- Как игнорировать пустые строки в Grep? — Подсказка по Linux
- Синтаксис
- Предварительное условие
- Используя [: blank:] ключевое слово
- Используя [: space:]
- Используя ^ #
- Используя ^ $
- Вывод
- grep
- Основные команды grep
- Вывести все упоминания слова
- Вывести всё, что начинается со слова
- Вывести всё, что заканчивается на определённый набор символов
- Найти слова по первым и последним буквам
- Несколько символов подряд
- Поиск из вывода функции
- Поиск из вывода функции по нескольким словам
- Сколько раз слово использовано в тексте
- Найти пустые/не пустые строки
- grep -E
- grep -n
- grep -m
- Логические операторы
Как игнорировать пустые строки в Grep? — Подсказка по Linux
Grep означает Печать глобального регулярного выражения. Он имеет множество функций, например, поиск в файле, поиск только по именам файла, рекурсивный поиск grep и т. Д. Grep считается мощной командой в поисковом секторе. Во многих случаях мы сталкиваемся с ситуациями, когда нам не нужны пробелы или необходимо удалить нежелательные пробелы в наших данных. Один из наиболее интересных способов использования grep — игнорировать или удалять пустые строки из текстового файла. Эта процедура выполняется на разных примерах. Это операция редактирования файла. Для достижения этой цели нам необходимо иметь существующие файлы в нашей системе. С помощью команды grep мы разрешаем ему печатать данные без пустых строк.
Синтаксис
После использования grep возникает закономерность. Шаблон подразумевает то, как мы хотим использовать его для удаления лишнего места в данных. После шаблона описывается имя файла, через которое выполняется шаблон.
Предварительное условие
Чтобы понять полезность grep, нам нужно, чтобы в нашей системе был установлен Ubuntu. Предоставьте сведения о пользователе, указав имя пользователя и пароль для доступа к приложениям Linux. После входа в систему откройте приложение и найдите терминал или нажмите сочетание клавиш ctrl + alt + T.
Используя [: blank:] ключевое слово
Предположим, у нас есть файл с именем bfile с текстовым расширением. Вы можете создать файл либо в текстовом редакторе, либо с помощью командной строки в терминале. Чтобы создать файл на терминале, включая следующие команды.
$ Echo «вводимый текст в а файл ” > filename.txt
Нет необходимости создавать файл, если он уже существует. Просто отобразите его, используя добавленную команду:
Текст, записанный в этих файлах, содержит пробелы между ними, как показано на рисунке ниже.
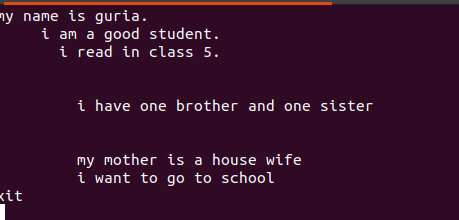
Эти пустые строки можно удалить, используя пустую команду, чтобы игнорировать пустые пробелы между словами или строками.
$ egrep ‘^ [ [ :пустой ] ] * [ ^ [ :пустой: ] #] ’Bfile.txt
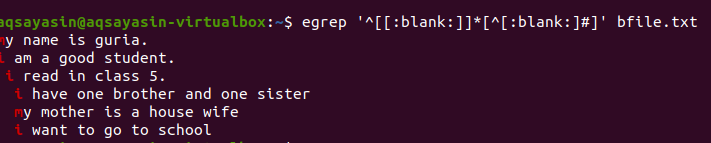
После применения запроса пробелы между строками будут удалены, и вывод больше не будет содержать лишних пробелов. Первое слово выделяется, поскольку пробелы между последним словом строки и между первыми словами следующей строки удаляются. Мы также можем применить условия к той же команде grep, добавив эту пустую функцию, чтобы удалить ненужное пространство в выводе.
Используя [: space:]
Здесь объясняется еще один пример игнорирования пробела.
Не говоря уже о расширении файла, мы сначала отобразим существующий файл с помощью команды.
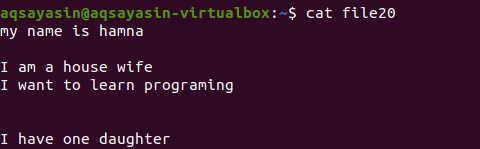
Давайте посмотрим, как удаляется лишнее пространство с помощью команды grep помимо ключевого слова [: space:]. Параметр –v в Grep поможет напечатать строки без пустых строк и лишних интервалов, которые также включены в форму абзаца.
$ grep –V ‘^ [ [ ;пространство: ] ] * $ ’File20
Вы увидите, что лишние строки удаляются, а вывод идет в упорядоченном виде по строкам. Вот почему методология grep –v так помогает в достижении требуемой цели.

Упоминание расширений файлов ограничивает функциональность grep для работы только с определенными расширениями файлов, то есть .text или .mp3. Выполняя выравнивание текстового файла, мы возьмем fileg.txt в качестве образца файла. Сначала мы отобразим присутствующий в нем текст с помощью функции $ cat. Результат следующий:
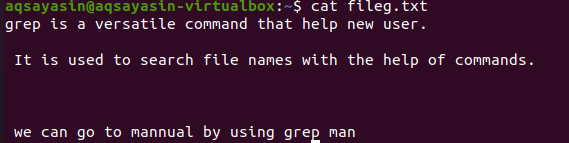
Применив команду, мы получили наш выходной файл. Здесь мы можем видеть данные без интервала между строками, которые записываются последовательно.
$ grep –V ‘^ [ [ :пространство: ] ] * $ ’Fileg.txt

Помимо длинных команд, мы также можем использовать короткие письменные команды в Linux и Unix для реализации grep, поддерживающего в нем сокращенные символы.
Мы видели, как получается результат, применяя команды из входа. Здесь мы узнаем, как ввод сохраняется на выходе.
$ grep ‘\ S’ filename.txt > tmp.txt && мв tmp.txt имя_файла.txt
Здесь мы будем использовать временный текстовый файл с расширением текста с именем tmp.
Используя ^ #
Как и в других описанных примерах, мы применим команду к текстовому файлу с помощью команды cat. Мы также можем отображать текст с помощью команды echo.
Текстовый файл состоит из 4 строк, между которыми есть пробелы. Эти пробелы легко удаляются с помощью определенной команды.
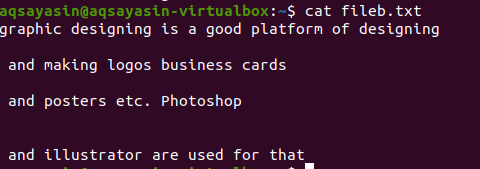
Регулярные расширенные операции включаются параметром –E, который разрешает все регулярные выражения, особенно pipe. Канал используется как необязательное условие «или» в любом шаблоне. «^ #». Это показывает соответствие текстовых строк в файле, который начинается со знака #. «^ $» Будет соответствовать всем свободным пробелам в тексте или пустым строкам.
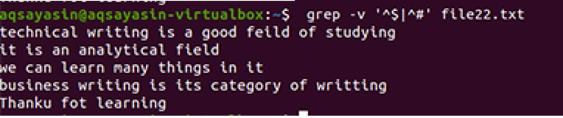
Вывод показывает полное удаление лишнего пробела между строками в файле данных. В этом примере мы видели, что в команде сначала идет «^ #», что означает, что текст сопоставляется первым. «^ $» Идет после | оператор, поэтому свободное пространство будет сопоставлено позже.
Используя ^ $
Как и в примере, упомянутом выше, мы получим те же результаты, потому что команда почти такая же. Однако картина написана наоборот. File22.txt — это файл, который мы собираемся использовать для удаления пробелов.
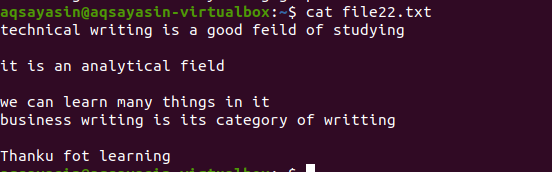
Применяется та же методика, за исключением приоритетной работы. В соответствии с этой командой сначала будут сопоставлены свободные места, затем сопоставлены текстовые файлы. На выходе вы получите последовательность строк, удалив в них лишние пробелы.
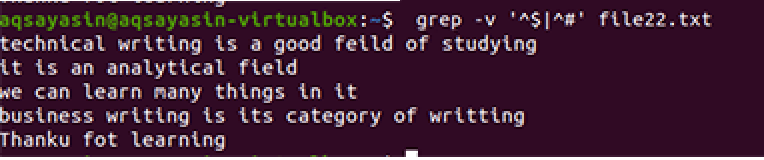
Другие простые команды
Они оба настолько просты и помогают устранить пробелы в текстовых строках.
Вывод
Удаление бесполезных пробелов в файлах с помощью регулярных выражений — довольно простой способ добиться плавной последовательности данных и поддерживать согласованность. Примеры подробно объяснены, чтобы улучшить вашу информацию по теме.
grep

-v, —invert-match
Invert the sense of matching, to select non-matching lines.
По умолчанию я предполагаю, что Вы работаете в Bash под Windows 10 или в Bash в Linux .
Основные команды grep
Вывести все упоминания слова
Предположим вы запустили CentOS Linux и хотите посмотреть все установленные пакеты в названии которых есть слово kernel
yum list installed | grep kernel
abrt-addon-kerneloops.x86_64 2.1.11-60.el7.centos @base kernel.x86_64 3.10.0-1160.el7 @anaconda kernel.x86_64 3.10.0-1160.2.2.el7 @updates kernel.x86_64 3.10.0-1160.6.1.el7 @updates kernel-devel.x86_64 3.10.0-1160.2.2.el7 @updates kernel-devel.x86_64 3.10.0-1160.6.1.el7 @updates kernel-headers.x86_64 3.10.0-1160.6.1.el7 @updates kernel-tools.x86_64 3.10.0-1160.6.1.el7 @updates kernel-tools-libs.x86_64 3.10.0-1160.6.1.el7 @updates
И наоборот, можно посмотреть все строки где нет слова kernel : нужно добавить опцию -v
yum list installed | grep -v kernel
Если вам нужно найти что-то в файле, можно вместо | воспользоваться выражением
grep образец путь_до_файла
# Use public server s from the pool.ntp.org project. server 0.centos.pool.ntp.org iburst server 1.centos.pool.ntp.org iburst server 2.centos.pool.ntp.org iburst server 3.centos.pool.ntp.org iburst #broadcast 192.168.1.255 autokey # broadcast server #broadcast 224.0.1.1 autokey # multicast server #manycast server 239.255.254.254 # manycast server
grep ‘ \b kernel \b ‘ huge_file
Где \b это word boundary — границы слова
huge_file это имя файла в текущей директории в котором мы ищем отдельные слова kernel.
То есть слова akernel или kernelz найдены не будут
Вывести всё, что начинается со слова
Если нам теперь не нужны пакеты, в которых слово kernel в середине, а только те, которые начинаются с kernel добавим перед словом знак ^
yum list installed | grep ^kernel
kernel.x86_64 3.10.0-1160.el7 @anaconda kernel.x86_64 3.10.0-1160.2.2.el7 @updates kernel.x86_64 3.10.0-1160.6.1.el7 @updates kernel-devel.x86_64 3.10.0-1160.2.2.el7 @updates kernel-devel.x86_64 3.10.0-1160.6.1.el7 @updates kernel-headers.x86_64 3.10.0-1160.6.1.el7 @updates kernel-tools.x86_64 3.10.0-1160.6.1.el7 @updates kernel-tools-libs.x86_64 3.10.0-1160.6.1.el7 @updates
Вывести всё, что заканчивается на определённый набор символов
Для работы со следующими примерами установите words
sudo yum -y install words
cp /usr/share/dict/words huge_file
… Cynoscion cytodifferentiation Czechization dactylion Daedalion …
Найти слова по первым и последним буквам
Допустим вы знаете только начало и конец слова
… handed hanged hanked hanted happed harked …
Несколько символов подряд
Найти слова с пятью гласными подряд
grep -E ‘[aeiou]’ /usr/share/dict/words
cadiueio Chaouia cooeeing euouae Guauaenok miaoued miaouing Pauiie queueing
Поиск из вывода функции
Нужно сперва вызвать функцию со всеми флагами, затем поставить pipe и сделать grep
Например из файла today.log можно выделить все строки с ошибками
Поиск из вывода функции по нескольким словам
Например, нужно из top выцепить сразу несколько процессов:
top | grep ‘process1\|process2\|process3’
Сколько раз слово использовано в тексте
Начнём с простого примера: слово встречается в строке только один раз.
Например, лог работы сервера содериж строки вида
2023-07-15-07-07-40-ERROR: Something is NOK
Нужно вычислить сколько ошибок зафиксированно в лог файле 2023-07-15-log.txt
grep -o -i ERROR 2023-07-15-log.txt | wc -l
Если вы хотите использовать эту команду в скрипте — рекомендую статью Вывод команды в переменную в bash скрипте
Найти пустые/не пустые строки
Найти все пустые строки в файле ntp.conf
Найти все не пустые строки в файле ntp.conf
grep -E
С некоторыми задачами обычный grep не справляется, поэтому нужен расширеный режим.
Найти в файле file все foobar или foo bar с ровно одним пробелом
Найти в файле file все foobar или foo bar с ровно двумя пробелами
Более сложный пример. Сотрудникам TopBicycle нужно понять у каких велосипедов в списке отсутствует или неправильно записан порядковый номер.
Номер должен быть в формате 111-11-1111 то есть три цифры дефис две цифры дефис четыре цифры
Merida,BigNine,,
Stark,Cobra,xxx-xx-xxx
Forward,Tracer,1234-0
Helkama,Jopo,,
Stels,Pilot,111-22-3333
Author,Grand,444-55-6666
Stels,Pilot21,111-22-3344
Giant,Lannister,555-66-7777
grep -n
Флаг -n показывает номера строк.
Рассмотрим файл partners.csv со списком сайтов
Если выполнить поиск по какому-то слову без флагов, например
cat partners.csv | grep Hosting
Получим строки без номеров
Теперь то же самое но с -n
cat partners.csv | grep -n Hosting
Слева появились номера строк
grep -m
Флаг -m задает верхний предел по количеству
Если вам нужны не все результаты а только один — используйте
Рассмотрим файл partners.csv со списком сайтов
URN.SU;https://urn.su; IT ETH1.RU;https://eth1.ru; IT Aredel.com;https://aredel.com; IT DevhOps.ru;https://devhops.ru; IT
Если нужно только два первых результата
URN.SU;https://urn.su; IT ETH1.RU;https://eth1.ru; IT
Логические операторы
Задача: показать только сегодняшние ERROR и WARNING строки из лога а также те, где присутствует слово panic
Для этого пригодится условие ИЛИ, которое можно использовать в расширенном режиме.
grep ‘2023-07-15’ topbicycle.log | grep -E ‘ERROR|WARNING|*panic*’