- Команда grep в Linux
- Что такое grep?
- Синтаксис grep
- Опции
- Примеры использования grep
- 1. Поиск текста в файле
- 2. Фильтрация вывода команды
- 3. Базовые регулярные выражения
- 4. Расширенные регулярные выражения
- 5. Вывод контекста
- 6. Рекурсивный поиск в grep
- 7. Выбор файлов для поиска
- 8. Поиск слов в grep
- 9. Количество строк
- 10. Инвертированный поиск
- 11. Вывод имен файлов
- 12. Цветной вывод
- Выводы
- How to get line number from grep?
- 4 Answers 4
- You must log in to answer this question.
- Related
- Hot Network Questions
- Subscribe to RSS
Команда grep в Linux
Иногда может понадобится найти файл, в котором содержится определённая строка или найти строку в файле, где есть нужное слово. В Linux для этого существует несколько утилит, одна из самых используемых это grep. С её помощью можно искать не только строки в файлах, но и фильтровать вывод команд, и много чего ещё.
В этой инструкции мы рассмотрим что такое команда grep Linux, подробно разберём синтаксис и возможные опции grep, а также приведём несколько примеров работы с этой утилитой.
Что такое grep?
Название команды grep расшифровывается как «search globally for lines matching the regular expression, and print them». Это одна из самых востребованных команд в терминале Linux, которая входит в состав проекта GNU. До того как появился проект GNU, существовала утилита предшественник grep, тем же названием, которая была разработана в 1973 году Кеном Томпсоном для поиска файлов по содержимому в Unix. А потом уже была разработана свободная утилита с той же функциональностью в рамках GNU.
Grep дает очень много возможностей для фильтрации текста. Вы можете выбирать нужные строки из текстовых файлов, отфильтровать вывод команд, и даже искать файлы в файловой системе, которые содержат определённые строки. Утилита очень популярна, потому что она уже предустановлена прочти во всех дистрибутивах.
Синтаксис grep
Синтаксис команды выглядит следующим образом:
$ grep [опции] шаблон [/путь/к/файлу/или/папке. ]
$ команда | grep [опции] шаблон
- Опции — это дополнительные параметры, с помощью которых указываются различные настройки поиска и вывода, например количество строк или режим инверсии.
- Шаблон — это любая строка или регулярное выражение, по которому будет выполняться поиск.
- Имя файла или папки — это то место, где будет выполняться поиск. Как вы увидите дальше, grep позволяет искать в нескольких файлах и даже в каталоге, используя рекурсивный режим.
Возможность фильтровать стандартный вывод пригодится, например, когда нужно выбрать только ошибки из логов или отфильтровать только необходимую информацию из вывода какой-либо другой утилиты.
Опции
Давайте рассмотрим самые основные опции утилиты, которые помогут более эффективно выполнять поиск текста в файлах grep:
- -E, —extended-regexp — включить расширенный режим регулярных выражений (ERE);
- -F, —fixed-strings — рассматривать шаблон поиска как обычную строку, а не регулярное выражение;
- -G, —basic-regexp — интерпретировать шаблон поиска как базовое регулярное выражение (BRE);
- -P, —perl-regexp — рассматривать шаблон поиска как регулярное выражение Perl;
- -e, —regexp — альтернативный способ указать шаблон поиска, опцию можно использовать несколько раз, что позволяет указать несколько шаблонов для поиска файлов, содержащих один из них;
- -f, —file — читать шаблон поиска из файла;
- -i, —ignore-case — не учитывать регистр символов;
- -v, —invert-match — вывести только те строки, в которых шаблон поиска не найден;
- -w, —word-regexp — искать шаблон как слово, отделенное пробелами или другими знаками препинания;
- -x, —line-regexp — искать шаблон как целую строку, от начала и до символа перевода строки;
- -c — вывести количество найденных строк;
- —color — включить цветной режим, доступные значения: never, always и auto;
- -L, —files-without-match — выводить только имена файлов, будут выведены все файлы в которых выполняется поиск;
- -l, —files-with-match — аналогично предыдущему, но будут выведены только файлы, в которых есть хотя бы одно вхождение;
- -m, —max-count — остановить поиск после того как будет найдено указанное количество строк;
- -o, —only-matching — отображать только совпавшую часть, вместо отображения всей строки;
- -h, —no-filename — не выводить имя файла;
- -q, —quiet — не выводить ничего;
- -s, —no-messages — не выводить ошибки чтения файлов;
- -A, —after-content — показать вхождение и n строк после него;
- -B, —before-content — показать вхождение и n строк после него;
- -C — показать n строк до и после вхождения;
- -a, —text — обрабатывать двоичные файлы как текст;
- —exclude — пропустить файлы имена которых соответствуют регулярному выражению;
- —exclude-dir — пропустить все файлы в указанной директории;
- -I — пропускать двоичные файлы;
- —include — искать только в файлах, имена которых соответствуют регулярному выражению;
- -r — рекурсивный поиск по всем подпапкам;
- -R — рекурсивный поиск включая ссылки;
Все самые основные опции рассмотрели, теперь давайте перейдём к примерам работы команды grep Linux.
Примеры использования grep
Давайте перейдём к практике. Сначала рассмотрим несколько основных примеров поиска внутри файлов Linux с помощью grep.
1. Поиск текста в файле
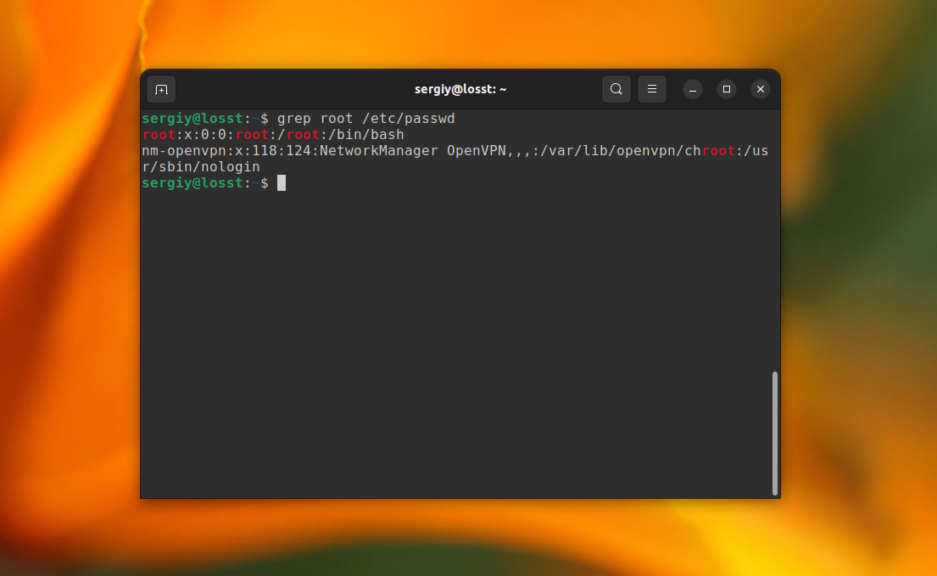
В первом примере мы будем искать информацию о пользователе root в файле со списком пользователей Linux /etc/passwd. Для этого выполните следующую команду:
В результате вы получите что-то вроде этого:
С помощью опции -i можно указать, что регистр символов учитывать не нужно. Например, давайте найдём все строки содержащие вхождение слова time в том же файле:
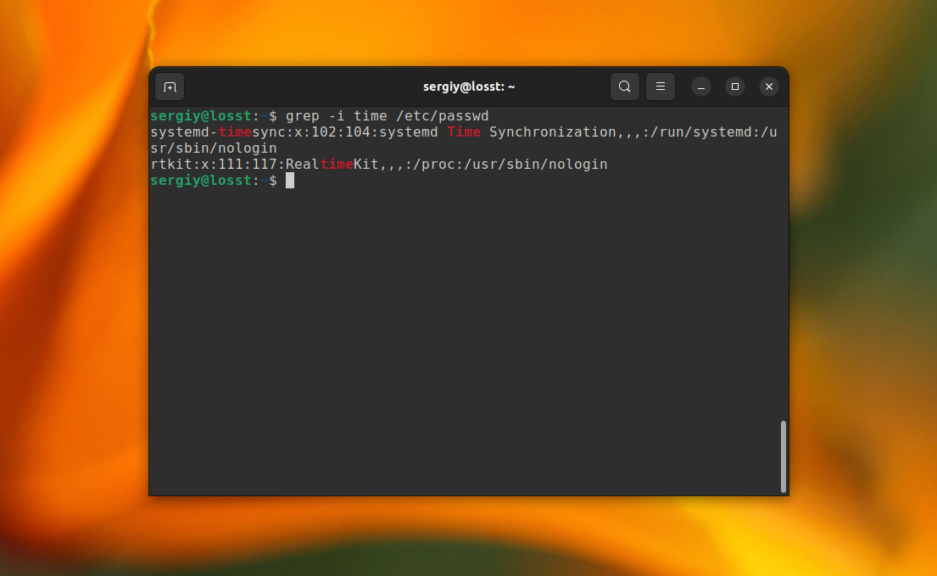
grep -i «time» /etc/passwd
В этом случае Time, time, TIME и другие вариации слова будут считаться эквивалентными. Ещё, вы можете указать несколько условий для поиска, используя опцию -e. Например:
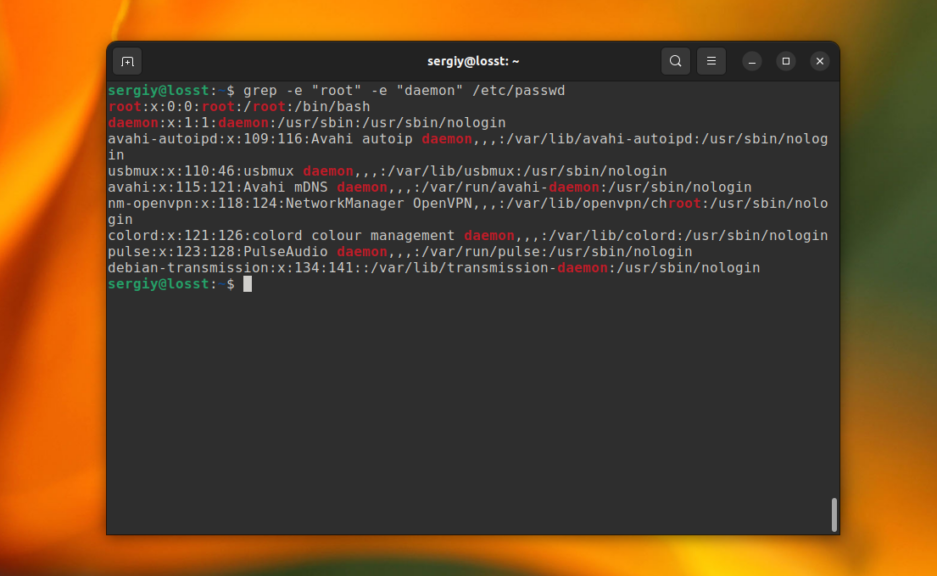
grep -e «root» -e «daemon» /etc/passwd
C помощью опции -n можно выводить номер строки, в которой найдено вхождение, например:
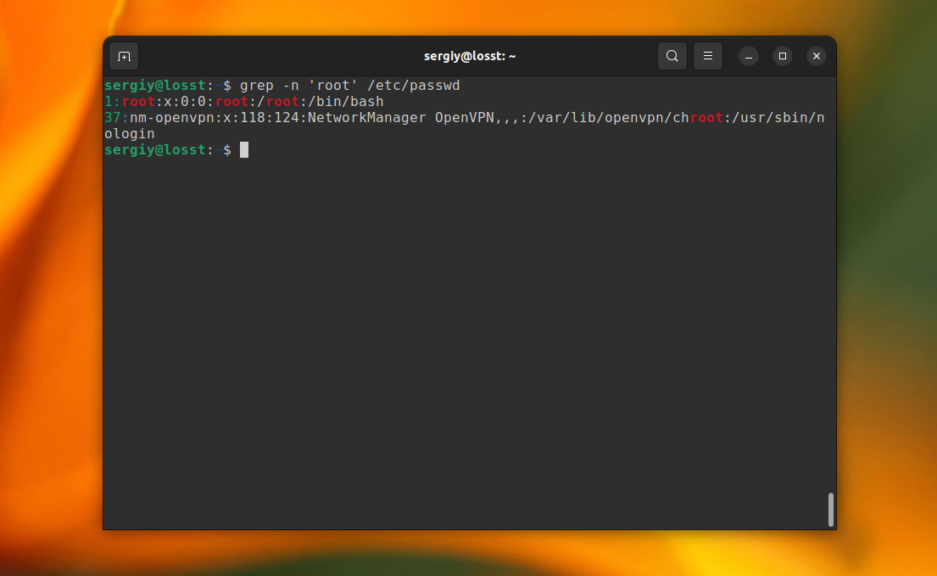
grep -n ‘root’ /etc/passwd
Это всё хорошо работает пока ваш поисковый запрос не содержит специальных символов. Например, если вы попытаетесь найти все строки, которые содержат символ «[» в файле /etc/grub/00_header, то получите ошибку, что это регулярное выражение не верно. Для того чтобы этого избежать, нужно явно указать, что вы хотите искать строку с помощью опции -F:
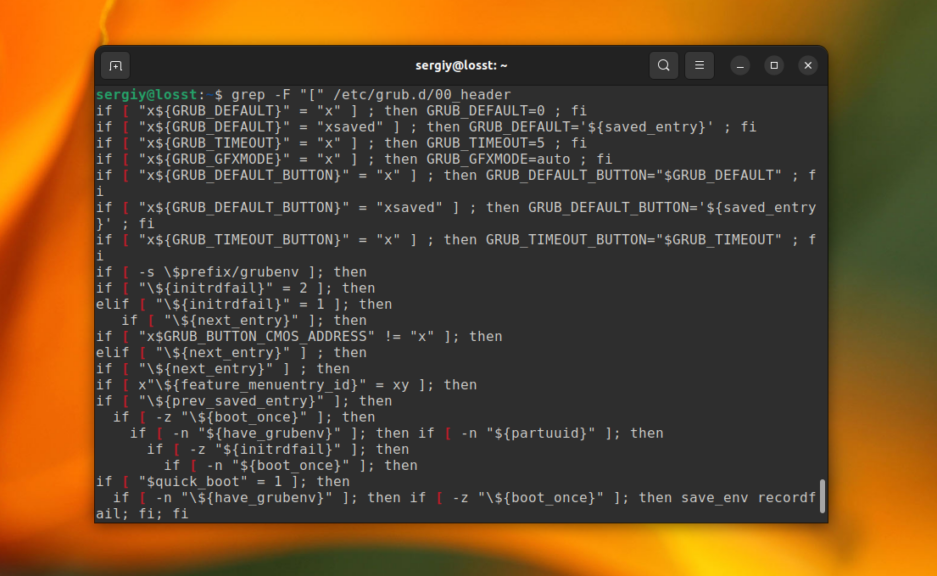
grep -F «[» /etc/grub.d/00_header
Теперь вы знаете как выполняется поиск текста файлах grep.
2. Фильтрация вывода команды
Для того чтобы отфильтровать вывод другой команды с помощью grep достаточно перенаправить его используя оператор |. А файл для самого grep указывать не надо. Например, для того чтобы найти все процессы gnome можно использовать такую команду:
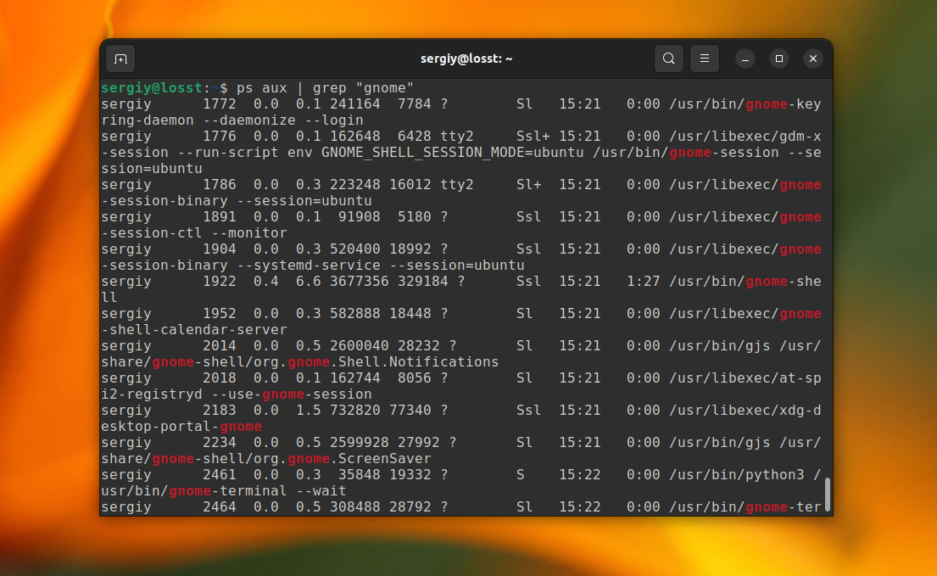
ps aux | grep «gnome»
В остальном всё работает аналогично.
3. Базовые регулярные выражения
Утилита grep поддерживает несколько видов регулярных выражений. Это базовые регулярные выражения (BRE), которые используются по умолчанию и расширенные (ERE). Базовые регулярные выражение поддерживает набор символов, позволяющих описать каждый определённый символ в строке. Это: ., *, [], [^], ^ и $. Например, вы можете найти строки, которые начитаются на букву r:
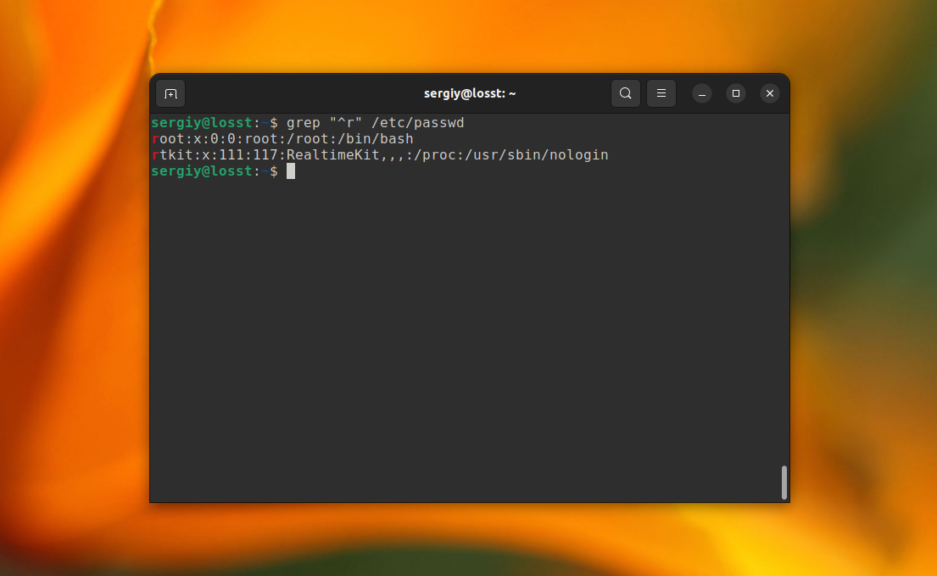
grep «^r» /etc/passwd
Или же строки, которые содержат большие буквы:
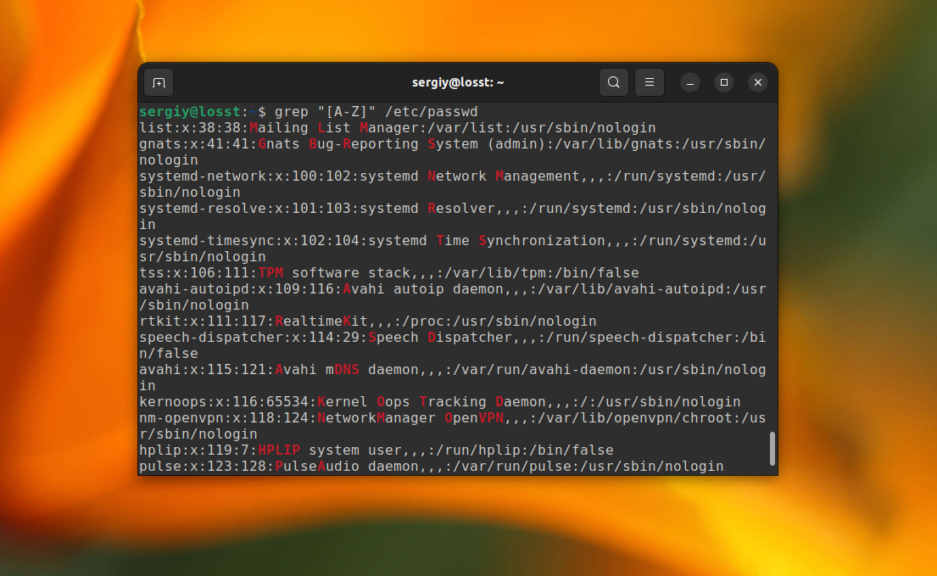
grep «[A-Z]» /etc/passwd
А так можно найти все строки, которые заканчиваются на ready в файле /var/log/dmesg:
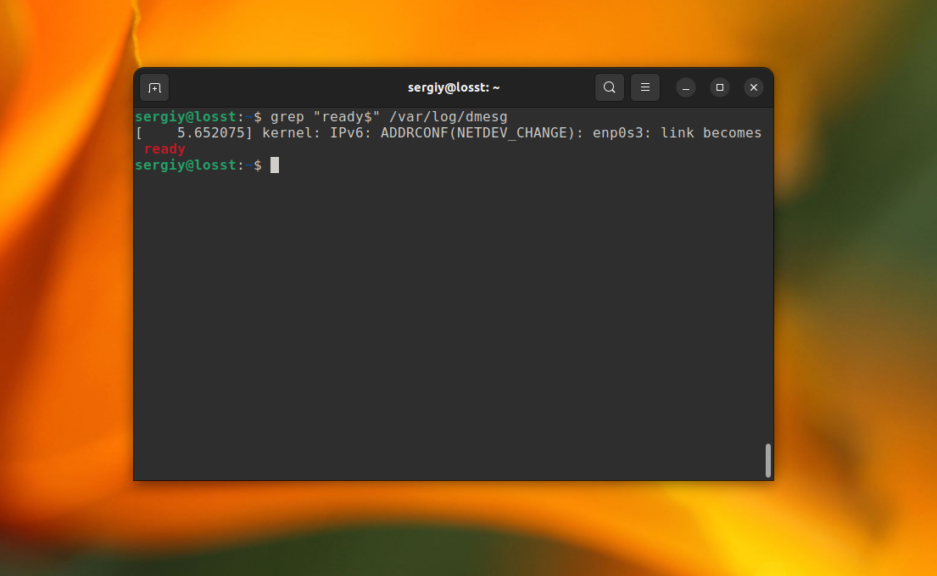
grep «ready$» /var/log/dmesg
Но используя базовый синтаксис вы не можете указать точное количество этих символов.
4. Расширенные регулярные выражения
В дополнение ко всем символам из базового синтаксиса, в расширенном синтаксисе поддерживаются также такие символы:
- + — одно или больше повторений предыдущего символа;
- ? — ноль или одно повторение предыдущего символа;
- — повторение предыдущего символа от n до m раз;
- | — позволяет объединять несколько паттернов.
Для активации расширенного синтаксиса нужно использовать опцию -E. Например, вместо использования опции -e, можно объединить несколько слов для поиска вот так:
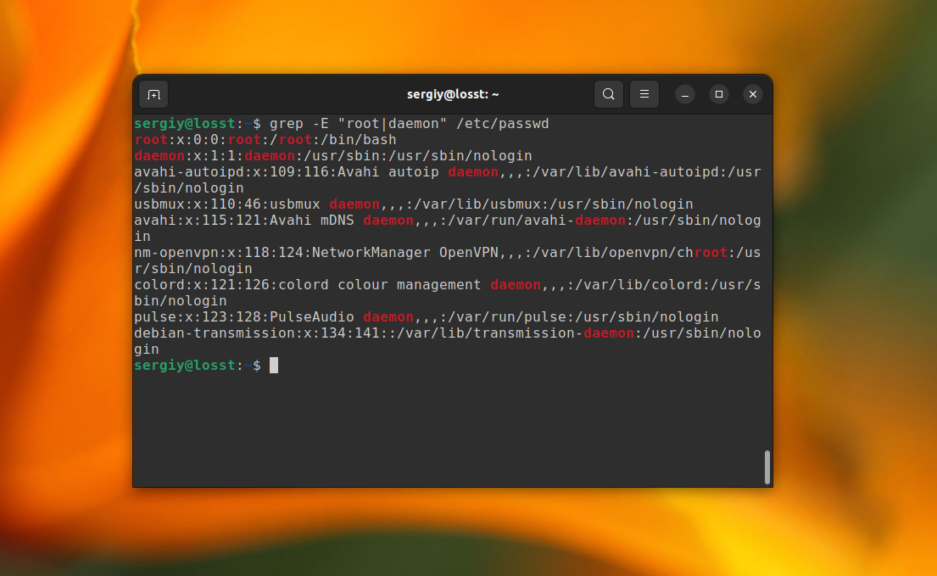
grep -E «root|daemon» /etc/passwd
Вообще, регулярные выражения grep — это очень обширная тема, в этой статье я лишь показал несколько примеров. Как вы увидели, поиск текста в файлах grep становиться ещё эффективнее. Но на полное объяснение этой темы нужна целая статья, поэтому пока пропустим её и пойдем дальше.
5. Вывод контекста
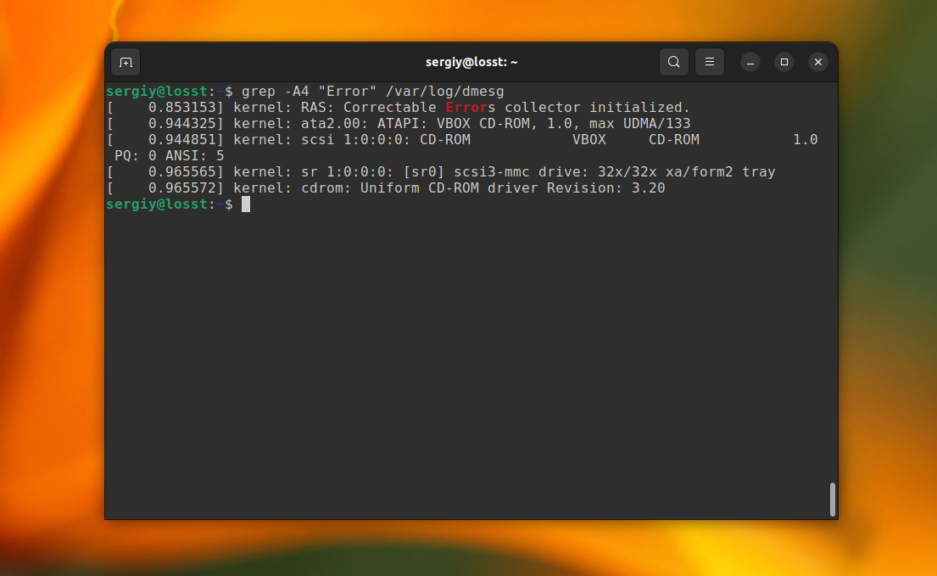
Иногда бывает очень полезно вывести не только саму строку со вхождением, но и строки до и после неё. Например, мы хотим выбрать все ошибки из лог-файла, но знаем, что в следующей строчке после ошибки может содержаться полезная информация, тогда с помощью grep отобразим несколько строк. Ошибки будем искать в /var/log/dmesg по шаблону «Error»:
grep -A4 «Error» /var/log/dmesg
Выведет строку с вхождением и 4 строчки после неё:
grep -B4 «Error» /var/log/dmesg
Эта команда выведет строку со вхождением и 4 строчки до неё. А следующая выведет по две строки с верху и снизу от вхождения.
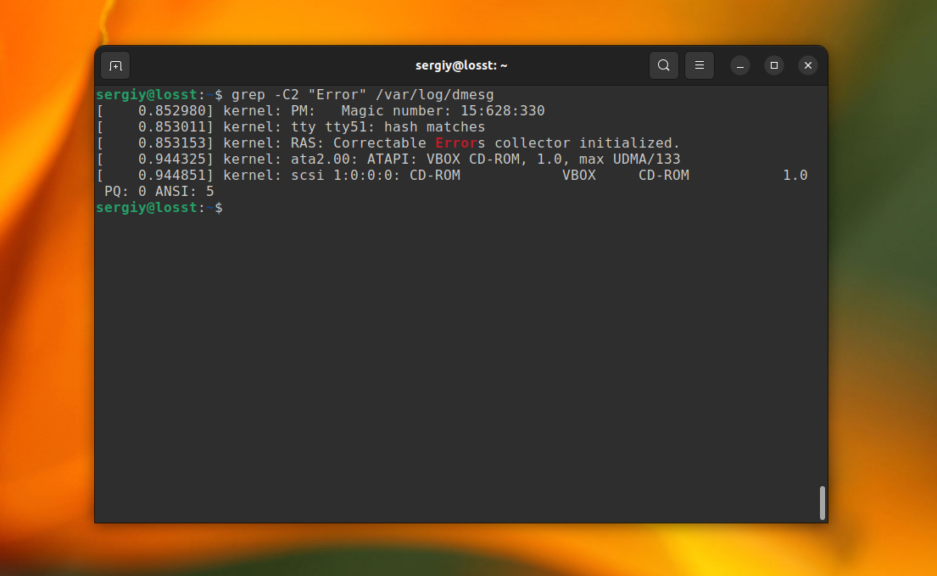
grep -C2 «Error» /var/log/dmesg
6. Рекурсивный поиск в grep
До этого мы рассматривали поиск в определённом файле или выводе команд. Но grep также может выполнить поиск текста в нескольких файлах, размещённых в одном каталоге или подкаталогах. Для этого нужно использовать опцию -r. Например, давайте найдём все файлы, которые содержат строку Kernel в папке /var/log:
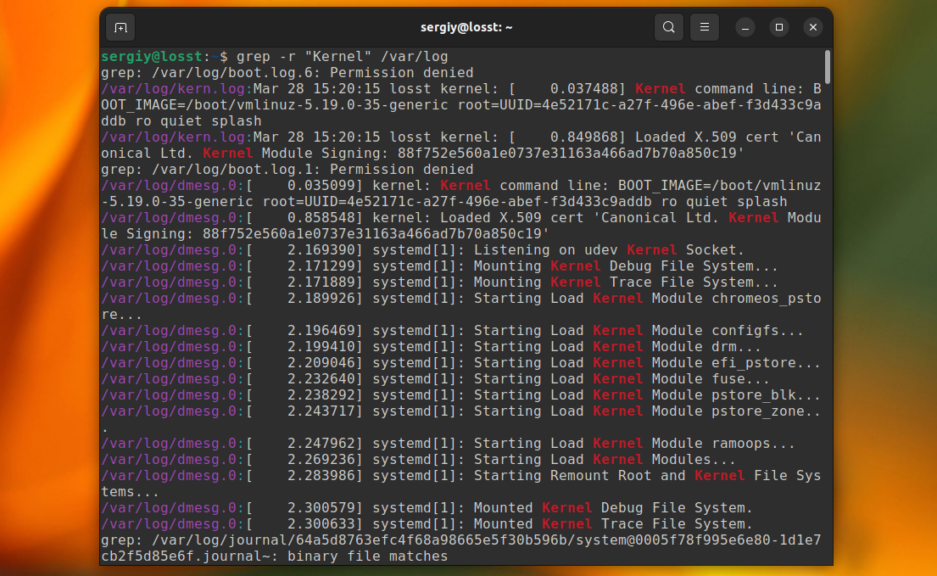
grep -r «Kernel» /var/log
Папка с вашими файлами может содержать двоичные файлы, в которых поиск выполнять обычно не надо. Для того чтобы их пропускать используйте опцию -I:
Некоторые файлы доступны только суперпользователю и для того чтобы выполнять по ним поиск вам нужно запускать grep с помощью sudo. Или же вы можете просто скрыть сообщения об ошибках чтения и пропускать такие файлы с помощью опции -s:
7. Выбор файлов для поиска
С помощью опций —include и —exclude вы можете фильтровать файлы, которые будут принимать участие в поиске. Например, для того чтобы выполнить поиск только по файлам с расширением .log в папке /var/log используйте такую команду:
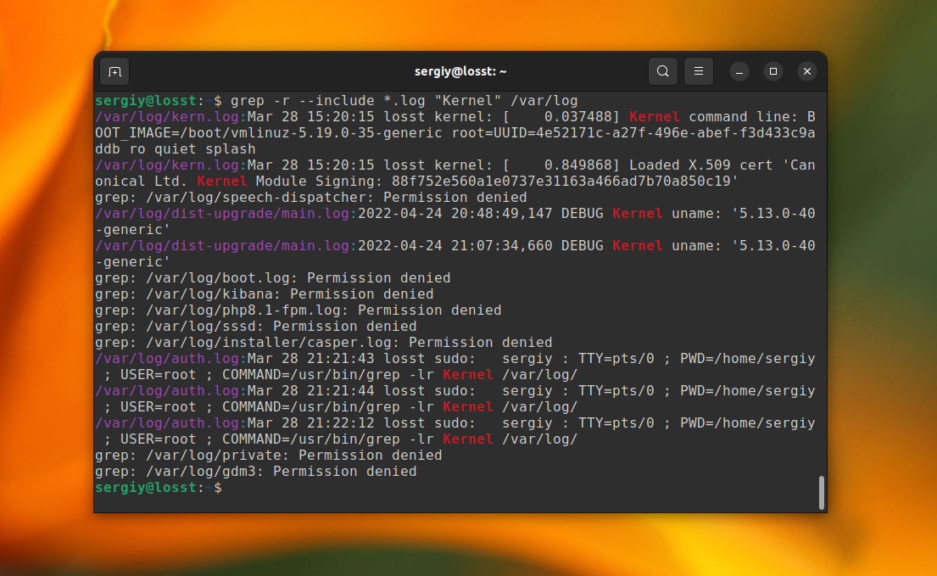
grep -r —include=»*.log» «Kernel» /var/log
А для того чтобы исключить все файлы с расширением .journal надо использовать опцию —exclude:
grep -r —exclude=»*.journal» «Kernel» /var/log
8. Поиск слов в grep
Когда вы ищете строку abc, grep будет выводить также kbabc, abc123, aafrabc32 и тому подобные комбинации. Вы можете заставить утилиту искать по содержимому файлов в Linux строки, которые включают только искомые слова полностью с помощью опции -w. Например:
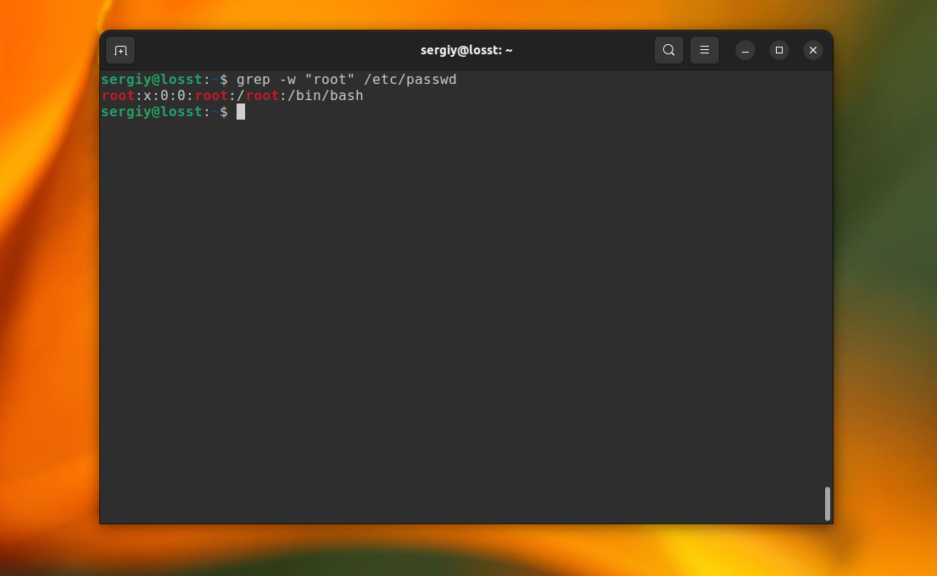
grep -w «root» /etc/passwd
9. Количество строк
Утилита grep может сообщить, сколько строк с определенным текстом было найдено файле. Для этого используется опция -c (счетчик). Например:
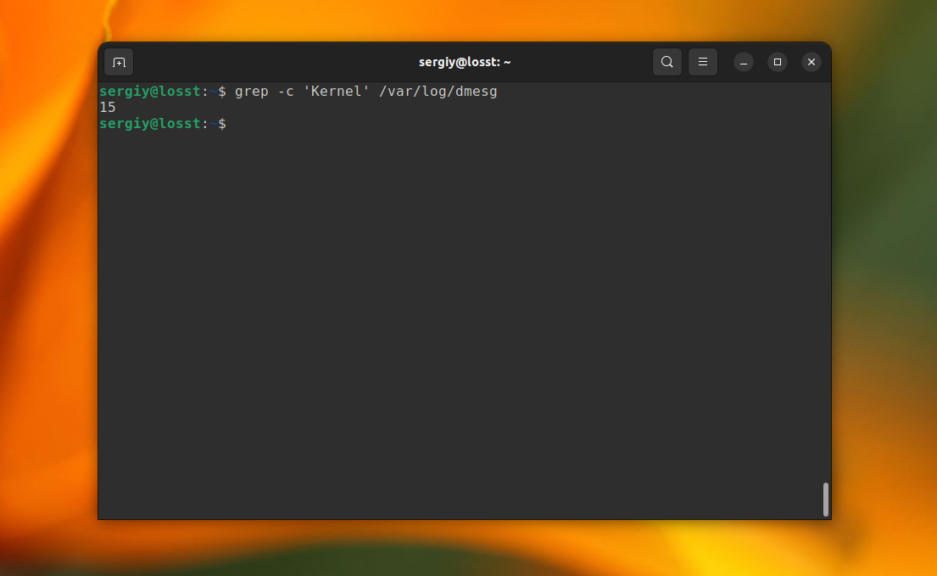
grep -c ‘Kernel’ /var/log/dmesg
10. Инвертированный поиск
Команда grep Linux может быть использована для поиска строк, которые не содержат указанное слово. Например, так можно вывести только те строки, которые не содержат слово nologin:
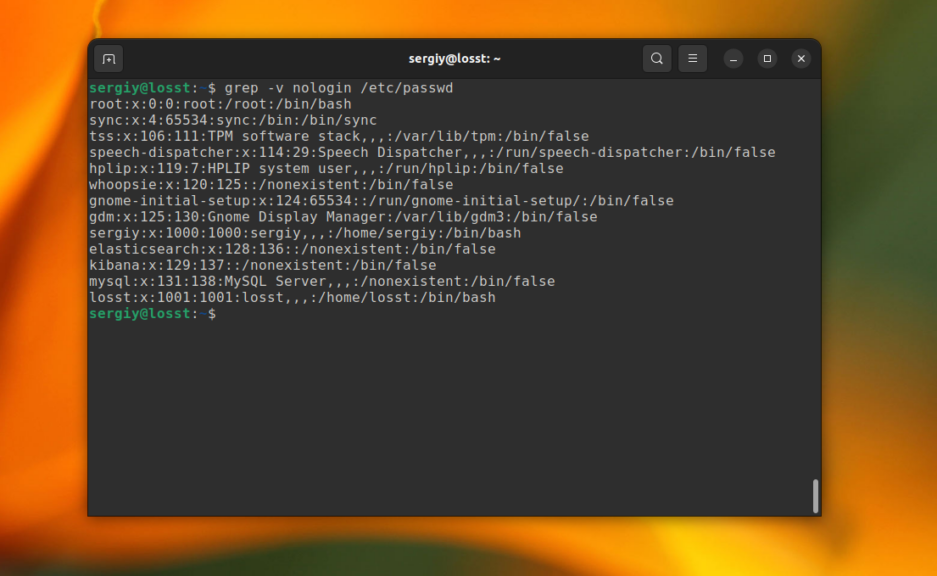
grep -v nologin /etc/passwd
11. Вывод имен файлов
Вы можете указать grep выводить только имена файлов, в которых было хотя бы одно вхождение с помощью опции -l. Например, следующая команда выведет все имена файлов из каталога /var/log, при поиске по содержимому которых было обнаружено вхождение Kernel:
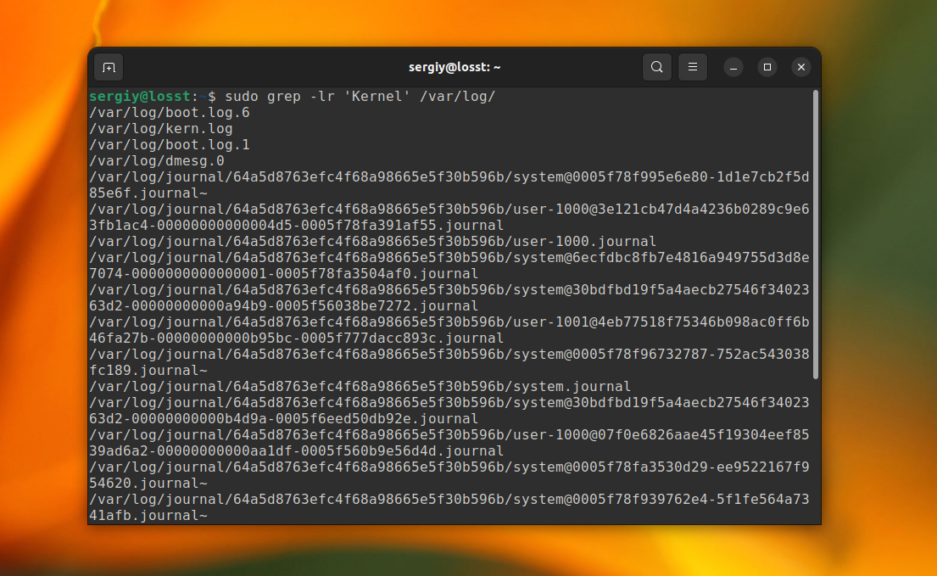
grep -lr ‘Kernel’ /var/log/
12. Цветной вывод
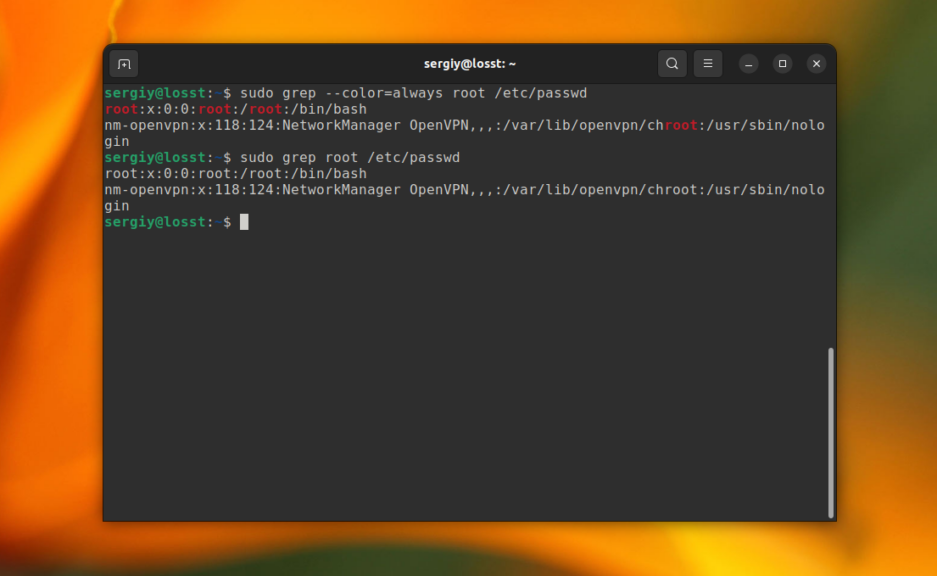
По умолчанию grep не будет подсвечивать совпадения цветом. Но в большинстве дистрибутивов прописан алиас для grep, который это включает. Однако, когда вы используйте команду c sudo это работать не будет. Для включения подсветки вручную используйте опцию —color со значением always:
sudo grep —color=always root /etc/passwd
Выводы
Вот и всё. Теперь вы знаете что представляет из себя команда grep Linux, а также как ею пользоваться для поиска файлов и фильтрации вывода команд. При правильном применении эта утилита станет мощным инструментом в ваших руках. Если у вас остались вопросы, пишите в комментариях!
Обнаружили ошибку в тексте? Сообщите мне об этом. Выделите текст с ошибкой и нажмите Ctrl+Enter.
How to get line number from grep?
I would like to know what line has the following text, I tried adding -n , but it did not work. I tried adding | grep -n * , but it did something weird. What I would like to see (I don’t care about format) is
4 Answers 4
get line number of a pattern!
if you want to get only the line number as output add another grep command to it !
grep -n "pattern" file.txt | grep -Eo '^[^:]+' You should put -e at the end of the options list: grep -rne coll *
To grep a pattern in a specific file, and get the matching lines:
or using cut as suggested by @wjandrea:
grep -n | cut -f1 -d: | sort -u - is a quoted glob pattern (use option -E for regexp);
- is the file you are interested in;
- the first pipe awk . filters the line numbers in the output of grep (before : on each line);
- the second pipe ensures that line numbers only appear once.
#This shows only the line number. #i --> case-insensitive, n --> line number var="APPLE";targetFile="targetFile.txt" numLin=$(grep -in $var $targetFile | cut -d':' -f1); echo $numLine;
You must log in to answer this question.
Related
Hot Network Questions
Subscribe to RSS
To subscribe to this RSS feed, copy and paste this URL into your RSS reader.
Site design / logo © 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA . rev 2023.7.17.43536
Ubuntu and the circle of friends logo are trade marks of Canonical Limited and are used under licence.
By clicking “Accept all cookies”, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy.