- Count all occurrences of a string in lots of files with grep
- 16 Answers 16
- How to count using the grep command in Linux/Unix
- Grep counts the number of lines in the file that contain the specified content
- Grep counts the number of times of the specified content in a file
- Grep count the number of files in the directory whose filename contains the specified keyword
- Grep matches and reverses by line number
- grep two words on the same line
- Grep count the number of non-duplicate lines in a file
- Count the number of lines found by grep
- 2 Answers 2
- Подсчет количества вхождений слова в текстовом файле
- Используем grep | wc
- Используем tr | grep
- Еще один пример
- Заключение
Count all occurrences of a string in lots of files with grep
Can you tell me what the grep -v :0 does ? . I know it counts for files having occurrences greater than 0. What does the -v option and :0 mean ?. Kindly let me know.
@GauthamHonnavara grep :0 looks for line that match the string :0. -v is an option to invert that search so instead using grep -v :0 means find all line that don’t contain :0 so a line with file4:5 and file27:193 all would pass through since they don’t contain :0
16 Answers 16
This works for multiple occurrences per line:
This one shows the relevant files and then the total count of matches: grep -rc test . | awk -F: ‘$NF > 0 END’
This has the same limitation that it counts multiple occurrences on one line only once. I am guessing that this behavior is OK in this case, though.
This doesn’t work if you want to search in subdirectories too, whereas grep -o and wc -l does. cat is quicker in cases like the original question though.
will count multiple occurrences in a line
Instead of using -c, just pipe it to wc -l.
This will list each occurrence on a single line and then count the number of lines.
This will miss instances where the string occurs 2+ times on one line, though.
Piping to «wc -l» works also nicely together with «grep -r ‘test’ .» which scans recursively all files for the string ‘test’ in all directories below the current one.
One of the rare useful applications of cat .
You can add -R to search recursively (and avoid to use cat) and -I to ignore binary files.
grep -c string * | awk 'BEGINEND' Take care if your file names include «:» though.
Something different than all the previous answers:
If you want number of occurrences per file (example for string «tcp»):
grep -RIci "tcp" . | awk -v FS=":" -v OFS="\t" '$2>0 < print $2, $1 >' | sort -hr 53 ./HTTPClient/src/HTTPClient.cpp 21 ./WiFi/src/WiFiSTA.cpp 19 ./WiFi/src/ETH.cpp 13 ./WiFi/src/WiFiAP.cpp 4 ./WiFi/src/WiFiClient.cpp 4 ./HTTPClient/src/HTTPClient.h 3 ./WiFi/src/WiFiGeneric.cpp 2 ./WiFi/examples/WiFiClientBasic/WiFiClientBasic.ino 2 ./WiFiClientSecure/src/ssl_client.cpp 1 ./WiFi/src/WiFiServer.cpp - grep -RIci NEEDLE . — looks for string NEEDLE recursively from current directory (following symlinks), ignoring binaries, counting number of occurrences, ignoring case
- awk . — this command ignores files with zero occurrences and formats lines
- sort -hr — sorts lines in reverse order by numbers in first column
Of course, it works with other grep commands with option -c (count) as well. For example:
grep -c "tcp" *.txt | awk -v FS=":" -v OFS="\t" '$2>0 < print $2, $1 >' | sort -hr The AWK solution which also handles file names including colons:
grep -c string * | sed -r 's/^.*://' | awk 'BEGIN<>END' Keep in mind that this method still does not find multiple occurrences of string on the same line.
You can use a simple grep to capture the number of occurrences effectively. I will use the -i option to make sure STRING/StrING/string get captured properly.
Command line that gives the files’ name:
grep -oci string * | grep -v :0 Command line that removes the file names and prints 0 if there is a file without occurrences:
Could you please elaborate more your answer adding a little more description about the solution you provide?
short recursive variant:
find . -type f -exec cat <> + | grep -c 'string' Grep only solution which I tested with grep for windows:
grep -ro "pattern to find in files" "Directory to recursively search" | grep -c "pattern to find in files" This solution will count all occurrences even if there are multiple on one line. -r recursively searches the directory, -o will «show only the part of a line matching PATTERN» — this is what splits up multiple occurences on a single line and makes grep print each match on a new line; then pipe those newline-separated-results back into grep with -c to count the number of occurrences using the same pattern.
How to count using the grep command in Linux/Unix
Linux grep command is one of the most commonly used command-line tools. We often use it to check the number of times of a words, phrases, strings in a text file or patterns to find the number of occurrences of files with specific names under folders.
Of course, you can also use a pipeline to do your daily work using a combination of grep and other commands. For example, use the grep command and the wc command to count the number of files that contain the specified content.
Suppose you have an test6.txt file containing the sentences:

Grep counts the number of lines in the file that contain the specified content
In the following example, we will use the grep command to count the number of lines in the file test6.txt that contain the string “dfff”

Using grep -c options alone will count the number of lines that contain the matching word instead of the number of total matches.
You can also use the grep command, pipe, and wc command to achieve the same effect as the grep-c option in the following example.

Grep counts the number of times of the specified content in a file
In the following example, we use grep -w to count the number of times of the string “dfff” in the file
➜ grep -o -w "dfff" test6.txt | wc -lOptions:-o, --only-matchingPrints only the matching part of the lines.-w, --word-regexpThe expression is searched for as a word (as if surrounded by `[[::]]'; see re_format(7)).

Grep count the number of files in the directory whose filename contains the specified keyword
In the following example, the grep directory contains files whose filenames contain the keyword “test”, and we use the ls command, pipe, and wc command to count the number of files whose filenames contain the keyword “test” in the directory.

➜ ll | grep -c test OR ➜ ll | grep test | wc -l
In the example above, we can count the number of lines or the total number of occurrences of a keyword in a file.
Sometimes, however, we also need to count the keyword to appear in the file, at the same time, according to the line number in reverse order.
Grep matches and reverses by line number
➜ grep -n -w "dfff" test6.txt | sort -r
➜ grep -w "dfff" test6.txt | sort
grep two words on the same line
Grep matches multiple keywords, which we often use on a daily basis. But matching multiple keywords has two meanings:
* Match file containing keyword1 and containing keyword2 … : AND
* Match file containing keyword1 or containing keyword2 … : OR
In the first example, we use the grep -e option to match the line containing the word “dfff” or “apple” in the file test6.txt.
➜ grep -n -w -e "dfff" -e "apple" test6.txtIn the second example, we used multiple grep commands and pipes to match lines containing both “dfff” and “apple” words in the file test6.txt.
➜ grep -n -w "dfff" test6.txt | grep apple
Grep count the number of non-duplicate lines in a file
Use the grep command to count the number of the same lines in the file?
➜ cat test7.txt| sort| uniq | wc -lCount the number of lines found by grep
I want to know how many instances of a pattern are found by grep while looking recursively through a directory structure. It seems I should be able to pipe the output of grep through something which would count the lines.
2 Answers 2
I was able to put the answer together with help from this question. The program «wc» program counts newlines, words and byte counts. The «-l» option specifies that the number of lines is desired. For my application, the following worked nicely to count the number of instances of «somePattern»:
$grep -r "somePattern" filename | wc -l There’s also grep -c , but it doesn’t exactly do what you require: «Suppress normal output; instead print a count of matching lines for each input file».
grep -rcZ "some_pattern" | awk -F'\0' 'END' This is likely superior in speed compared to wc -l .
It also works for files with newline in name.
worked perfectly, but if you’re still around, would you mind making it better by explaining step by step what was done there?
For grep: -r searches recursively, -Z prints out the output with the filename separated from the number of matching lines with the nul character. For awk: -F ‘\0’ makes the field delimiter the nul character. s+=$NF is the sum of the values of the last field — NF is the number of fields $NF is therefore the last field, and then s is printed when awk runs out of input and the program ends.
Подсчет количества вхождений слова в текстовом файле

Когда вы работаете с текстовым файлом в графическом редакторе, то можно увидеть количество вхождений слова, используя статистику, если она предоставляется редактором или, например, нажать Ctrl+F и увидеть количество найденных вхождений.
Иногда нужно выполнить подсчет вхождений слова или символов в файле, используя командую строку. Рассмотрим, как это можно сделать.
Используем grep | wc
Предположим, что у нас есть файл myfile.txt со следующим содержимым:
Файл, который содержит произвольный текст. По содержимому данного файла мы будем искать вхождения слова текст. Слово текст здесь должно встретиться три раза.Воспользуемся командой grep и найдем вхождение слова « текст » в файле myfile.txt :
grep -o -i текс myfile.txt | wc -lВ результате будет выведено:
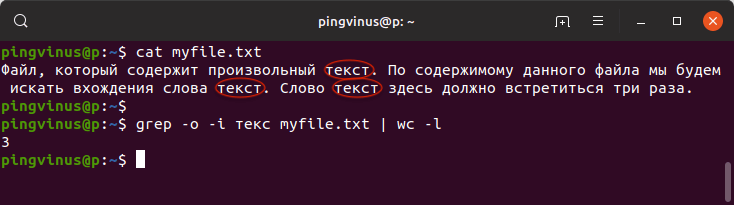
Описание команды:
Команда grep выполняет поиск слова « текст » в файле myfile.txt .
Опция -i — игнорировать регистр символов.
Опция -o — используется, чтобы возвращалось само найденное слово. Каждое найденное слово выводится на отдельной строке (в нашем случае каждое слово передается команде wc ).
Далее вывод команды grep направляется команде wc , так как используется оператор вертикальной черты | (конвейер).
Команда wc (от «word count») с опцией -l выполняет подсчет количества строк. То есть в нашем случае количество, найденных командной grep , слов.
Используем tr | grep
Для разнообразия воспользуемся еще одной командой, которая также выполняет подсчет количества вхождений строки в текстовом файле:
В результате будет выведено:
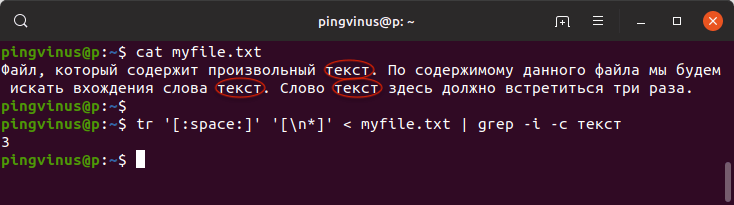
Описание команды:
Мы воспользовались командой tr (от «translate» или «transliterate»), которая используется для преобразования одних символов в другие. В нашем случае мы командной tr разбиваем файл на строки: все пробельные символы ( [:space:] ) заменяются на символ новой строки ( [\n*] ) .
Затем вывод команды tr направляется команде grep , так как используется конвейер |
Опция -c команды grep считает количество строк.
Еще один пример
Обращаю внимание на то, что описанные выше команды, ищут не отдельное слово, а именно вхождение слова (вхождение символов) в тексте. То есть, если в тексте встречается строка вида « Это хорошие помидоры », и мы ищем вхождение слова « помидор », то получим в результате одно вхождение, так как в нашем тексте есть эти символы.
Приведем пример. Выполним поиск в следующем файле:
Еще один файл, в котором будет выполнен поиск слова пингвинус. При выполнении поиска будут учитываться все вхождения последовательности символов "пингвинус", например, пингвинусу, Пингвинуса, Пингвинус.ру.grep -o -i пингвинус myfile2.txt | wc -lВ результате будет выведено:
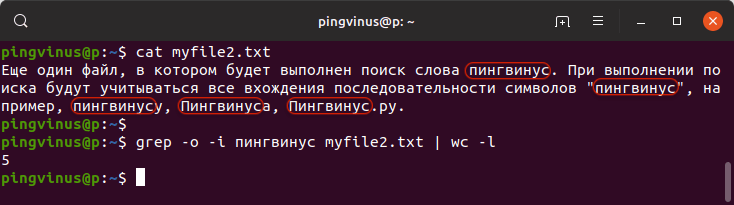
В результате будет выведено:
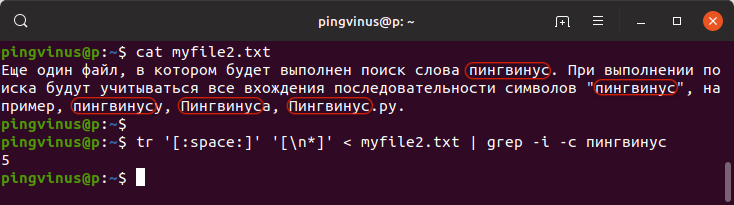
Заключение
Мы рассмотрели, как можно посчитать количество вхождений определенных символов в текстовом файле, используя командую строку. Вы также познакомились с некоторыми возможностями команд grep , wc и tr , и перенаправлением результата одной команды на вход другой — конвейером |