- Match exact word using grep
- 4 Answers 4
- Примеры команды grep в Linux
- Используем команду grep в Linux
- Подготовительные работы
- Стандартный поиск по содержимому
- Поиск с захватом строк
- Поиск ключевых слов в начале и в конце строк
- Поиск чисел
- Анализ всех файлов директории
- Точный поиск по словам
- Поиск строк без определенного слова
- Match exact string using grep
- 5 Answers 5
Match exact word using grep
I have a requirement to search for an exact word and print a line. It is working if I don’t have any . (dots) in the line.
$cat file test1 ALL=ALL w.test1 ALL=ALL $grep -w test1 file test1 ALL=ALL w.test1 ALL=ALL Should it be grep -e ‘(^| )test1( |$)’ file , perhaps? I’m a bit confused by what you meant by ‘exact word’ here; because, yes, w.test is matched by ‘[[:<:]]test1[[:>:]]’ pattern.
4 Answers 4
This states that anything that starts with the word test1 as the first line. Now this does not work if you need to fin this in the middle of line but you werent very specific on this. At least in the example given the ^ will work.
Thanks that logic works and if the word is a starting word of the line. Is there any option if the words are in middle of the line which we are searching for.
This grep would also match words only starting with test1. e.g. test12. In any case, raina77ow’s comment is the complete regex for matching a word at the beginning, middle or end of a file. grep -e ‘(^| )test1( |$)’ file
For your sample you can specify the beginning of the line with a ^ and the space with \s in the regular expression
It depends on what other delimiters you might need to match as well.
I know I’m a bit late but I found this question and thought of answering. A word is defined as a sequence of characters and separated by whitespaces. so I think this will work grep -E ‘ +test1|^test1’ file
this searches for lines which begin with test1 or lines which have test preceded by at least one whitespace. sorry I could find a better way if someone can please correct me 🙂
You can take below as sample test file.
$cat /tmp/file test1 ALL=ALL abc test1 ALL=ALL test1 ALL=ALL w.test1 ALL=ALL testing w.test1 ALL=ALL Run below regular expression to search a word starting with test1 and a line that has a word test1 in between of line also.
$ grep -E '(^|\s+)test1\b' /tmp/file test1 ALL=ALL abc test1 ALL=ALL test1 ALL=ALL Примеры команды grep в Linux

Иногда пользователи сталкиваются с необходимостью осуществления поиска определенной информации внутри каких-либо файлов. Часто конфигурационные документы или другие объемные данные вмещают в себе большое количество строк, поэтому вручную отыскать нужные данные не получается. Тогда на помощь приходит одна из встроенных команд в операционные системы на Linux, которая позволит выполнить нахождение строк буквально за считанные секунды.
Используем команду grep в Linux
Что касается различий между дистрибутивами Линукс, в этом случае они не играют никакой роли, поскольку интересующая вас команда grep по умолчанию доступна в большинстве сборок и применяется абсолютно одинаково. Сегодня мы бы хотели обсудить не только действие grep, но и разобрать основные аргументы, которые позволяют значительно упростить процедуру поиска.
Подготовительные работы
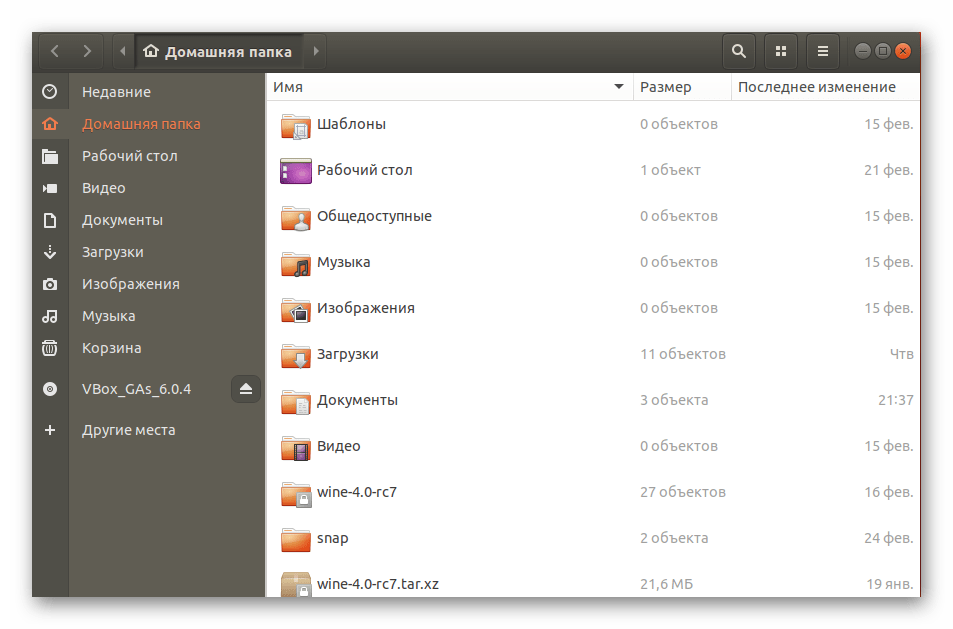
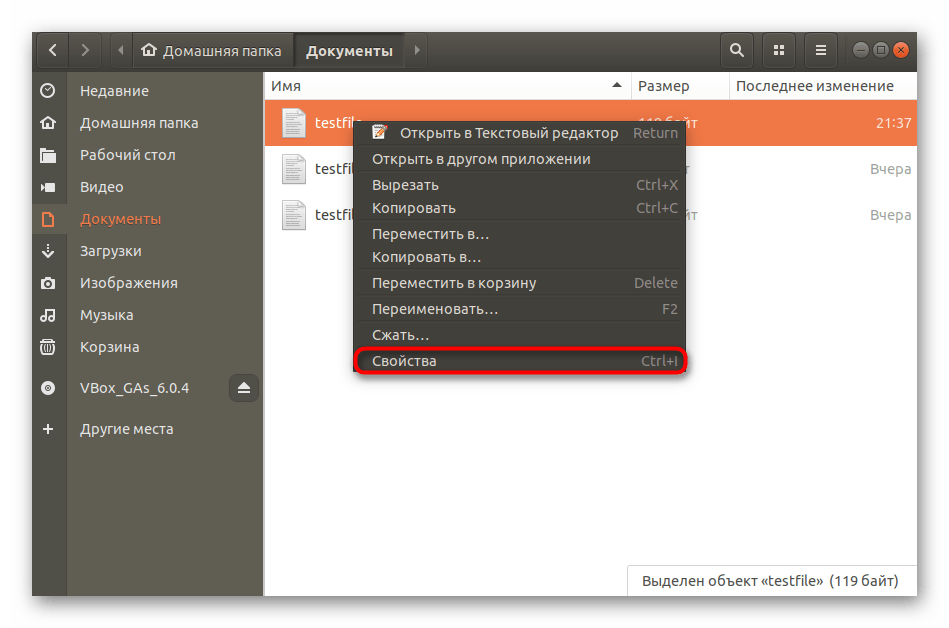
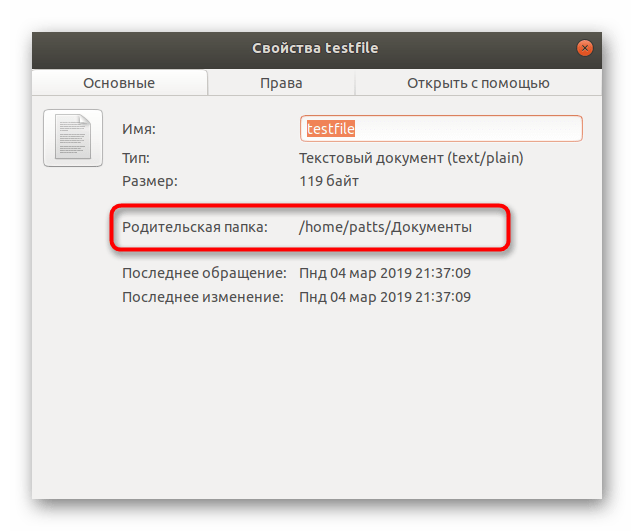
Все дальнейшие действия будут производиться через стандартную консоль, она же позволяет открывать файлы только путем указания полного пути к ним либо если «Терминал» запущен из необходимой директории. Узнать родительскую папку файла и перейти к ней в консоли можно так:
- Запустите файловый менеджер и переместитесь в нужную папку.

- Нажмите правой кнопкой мыши на требуемом файле и выберите пункт «Свойства».

Задействуйте команду cat + название файла , если хотите просмотреть полное содержимое. Детальные инструкции по работе с этой командой ищите в другой нашей статье по ссылке ниже.
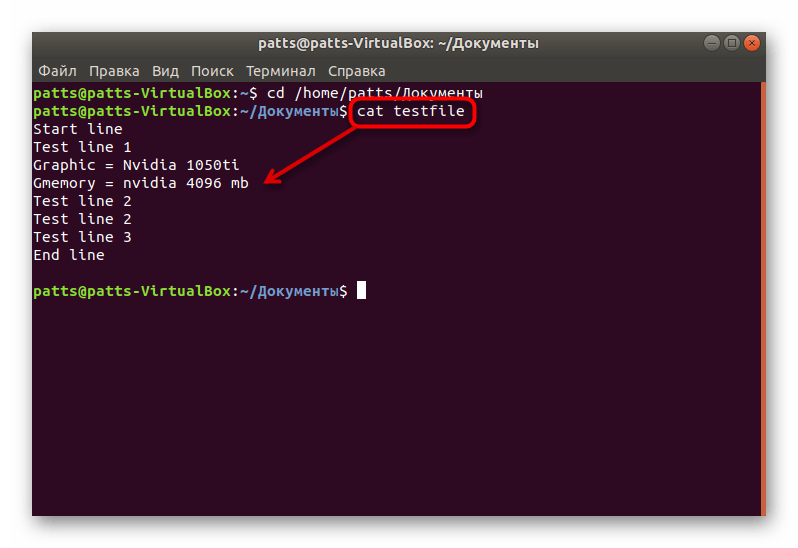
Благодаря выполнению приведенных выше действий вы можете использовать grep, находясь в нужной директории, без указания полного пути к файлу.
Стандартный поиск по содержимому
Прежде чем переходить к рассмотрению всех доступных аргументов, важно отметить и обычный поиск по содержимому. Он будет полезен в тех моментах, когда необходимо найти простое совпадение по значению и вывести на экран все подходящие строки.
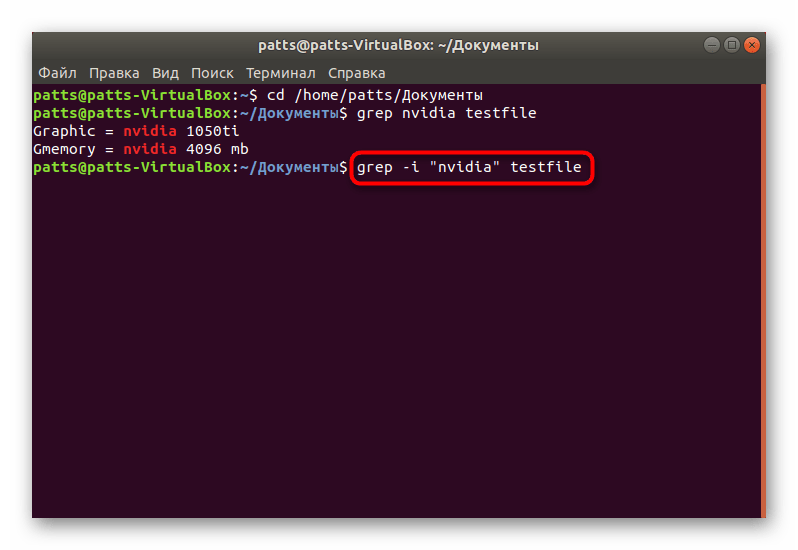
- В командной строке введите grep word testfile , где word — искомая информация, а testfile — название файла. Когда производите поиск, находясь за пределами папки, укажите полный путь по примеру /home/user/folder/filename . После ввода команды нажмите на клавишу Enter.

- Осталось только ознакомиться с доступными вариантами. На экране отобразятся полные строки, а ключевые значения будут выделены красным цветом.

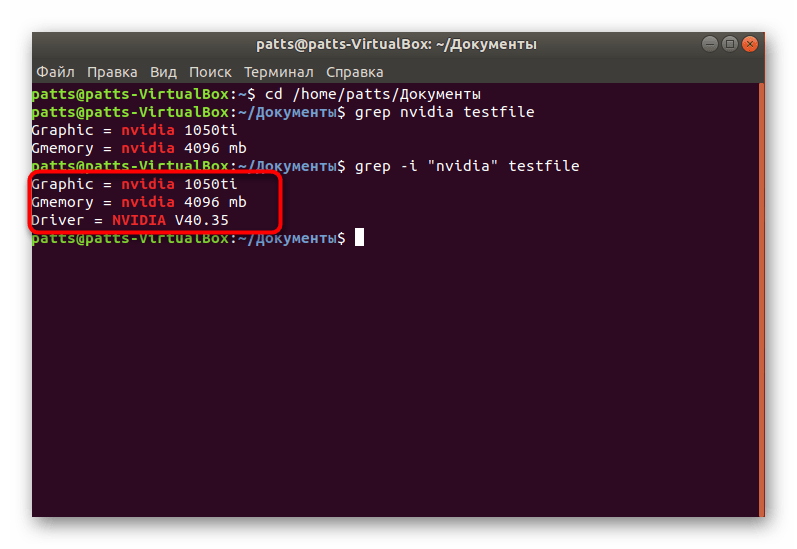
- Важно учитывать и регистр букв, поскольку кодировка Linux не оптимизирована для поиска без учета больших или маленьких символов. Если вы хотите обойти определение регистра, впишите grep -i «word» testfile .

- Как видите, на следующем скриншоте результат изменился и добавилась еще одна новая строка.

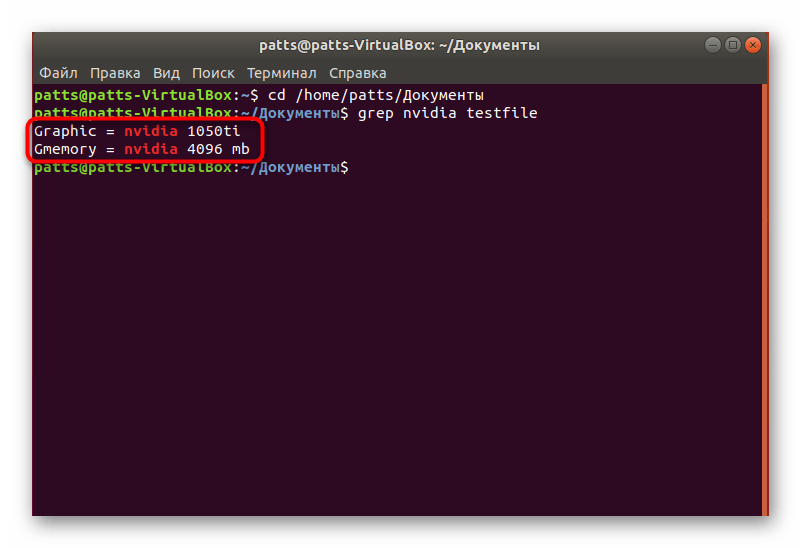
Поиск с захватом строк
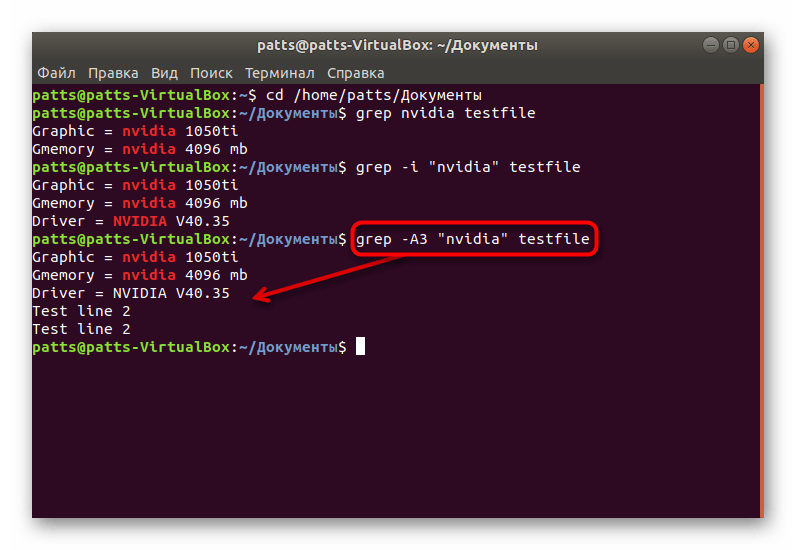
Иногда пользователям необходимо найти не только точное совпадение по строкам, но и узнать информацию, которая идет после них, например, при отчете об определенной ошибке. Тогда правильным решением будет применить атрибуты. Впишите в консоль grep -A3 «word» testfile , чтобы включить в результат и три следующие строки после совпадения. Вы можете написать -A4 , тогда будут захвачены четыре строки, ограничений никаких не имеется.
Если вместо -A вы примените аргумент -B + количество строк , в результате отобразятся данные, находящиеся до точки вхождения.
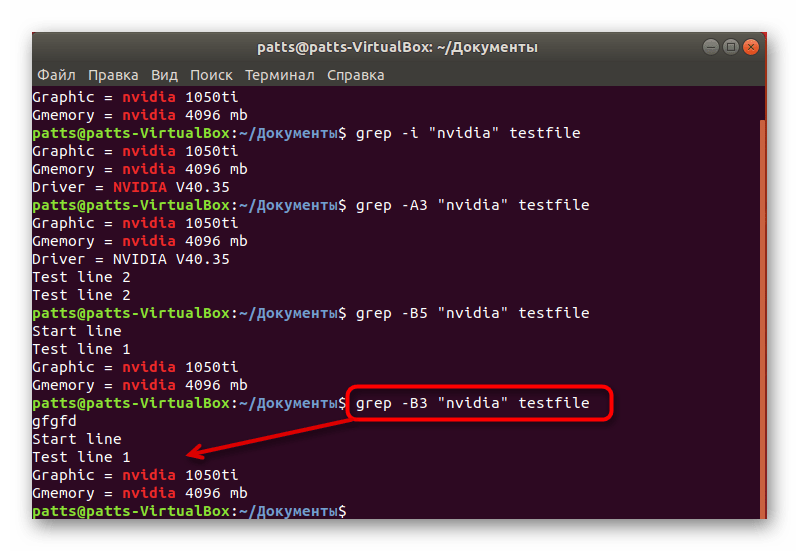
Аргумент -С , в свою очередь, захватывает строки вокруг ключевого слова.
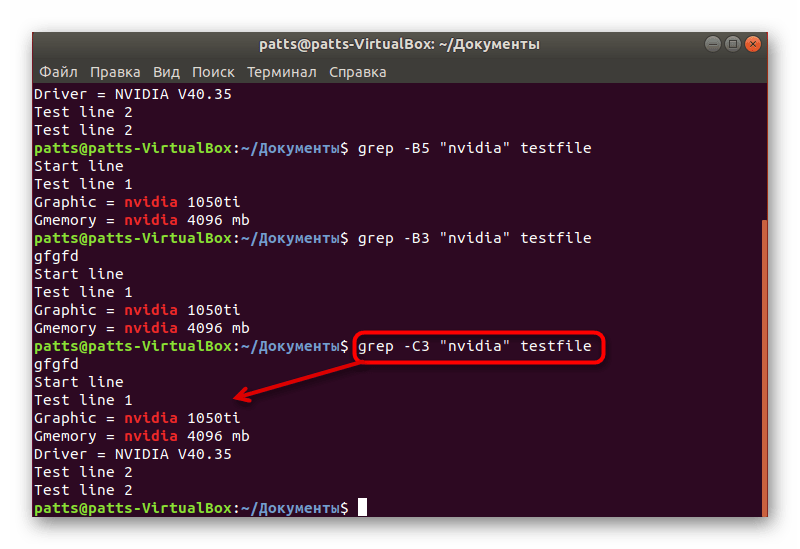
Ниже вы можете увидеть примеры присваивания указанных аргументов. Обратите внимание, что обязательно нужно учитывать регистр и проставлять двойные кавычки.
grep -B3 «word» testfile
grep -C3 «word» testfile
Поиск ключевых слов в начале и в конце строк
Надобность определения ключевого слова, которое стоит в начале или в конце строки, чаще всего возникает во время работы с конфигурационными файлами, где каждая линия отвечает за один параметр. Для того чтобы увидеть точное вхождение в начале, необходимо прописать grep «^word» testfile . Знак ^ как раз и отвечает за применение этой опции.
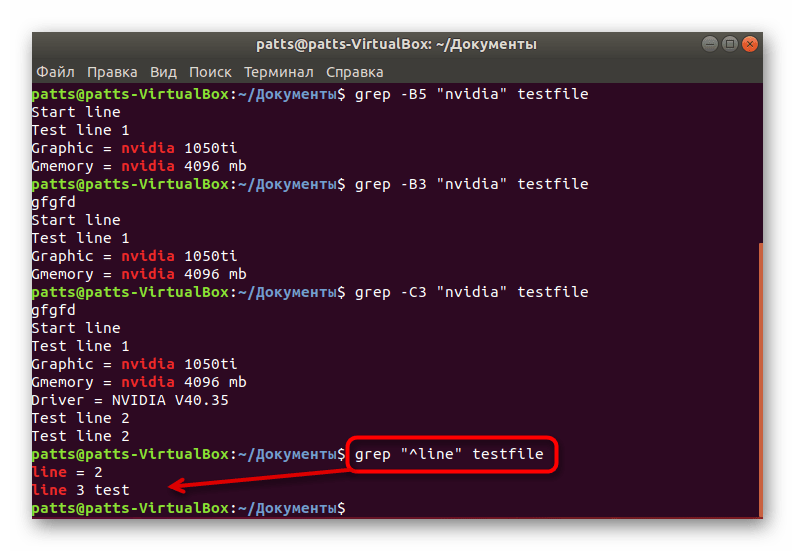
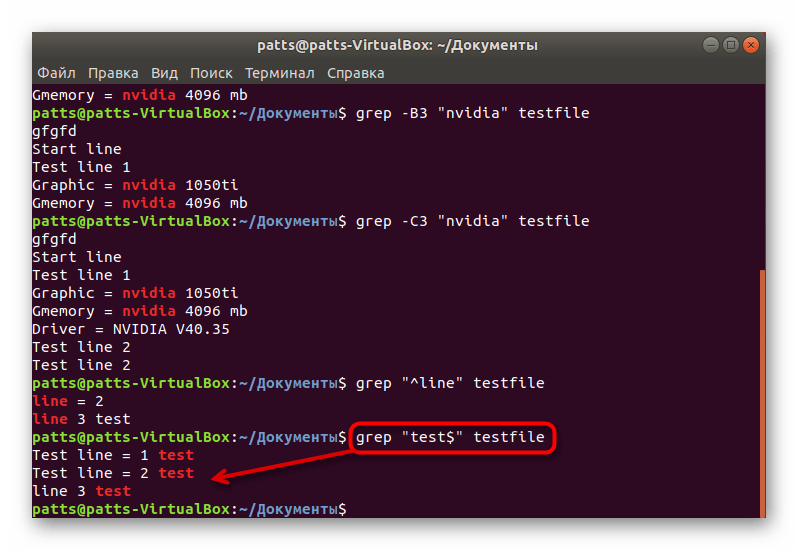
Поиск содержимого в конце строк происходит примерно по такому же принципу, только в кавычках следует добавить знак $, и команда обретет такой вид: grep «word$» testfile .
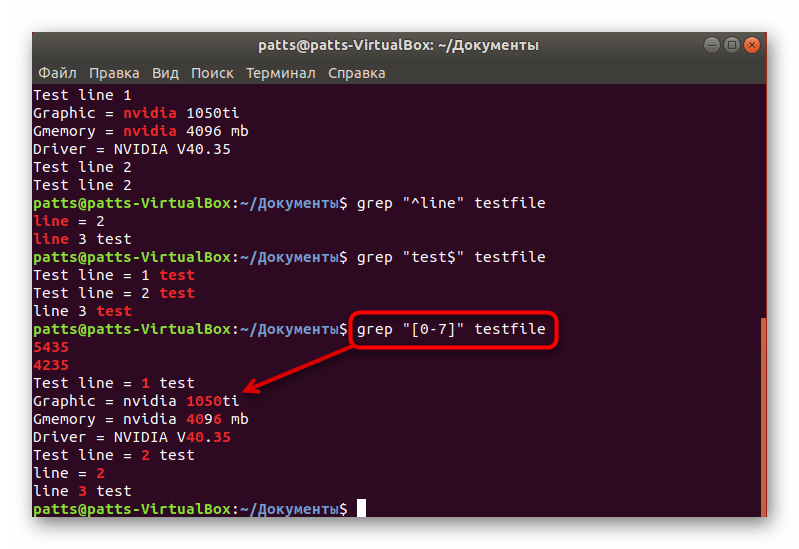
Поиск чисел
При поиске нужных значений пользователь не всегда имеет информацию касательно точного слова, присутствующего в строке. Тогда процедуру поиска можно производить через числа, что иногда значительно упрощает задачу. Надо лишь задействовать рассматриваемую команду в виде grep «4» testfile , где «1» — диапазон значений, а testfile — название файла для сканирования.
Анализ всех файлов директории
Сканирование всех объектов, находящихся в одной папке, называется рекурсивным. Юзеру требуется применить только один аргумент, который проведен анализ всех файлов папки и выведет на экран подходящие строки и их расположение. Понадобится ввести grep -r «word» /home/user/folder , где /home/user/folder — путь к директории для сканирования.
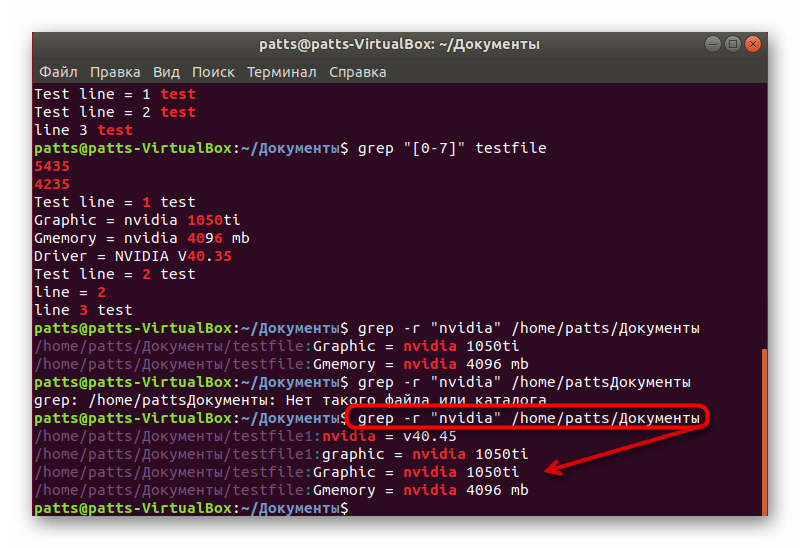
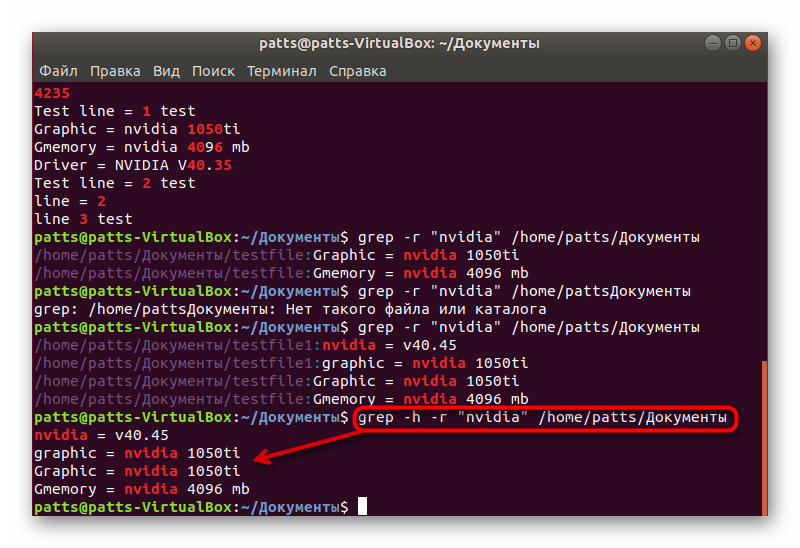
Голубым цветом будет отображаться место хранения файла, а если хотите получить строки без этой информации, присвойте еще один аргумент, чтобы команда получилась такой grep -h -r «word» + путь к папке .
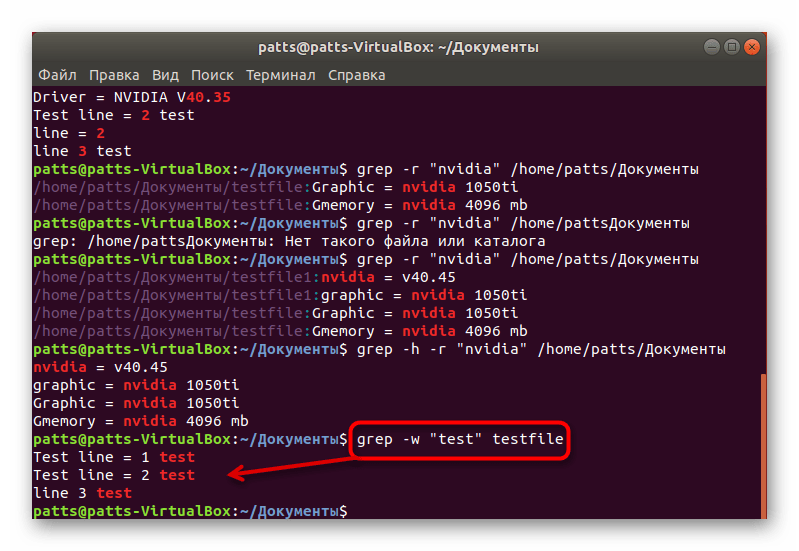
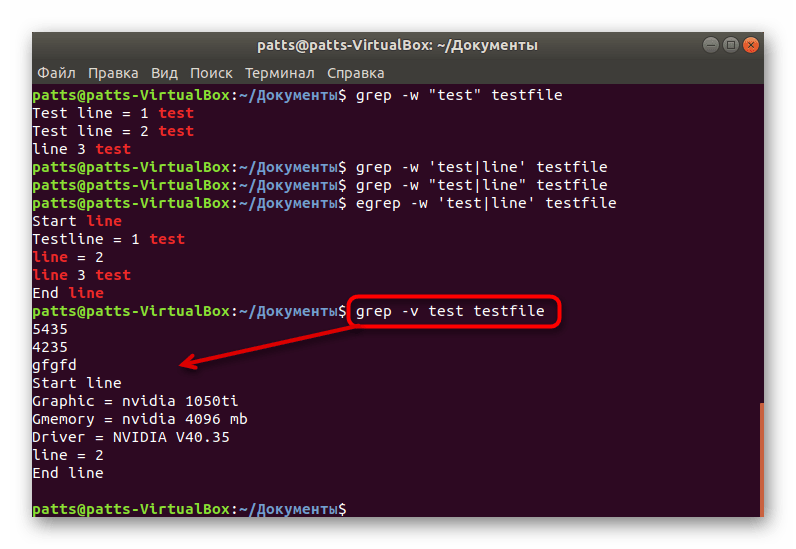
Точный поиск по словам
В начале статьи мы уже говорили об обычном поиске по словам. Однако при таком методе в результатах будут высвечиваться дополнительные комбинации. Например, вы находите слово User, но команда отобразит еще и User123, PasswordUser и другие совпадения, если такие имеются. Чтобы избежать такого результата, присвойте аргумент -w ( grep -w «word» + имя файла или его расположение ).
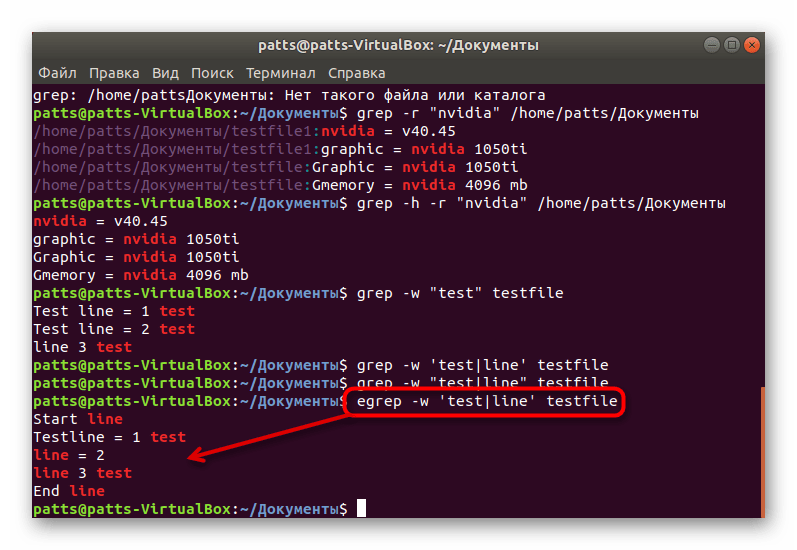
Выполняется эта опция и при надобности поиска сразу нескольких точных ключевых слов. В таком случае введите egrep -w ‘word1|word2’ testifile . Обратите внимание, что в этом случае к grep добавляется буква e, а кавычки ставятся одинарные.
Поиск строк без определенного слова
Рассматриваемая утилита умеет не только находить слова в файлах, но и выводить строки, в которых отсутствует заданное пользователем значение. Тогда перед введением ключевого значения и файла добавляется -v . Благодаря ей при активации команды вы увидите только соответствующие данные.
Синтаксис grep собрал в себе еще несколько аргументов, о которых можно вкратце рассказать:
| Аргументы | Описание |
|---|---|
| -I | Показывать только названия файлов, подходящих под критерий поиска |
| -s | Отключить уведомления о найденных ошибках |
| -n | Отображать номер строки в файле |
| -b | Показывать номер блока перед строчкой |
Ничто не мешает вам применять несколько аргументов для одного нахождения, просто вводите их через пробел, не забывая учитывать регистр.
Сегодня мы детально разобрали команду grep, доступную в дистрибутивах на Linux. Она является одной из стандартных и часто использующихся. Прочитать о других популярных инструментах и их синтаксисе вы можете в отдельном нашем материале по следующей ссылке.
Match exact string using grep
Have you actually tried grep -w ? (That option is exactly for that purpose, and it works for me.) — Note: option -x matches the whole line.
«I want to match exactly deiauk / «I only need this: deiauk 1611516 afsdf 765 « — which do you need?
5 Answers 5
grep -w "deiauk" textfile grep "\" textfile If you have a dash (—) at the end of the string this script will bring it as a result, which was not expected.
Correct @Evert : Words include only alpha chars, digits and underscores, so if you have abbreviations or other items hyphenated, this does not work.
It does not work for any special character it have for example org.apache.avro avro greped with org.apache.avro avro+mapred (tried with *)
Try this with GNU grep and mark word boundaries with \b :
If your grep supports -P (PCRE), you can do:
$ grep -P '(^|\s)\Kdeiauk(?=\s|$)' file.txt deiauk 1611516 afsdf 765 deiauk 1611516 afsdf ddfgfgd Why is \K (PCRE reset start of match) needed? This proposed solution seems to work just fine without it.
Depending on your real data, you could look for the word followed by a space:
If you know it has to be at the start of the line, check for it:
@Shatu Thanks! So let’s see how long it takes for it to «bubble up to the top». I’m curious because I like to add answers to old questions. I think it is assumed it does, but I doubt it. It would be just nice for me, but actually useful for the readers. To make this a good example case, could I ask you to write a comment summarizing what the other answers are missing?
(1) Congratulations on reaching 10K rep. You now have the privilege to see that this answer was given before, and was deleted. (2) It’s always better to answer the question as broadly as possible, based on what is said, and not give an answer that works just for the sample data. It appears, from the example data in the question, that the columns are separated by spaces — but that’s not specified. All the other answers will also work for tab-separated columns. (3) You avoided the fatal flaw in tachomi’s (deleted) answer by adding the ^ — but all the other answers work … (Cont’d)
(Cont’d) … if the string appears in a field other than the first one. (4) Also, all the other answers work if ‘‘deiauk’’ is the last field (i.e., there’s nothing after it).