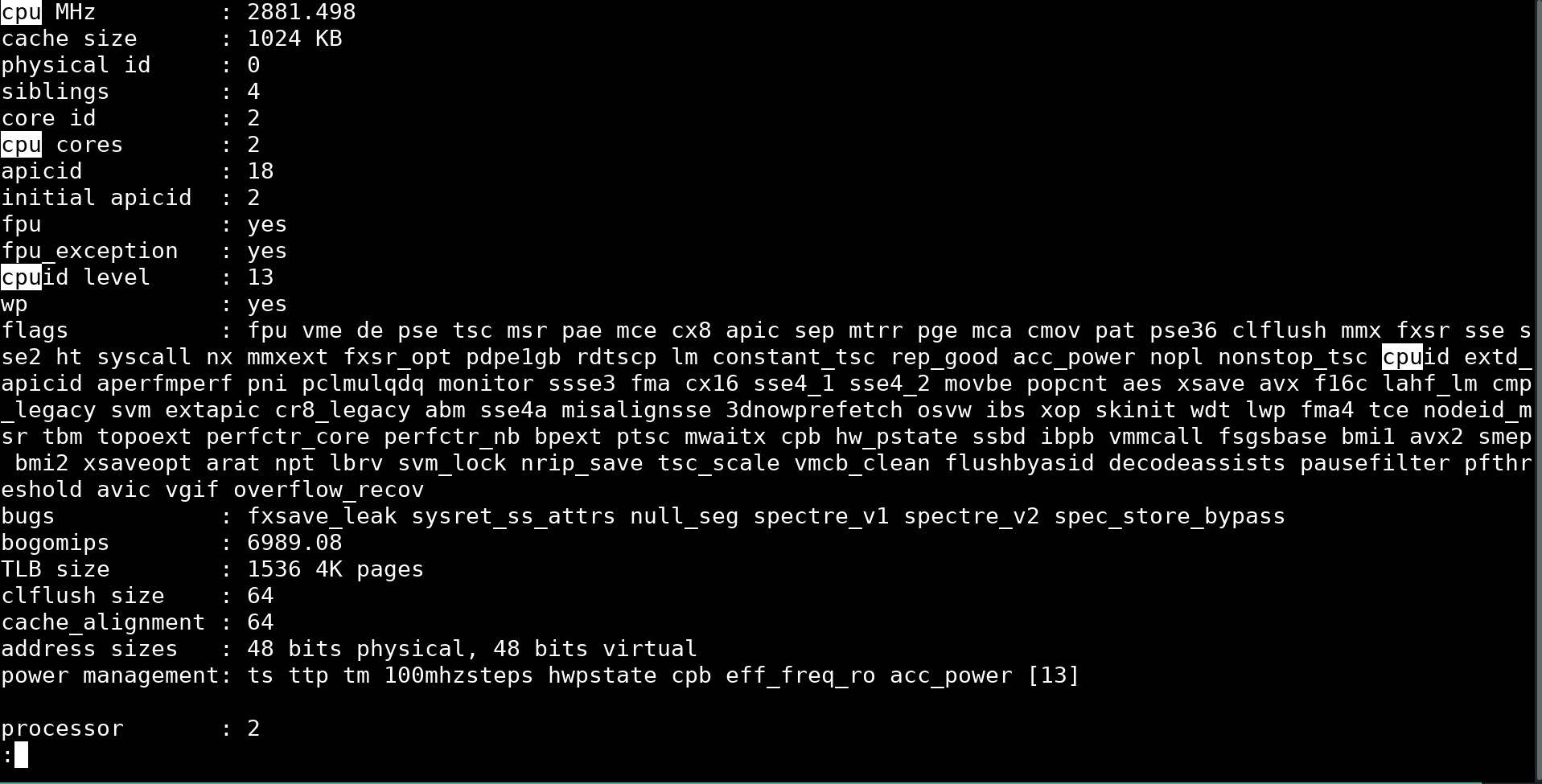
That’s where the less command comes in handy. It’s very similar to more, but with the benefit of not keeping all the text in the terminal window. The less command also comes with a built-in search function, allowing you to highlight the parts of the file for which you are looking. To search with less, press the forward slash key followed by the text you want to search.
The following is what the search function looks like if we search for /cpu in the cpuinfo file.
Tac
Another exciting way to display the contents of a file in Linux is in reverse order. To do so, use the tac command. It is similar to cat but reversed, reading and displaying the file starting from the last line. For example, here is what the output of tac looks like used to display the contents of the cpuinfo file.
For better readability, pipe the tac command into less to scroll through the file. Users accomplish piping using the desired command, the pipe character, and the other command. The syntax is as follows.
Here is an example output from this command.
Grep
While not used for displaying the contents of a file, the grep command is handy for filtering the output of commands. For example, grep works for searching for specific text in a file.

In addition, pipe the output of other commands through grep, narrowing the search to what we are looking for in the file.
Here is an example of piping the output from the head command into the grep command.

Conclusion
While it might seem intimidating at first, learning how to display the contents of a file in Linux will make it significantly easier to navigate through any Linux distribution. These skills save time and make your job easier.
Do you already know how to display the contents of a file in Linux and just need hosting? Liquid Web has managed hosting options to help you get started with your next project. Contact our sales team to make your purchase.
Related Articles:
About the Author: Dwight Kraft
Dwight is a 3rd year IT student that is passionate about computer hardware and pretty much everything electronics-related. In his free time, he builds PCs and plays guitar for fun.

Join our mailing list to receive news, tips, strategies, and inspiration you need to grow your business
How can I get a specific line from a file? [duplicate]
I want to extract an exact line from a very big file. For example, line 8000 would be gotten like this:
command -line 8000 > output_line_8000.txt Many of the methods below are mentioned in this SO Q&A as well: stackoverflow.com/questions/6022384/…
6 Answers 6
There’s already an answer with perl and awk . Here’s a sed answer:
The advantage of the q command is that sed will quit as soon as the 8000-th line is read (unlike the other perl and awk methods (it was changed after common creativity, haha)).
A pure Bash possibility (bash≥4):
This will slurp the content of file in an array ary (one line per field), but skip the first 7999 lines ( -s 7999 ) and only read one line ( -n 1 ).
It’s Saturday and I had nothing better to do so I tested some of these for speed. It turns out that the sed , gawk and perl approaches are basically equivalent. The head&tail one is the slowest but, suprisingly, the fastest by an order of magnitude is the pure bash one:
$ for i in ; do echo "This is line $i" >>file; done The above creates a file with 50 million lines which occupies 100M.
$ for cmd in "sed -n '8000' file" \ "perl -ne 'print && exit if $. == 8000' file" \ "awk 'FNR==8000 ' file" "head -n 8000 file | tail -n 1" \ "mapfile -s 7999 -n 1 ary < file; printf '%s' \"$\"" \ "tail -n 8001 file | head -n 1"; do echo "$cmd"; for i in ; do (time eval "$cmd") 2>&1 | grep -oP 'real.*?m\K[\d\.]+'; done | awk 'END'; done sed -n '8000' file 0.04502 perl -ne 'print && exit if $. == 8000' file 0.04698 awk 'FNR==8000 ' file 0.04647 head -n 8000 file | tail -n 1 0.06842 mapfile -s 7999 -n 1 ary < file; printf '%s' "This is line 8000 " 0.00137 tail -n 8001 file | head -n 1 0.0033