How can I extract text from images?
How can I extract text from images? I am not talking about scanned files, but garden variety images, such as when you take a high-def picture of a blackboard at class, and it is nicely handwritten; or when you photograph a page from a recipe book and want the recipe in text format. Any free and open software for that? I tried tesseract, and the results were awful.
5 Answers 5
The act of extracting text from images is called OCR and Ubuntu has a wiki page dedicated to OCR. From that page:
Available OCR tools
The Ubuntu Universe repositories contain the following OCR tools:
- gocr — A command line OCR
- fuzzyocr — spamassassin plugin to check image attachments
- libhocr0 — Hebrew OCR
- ocrad — Optical Character Recognition program
- ocrfeeder — Document layout analysis and optical character recognition system
- ocropus — document analysis and OCR system
- tesseract-ocr
The Ubuntu multiverse respositories also contain:
Some packages are outdated, but unofficial fresh ones can be found in Alex_P PPA (PPA adding code: ppa:alex-p/notesalexp). If you never used a PPA check how to add software from a PPA.
edit: As shown in comment Clara OCR exists too but it got stuk at Hardy and their website has 2009 as last updated.
Do you have experience using any of those for the examples I described? I became a bit sceptical to regular ocr tools for them. Number 7 on the list is the one I tried and was plainly terrible.
If I recall, I tried gocr also, with equivalent terrible results. If you tried with success any of those, what syntax did you use? Thanks.
None whatsoever! I never bothered with OCR 😀 Freshmeat search shows Clara OCR and tesseract-ocr 😉 ( freshmeat.net/search/… )
Am I wrong if I say that successful use of OCR requires knowledge of the process and a careful setup to fit the particular image to be scanned? Thus, if I’m right, bad results might be due to the user and not the software.
OCR works best if you know how the image is created and you are very well versed in using the software that you use (the latter being the reason I never got around to using it).
tesseract-ocr would be the great one compared to all others. For Installation, run the below command
sudo apt-get install tesseract-ocr Usage is tesseract filename.jpg output.txt , then it will generate output.txt file.
You might consider selecting the appropriate language. In that case, you will need to install tesseract-ocr-LANG package, where LANG is the three-letter ISO 639-2 language code. Right now you have 123 languages on 18.04 repo. Then use for example:
tesseract mySpanishText.jpg output -l spa Hey, so this does works but is not accurate or I would rather say is 80-85% accurate. Like example for this image: pbs.twimg.com/media/DJs6_pcXkAA2VrN.jpg, it messed up $ sign and also most brackets. Square, round, curly, all brackets are a problem, they never get extracted properly. Do you know of any fix?
Frog
To install on Ubuntu using Flatpak:
- First, if you haven’t already, install Flatpak using the Ubuntu quick start guide. Remember to restart your system afterwards.
- Go to Frog on Flathub and click Install. Or, if you prefer the command-line, run this command:
flatpak install flathub com.github.tenderowl.frog There are perfectly good solutions that exist within mainstream repos. I didn’t think this adds anything to the accepted answer. At best, wheel reinvention, at worst, potential security risk with lesser audited non-official repo install.
I have brought the negative downvote back to 0, since this is the best GUI suggestion, sorry it took years to correct since I just saw this now, sorry the toxic part of the community got to you, I frankly think this is the best answer if you don’t want to work with the command line, Thank You!
Thanks @king_below_my_lord. I’ve deleted my comments, since I don’t think they serve a purpose any more.
TextSnatcher
Try TextSnatcher. This application uses the Tesseract OCR 4.x for the character recognition behind the scenes.
Probably the easiest way to install it on Ubuntu is to get it from Flathub:
- First, if you haven’t already, install Flatpak using the Ubuntu quick start guide. Remember to restart your system afterwards.
- Go to TextSnatcher on Flathub and click Install. Or, if you prefer the command-line, run this command:
flatpak install flathub com.github.rajsolai.textsnatcher I didn’t downvote (and don’t think it deserved a downvote — though fortunately you have some headroom before your reputation is seriously eroded!), but my only comment would be that in my opinion, your 2 answers would be better as one, with multiple recommendations, rather than two separate answers.
@Will Interesting, why do you say that? If you wanted to upvote one recommendation and downvote the other, how would you do that if the answers were combined? If you wanted to only read comments about one piece of software, wouldn’t it be better to have separate posts? AskUbuntu allows multiple answers from the same user for a reason, I think it’s precisely for cases like this one.
I suppose it’s preference; the question is ‘how can I do x’ and a good answer to me is one that presents a good number of options to help them decide what to do. I think it very unlikely I’d upvote one option and downvote another — but I’d likely upvote an answer that gave the op the options they needed to make a decision. But it’s only the way I would like answers to my questions — I’m no authority on how to answer!
Upvoted this up, unlike Frog having a Tesseract OCR based solution might be preferable to some, both quite frankly excellent choices with I preferring Frog, though this might admittedly do better with handwriting detection etc
Using tesseract-ocr we can extract text from images. I have tested gocr which didn’t work well as compare to tesseract-ocr
sudo apt-get install tesseract-ocr Python program to convert all the image files with png extension inside of current directory to txt file
#!/usr/bin/env python3.10 import os import subprocess def list_files(path): files = [] for name in os.listdir(path): if os.path.isfile(os.path.join(path, name)): files.append(os.path.join(path, name)) return files def convertImageToText(img_file): #process = subprocess.Popen(['tesseract', img_file, # ''.join(img_file.rsplit('.png', 1))]) os.system(f"tesseract <''.join(img_file.rsplit('.png', 1))>") def startOperation(): list_file = list_files(".") print(list_file) for img_file in list_file: if img_file.lower().split(".")[-1] == "png": convertImageToText(img_file) startOperation() Image To Text

Make sure snap support is enabled in your Desktop store.
Install using the command line
sudo snap install imagetotext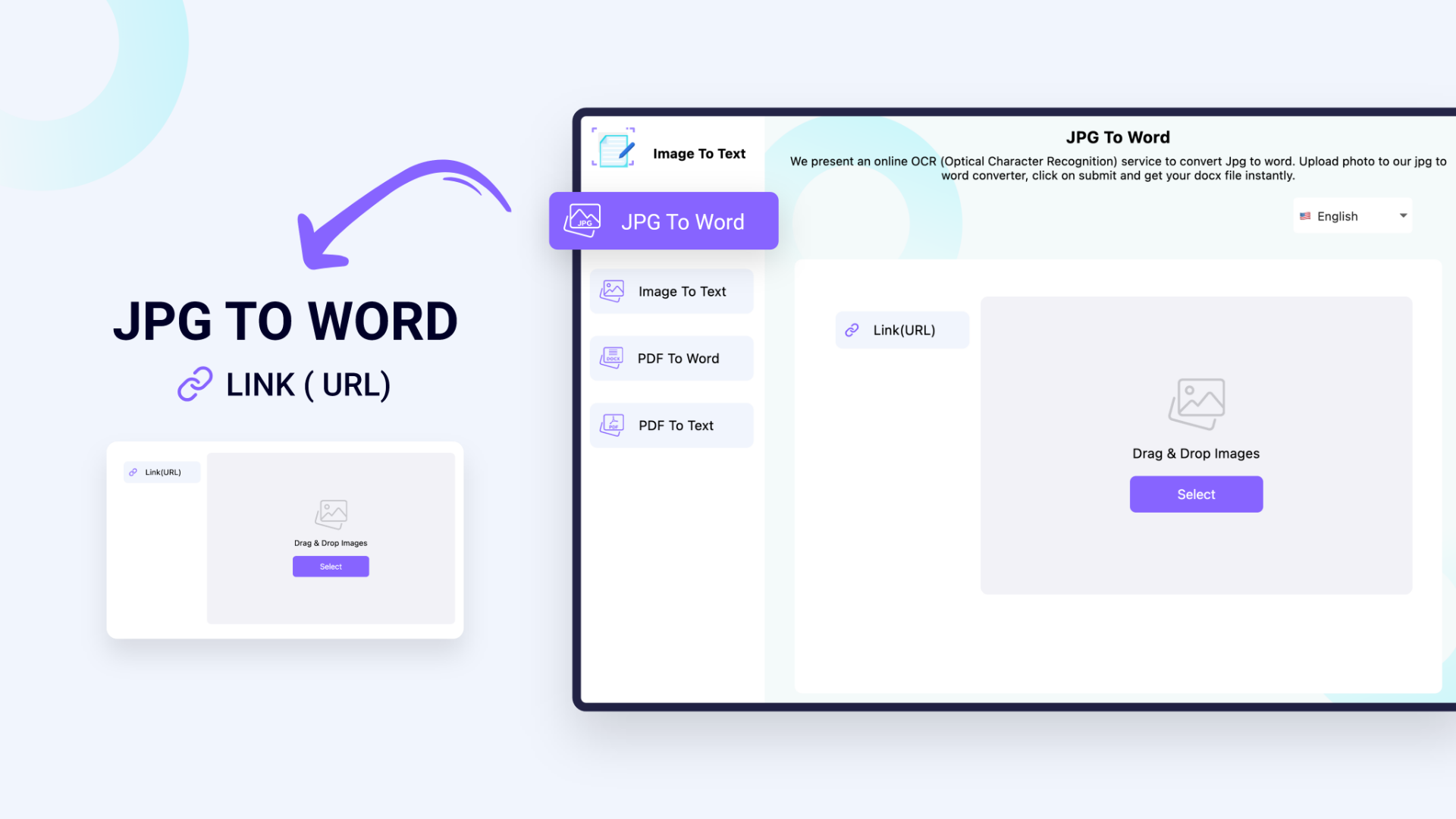
You can convert PDF to Word, JPG to Word, and do much more with this app
Using this image to text converter, you can convert your PDF documents and images into editable text files.
There are multiple conversion modes available in this app, and you can pick from them according to your requirement.
Our picture to text application allows you to upload files directly from your system storage, or you can use a link to fetch the image from the internet instead. You can also do the same thing for PDF documents.
How to extract text from image?
After you have downloaded the app and installed it, here are the steps that you can follow to use it:
Select your conversion mode.
1.Upload your image from your device or enter a URL to fetch it directly from the internet.
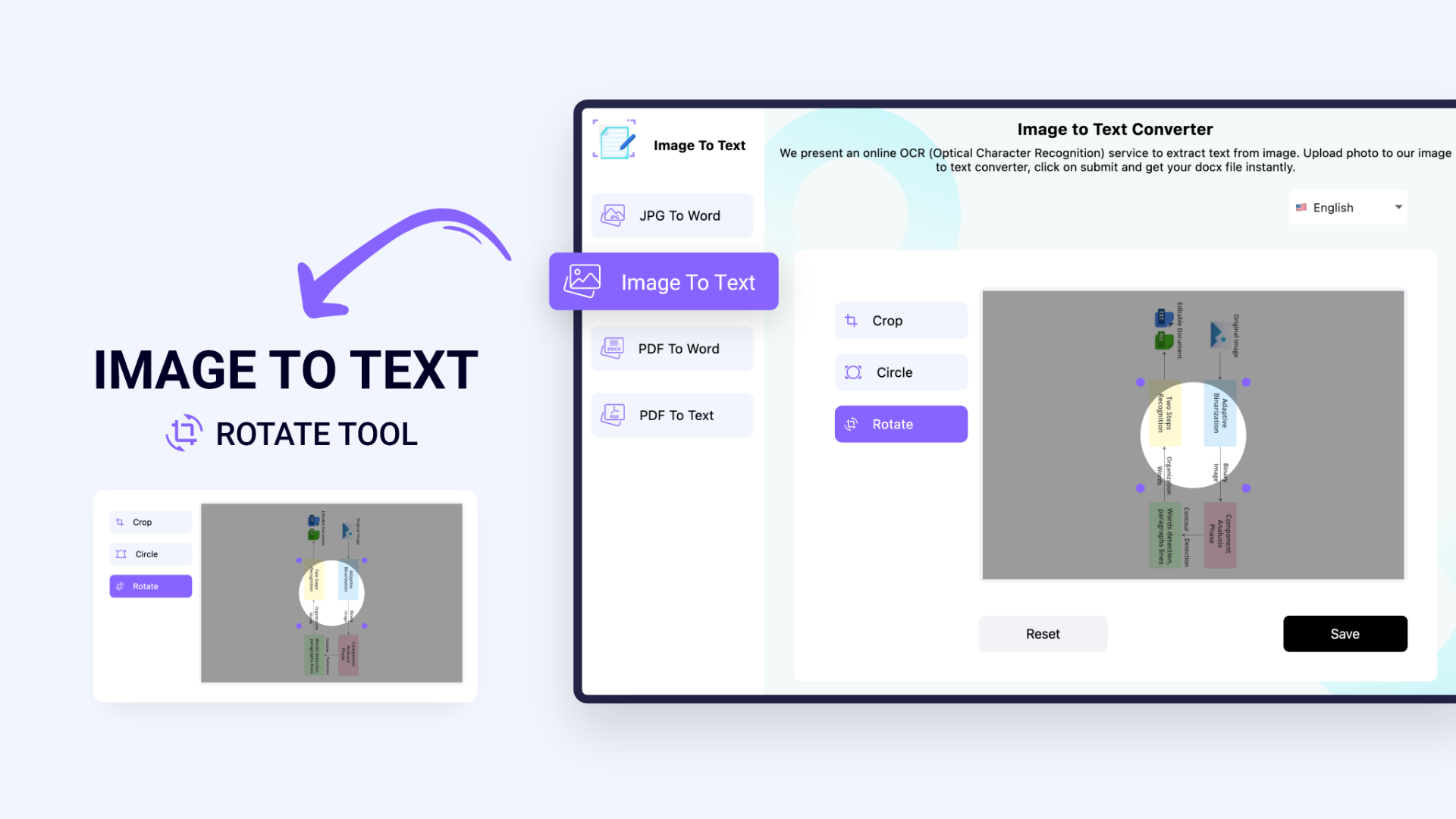
2.Edit your image by cropping and rotating it.
3.Click on the ‘Submit’ button to get the extracted text.
How Does This Tool Work?
This image to text converter uses the advanced OCR (optical character recognition) to recognize the characters written inside the images. After the characters are recognized, they are converted into an editable file in the format of your choice.
Features of This Image to Text Converter?
Here are some features that you can enjoy with this app
Before finalizing the image, you can crop it in a rectangular or circular shape, and you can also rotate it. If you have an image in the horizontal orientation that you want to get in the vertical orientation (or vice versa), you can adjust it right within the converter rather than using an actual editor. Similarly, if you only want to convert a certain portion of an image into the editable text format, you can use the cropping feature to adjust it as well.
This image to text converter also lets you specify the language for the output text. You can select the language from the top before starting the process.
Our photo to text converter provides the below four different modes to perform the conversion process
- JPG to Word
- Image to Text
- PDF to Word
- PDF to TXT
- No Sign-Up Required
You can use this application just after downloading it. There is no sign-up process that you have to go through. You can utilize this app for an instant image to text conversions at your convenience.