- Count all occurrences of a string in lots of files with grep
- 16 Answers 16
- 16 полезных примеров grep
- Синтаксис grep
- 1. Поиск среди нескольких файлов
- 2. Регистронезависимый поиск
- 3. Поиск слова
- 4. Вывод количества совпадений
- 5. Поиск в поддиректориях
- 6. Инверсивный поиск
- 7. Вывод нумерации строк
- 8. Ограничение вывода
- 9. Вывод дополнительных строк
- 10. Вывод списка файлов
- 11. Вывод абсолютных совпадений
- 12. Поиск совпадения в начале строки
- 13. Поиск совпадения в конце строки
- 14. Использования файла шаблонов
- 15. Поиск по нескольким шаблонам
- 16. Указание расширенных регулярных выражений
- Заключение
Count all occurrences of a string in lots of files with grep
Can you tell me what the grep -v :0 does ? . I know it counts for files having occurrences greater than 0. What does the -v option and :0 mean ?. Kindly let me know.
@GauthamHonnavara grep :0 looks for line that match the string :0. -v is an option to invert that search so instead using grep -v :0 means find all line that don’t contain :0 so a line with file4:5 and file27:193 all would pass through since they don’t contain :0
16 Answers 16
This works for multiple occurrences per line:
This one shows the relevant files and then the total count of matches: grep -rc test . | awk -F: ‘$NF > 0 END’
This has the same limitation that it counts multiple occurrences on one line only once. I am guessing that this behavior is OK in this case, though.
This doesn’t work if you want to search in subdirectories too, whereas grep -o and wc -l does. cat is quicker in cases like the original question though.
will count multiple occurrences in a line
Instead of using -c, just pipe it to wc -l.
This will list each occurrence on a single line and then count the number of lines.
This will miss instances where the string occurs 2+ times on one line, though.
Piping to «wc -l» works also nicely together with «grep -r ‘test’ .» which scans recursively all files for the string ‘test’ in all directories below the current one.
One of the rare useful applications of cat .
You can add -R to search recursively (and avoid to use cat) and -I to ignore binary files.
grep -c string * | awk 'BEGINEND' Take care if your file names include «:» though.
Something different than all the previous answers:
If you want number of occurrences per file (example for string «tcp»):
grep -RIci "tcp" . | awk -v FS=":" -v OFS="\t" '$2>0 < print $2, $1 >' | sort -hr 53 ./HTTPClient/src/HTTPClient.cpp 21 ./WiFi/src/WiFiSTA.cpp 19 ./WiFi/src/ETH.cpp 13 ./WiFi/src/WiFiAP.cpp 4 ./WiFi/src/WiFiClient.cpp 4 ./HTTPClient/src/HTTPClient.h 3 ./WiFi/src/WiFiGeneric.cpp 2 ./WiFi/examples/WiFiClientBasic/WiFiClientBasic.ino 2 ./WiFiClientSecure/src/ssl_client.cpp 1 ./WiFi/src/WiFiServer.cpp - grep -RIci NEEDLE . — looks for string NEEDLE recursively from current directory (following symlinks), ignoring binaries, counting number of occurrences, ignoring case
- awk . — this command ignores files with zero occurrences and formats lines
- sort -hr — sorts lines in reverse order by numbers in first column
Of course, it works with other grep commands with option -c (count) as well. For example:
grep -c "tcp" *.txt | awk -v FS=":" -v OFS="\t" '$2>0 < print $2, $1 >' | sort -hr The AWK solution which also handles file names including colons:
grep -c string * | sed -r 's/^.*://' | awk 'BEGIN<>END' Keep in mind that this method still does not find multiple occurrences of string on the same line.
You can use a simple grep to capture the number of occurrences effectively. I will use the -i option to make sure STRING/StrING/string get captured properly.
Command line that gives the files’ name:
grep -oci string * | grep -v :0 Command line that removes the file names and prints 0 if there is a file without occurrences:
Could you please elaborate more your answer adding a little more description about the solution you provide?
short recursive variant:
find . -type f -exec cat <> + | grep -c 'string' Grep only solution which I tested with grep for windows:
grep -ro "pattern to find in files" "Directory to recursively search" | grep -c "pattern to find in files" This solution will count all occurrences even if there are multiple on one line. -r recursively searches the directory, -o will «show only the part of a line matching PATTERN» — this is what splits up multiple occurences on a single line and makes grep print each match on a new line; then pipe those newline-separated-results back into grep with -c to count the number of occurrences using the same pattern.
16 полезных примеров grep
![]()
Изначально разработанный для Unix-систем grep, является одной из наиболее широко используемых утилит командной строки в среде Linux.
grep расшифровывается как «глобальный поиск строк, соответствующих регулярному выражению и их вывод» (globally search for a regular expression and print matching lines). grep в основном ищет на основе указанного посредством стандартного ввода или файла шаблона, или регулярного выражения и печатает строки, соответствующие заданным критериям. Часто используется для фильтрации ненужных деталей при печати только необходимой информации из больших файлов журнала.
Это возможно благодаря совместной работе регулярных выражений и поддерживаемых grep параметров.
Здесь мы рассмотрим некоторые из часто используемых сисадминами или разработчиками команд grep в различных сценариях.
Синтаксис grep
Команда grep принимает шаблон и необязательные аргументы вместе со перечислять файлов, если используется без трубопровода.
$ grep [options] pattern [files]
1. Поиск среди нескольких файлов
grep позволяет выполнять поиск заданного шаблона не только в одном, но и среди нескольких файлах. Для этого можно использовать подстановочный символ * .
$ sudo grep -i err /var/log/messages
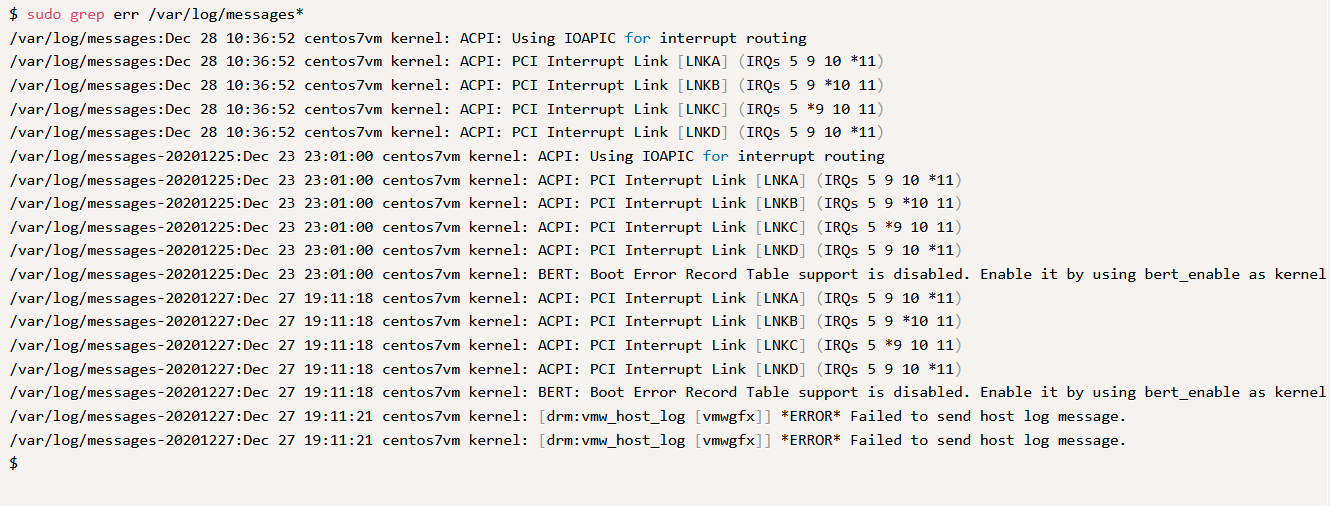
Как видно из вывода, утилита перед результатом искомого шаблона выводит также название файла, что позволяет определить где именно было найдено совпадение.
2. Регистронезависимый поиск
grep позволяет искать шаблон без учета регистра. Чтобы указать grep игнорировать регистр используется флаг –i .
![$ grep -i [pattern] [file]](https://wiki.merionet.ru/images/16-poleznyh-primerov-grep/2.png)
3. Поиск слова
Иногда появляется необходимость поиска не части, а целого слова. В таких случаях утилита запускается с флагом -w .
![$ grep -w [pattern] [file]](https://wiki.merionet.ru/images/16-poleznyh-primerov-grep/3.png)
4. Вывод количества совпадений
Не всегда нужно выводить результат совпадения. Иногда достаточно только количества совпадений с заданным шаблоном. Эту информацию мы можем получить с помощью параметра -c .
![$ grep -c [pattern] [file]](https://wiki.merionet.ru/images/16-poleznyh-primerov-grep/4.png)
5. Поиск в поддиректориях
Часто необходимо искать файлы не только в текущей директории, но и в подкаталогах. grep позволяет легко сделать это с флагом -r .
![$ grep -r [pattern] *](https://wiki.merionet.ru/images/16-poleznyh-primerov-grep/5.png)
6. Инверсивный поиск
Если вы хотите найти что-то, что не соответствует заданному шаблону, grep позволяет сделать только это с флагом -v .
![$ grep -v [pattern] [file]](https://wiki.merionet.ru/images/16-poleznyh-primerov-grep/6.png)
Можно сравнить выходные резултаты grep для одного и того же шаблона и файла с флагом -v и без него. С параметром -v выводятся любые строки, которые не соответствуют образцу.
7. Вывод нумерации строк
grep позволяет нумеровать совпавшие строки, что позволяет легко определить, где строка находится в файле. Чтобы получить номера строк в выходных данных. используйте параметр –n :
![$ grep -n [pattern] [file]](https://wiki.merionet.ru/images/16-poleznyh-primerov-grep/7.png)
8. Ограничение вывода
Результат вывода grep для файлов вроде журналов событий и т.д. может быть длинным, и вам может просто понадобиться фиксированное количество строк. Мы можем использовать -m [num] , чтобы ограничить выводимые строки.
Обратите внимание, как использование флага -m влияет на вывод grep для одного и того же набора условий в примере ниже:
![$ grep -m[num] [pattern] [file]](https://wiki.merionet.ru/images/16-poleznyh-primerov-grep/8.png)
9. Вывод дополнительных строк
Часто нам нужны не только строки, которые совпали с шаблоном, но некоторые строки выше или ниже их для понимания контекста.
С помощью флагов -A , -B или -C со значением num можно выводить строки выше или ниже (или и то, и другое) совпавшей строки. Здесь число обозначает количество дополнительных печатаемых строк, которое находится чуть выше или ниже соответствующей строки. Это применимо ко всем совпадениям, найденным grep в указанном файле или списке файлов.
$ grep -A[num] [pattern] [file] $ grep -B[num] [pattern] [file] $ grep -C[num] [pattern] [file]
Ниже показан обычный вывод grep, а также вывод с флагом -A , -B и -C один за другим. Обратите внимание, как grep интерпретирует флаги и их значения, а также изменения в соответствующих выходных данных. С флагом -A1 grep печатает 1 строку, которая следует сразу после соответствующей строки.
Аналогично, с флагом -B1 он печатает 1 строку непосредственно перед соответствующей строкой. С флагом -C1 он печатает 1 строку, которая находится до и после соответствующей строки.

10. Вывод списка файлов
Чтобы напечатать только имя файлов, в которых найден образец, а не сами совпадающие строки, используйте флаг -l .
![$ grep -l [pattern] [file]](https://wiki.merionet.ru/images/16-poleznyh-primerov-grep/10.png)
11. Вывод абсолютных совпадений
Иногда нам нужно печатать строки, которые точно соответствуют заданному образцу, а не какой-то его части. Флаг -x grep позволяет делать именно это.
В приведенном ниже примере файл file.txt содержит строку только с одним словом «support», что соответствует требованию grep с флагом –x . При этом игнорируются строки, которые могут содержать слова «support» с сопутствующим текстом.
![$ grep -x [pattern] [file]](https://wiki.merionet.ru/images/16-poleznyh-primerov-grep/11.png)
12. Поиск совпадения в начале строки
С помощью регулярных выражений можно найти последовательность в начале строки. Вот как это сделать.

Обратите внимание, как с помощью символ каретки ^ изменяет выходные данные. Символ каретки указывает grep выводить результат, только если искомое слово находится в начале строки. Если в шаблоне есть пробелы, то можно заключить весь образец в кавычки.
13. Поиск совпадения в конце строки
Другим распространенным регулярным выражением является поиск шаблона в конце строки.
![[string]$](https://wiki.merionet.ru/images/16-poleznyh-primerov-grep/13.png)
В данном примере мы искали точку в конце строки. Поскольку точка . является значимым символом, нужно её экранировать, чтобы среда интерпретировала точку как команду. Обратите внимание, как изменяется вывод, когда мы просто ищем совпадения . и когда мы используем $ для указания grep искать только те строки, которые заканчиваются на . (не те, которые могут содержать его где-либо между ними).
14. Использования файла шаблонов
Могут возникнуть ситуации, когда у вас есть сложный список шаблонов, которые вы часто используете. Вместо записи его каждый раз можно указать список этих образцов в файле и использовать с флагом -f . Файл должен содержать по одному образцу на каждой строке.
$ grep -f [pattern_file] [file_to_match]
В нашем примере мы создали файла шаблона с названием pattern.txt со следующим содержимым:

Для его использования используйте флаг -f .

15. Поиск по нескольким шаблонам
grep позволяет задать несколько шаблонов с помощью флага -e .
$ grep -e [pattern1] -e [pattern2] -e [pattern3]. [file]
![$ grep -e [pattern1] -e [pattern2] -e [pattern3]. [file]](https://wiki.merionet.ru/images/16-poleznyh-primerov-grep/16.png)
16. Указание расширенных регулярных выражений
grep также поддерживает расширенные регулярные выражения (Extended Regular Expressions – ERE) или с использованием флага -E . Это похоже на команду egrep в Linux.
Использование ERE имеет преимущество, когда вы хотите рассматривать метасимволы как есть и не хотите экранировать их. При этом использование -E с grep эквивалентно команде egrep .
$ grep -E '[Extended RegEx]' [file]
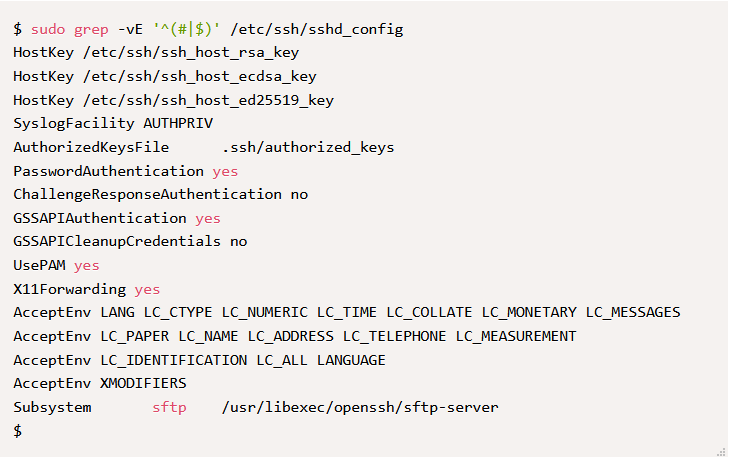
Ниже приведён пример использование ERE, для вывода не пустых и не закомментированных строк. Это особенно полезно для поиска чего-то в больших конфигурационных файлах. Здесь дополнительно использован флаг –v , чтобы НЕ выводить строки, соответствующих шаблону ‘^ (# | $)’ .
Заключение
Приведенные выше примеры являются лишь верхушкой айсберга. grep поддерживает ряд вариантов и может быть очень полезным инструментом в руке человека, который знает, как его эффективно использовать. Мы можем не только использовать приведенные выше примеры, но и комбинировать их различными способами, чтобы получить то, что нам нужно. Для получения дополнительной информации можно воспользоваться встроенной системой справки Linux – man .