Программы для распознавания текста для linux
Для Linux имеются разнообразные инструменты командной строки и с графическим интерфейсом для преобразования изображений в текст. В этой статье будут рассмотрены программы, с помощью которых вы можете после сканирования страниц книги или документов перевести их в текстовый формат.
OCR программы в Linux с графическим интерфейсом
OCRFeeder
OCRFeeder — это система анализа макета документов и оптического распознавания символов. Откройте в этой программе изображения и она автоматически определит контуры областей, в которых находятся изображения и текст и выполнит OCR (распознавание текста) этого документа. Программа может сохранять полученные результаты в разные форматы, главным из них является ODT. Программа имеет законченный GTK+ графический пользовательский интерфейс, который позволяет пользователям корректировать любые нераспознанные символы, определять или корректировать границы областей текста, устанавливать стили параграфов, очищать введённые изображения, импортировать PDF, сохранять и загружать проект, экспортировать всё в несколько форматов и так далее. В общем, это программа по функциям схожая с Abbyy FineReader, в некотором смысле, можно сказать, что OCRFeeder это аналог Abbyy FineReader для Linux, по крайней мере, в его базовой функциональности.
В своей работе OCRFeeder использует сторонние движки оптического распознавания символов, например, по умолчанию она использует Tesseract. Для установки нужно установить и графический интерфейс OCRFeeder и Tesseract. В Debian и производных Tesseract устанавливается в качестве зависимости, поэтому необязательно указывать этот пакет явно. Но при этом помните, что вместе с Tesseract устанавливается по умолчанию только распознавание английского языка, для дополнительной поддержки русского, нужно явно указать этот пакет. Про распознавание других языков, а также про работу с Tesseract будет рассказано в этой же статье далее. Установка OCRFeeder в Ubuntu, Linux Mint, Debian, Kali Linux и их производные: Установка OCRFeeder в Arch Linux, BlackArch и их производные: Как пользоваться OCRFeeder Для запуска программы найдите её в меню (скорее всего, в разделе Офис): Или в командной строке выполните команду:
Внешний вид программы:  Для анализа у меня есть тестовое изображение:
Для анализа у меня есть тестовое изображение:  Загрузим его в программу (для этого нажмите знак плюс +). Вам необязательно добавлять изображения по одному — можно добавлять целыми папками или импортировать PDF документ. Для распознавания в меню Документ выберем «Распознать документ» (будут распознаны все страницы, которые загружены в программу), либо «Распознать страницу» (будет распознана страница, которая выделена в данный момент). В правом нижнем углу появляются результаты распознавания текста:
Загрузим его в программу (для этого нажмите знак плюс +). Вам необязательно добавлять изображения по одному — можно добавлять целыми папками или импортировать PDF документ. Для распознавания в меню Документ выберем «Распознать документ» (будут распознаны все страницы, которые загружены в программу), либо «Распознать страницу» (будет распознана страница, которая выделена в данный момент). В правом нижнем углу появляются результаты распознавания текста:
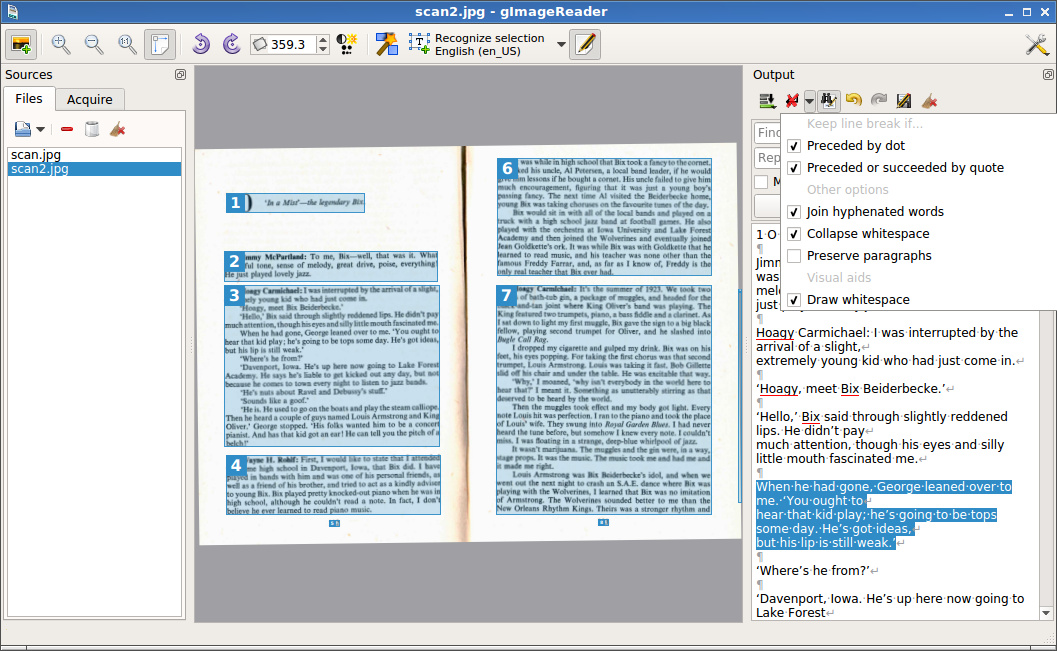 С моим тестовым файлом, результаты неудовлетворительные, поскольку программа неудачно выбрала области для распознавания. Это исправить легко, просто выбираем новую область и выбираем «Распознать выделенную область»:
С моим тестовым файлом, результаты неудовлетворительные, поскольку программа неудачно выбрала области для распознавания. Это исправить легко, просто выбираем новую область и выбираем «Распознать выделенную область»: 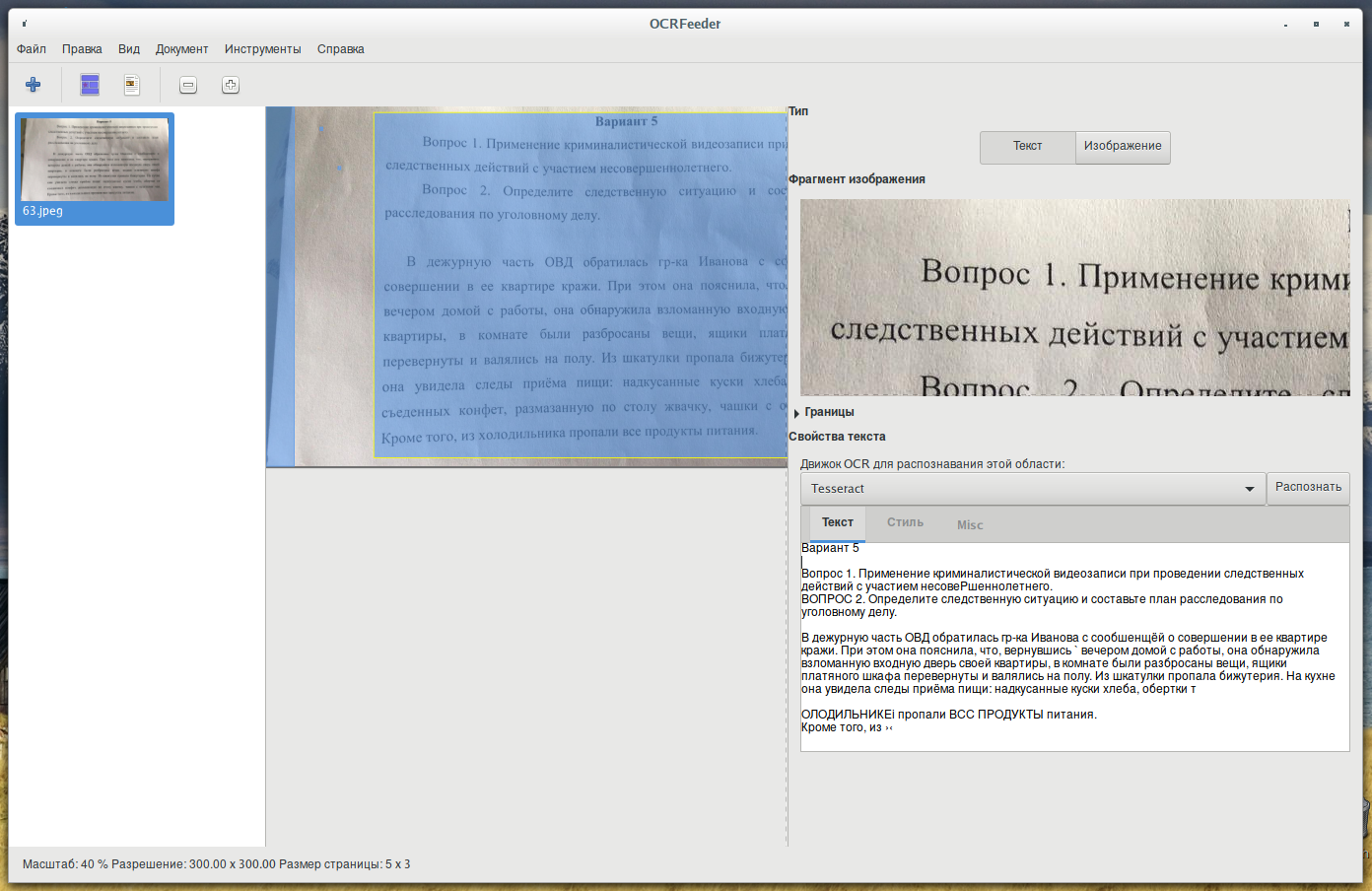 Как видим, результаты не идеальные, но вполне удовлетворительные — после небольшой ручной корректировки, этот текст пригоден для использования. Как обычно с системами OCR — чем лучше качество исходного текста (имеют значение ровность, размер, контрастность и другое), тем лучше получается результат (хотя в любом случае требуется вычитка и корректировка полученного при распознавании текста):
Как видим, результаты не идеальные, но вполне удовлетворительные — после небольшой ручной корректировки, этот текст пригоден для использования. Как обычно с системами OCR — чем лучше качество исходного текста (имеют значение ровность, размер, контрастность и другое), тем лучше получается результат (хотя в любом случае требуется вычитка и корректировка полученного при распознавании текста): 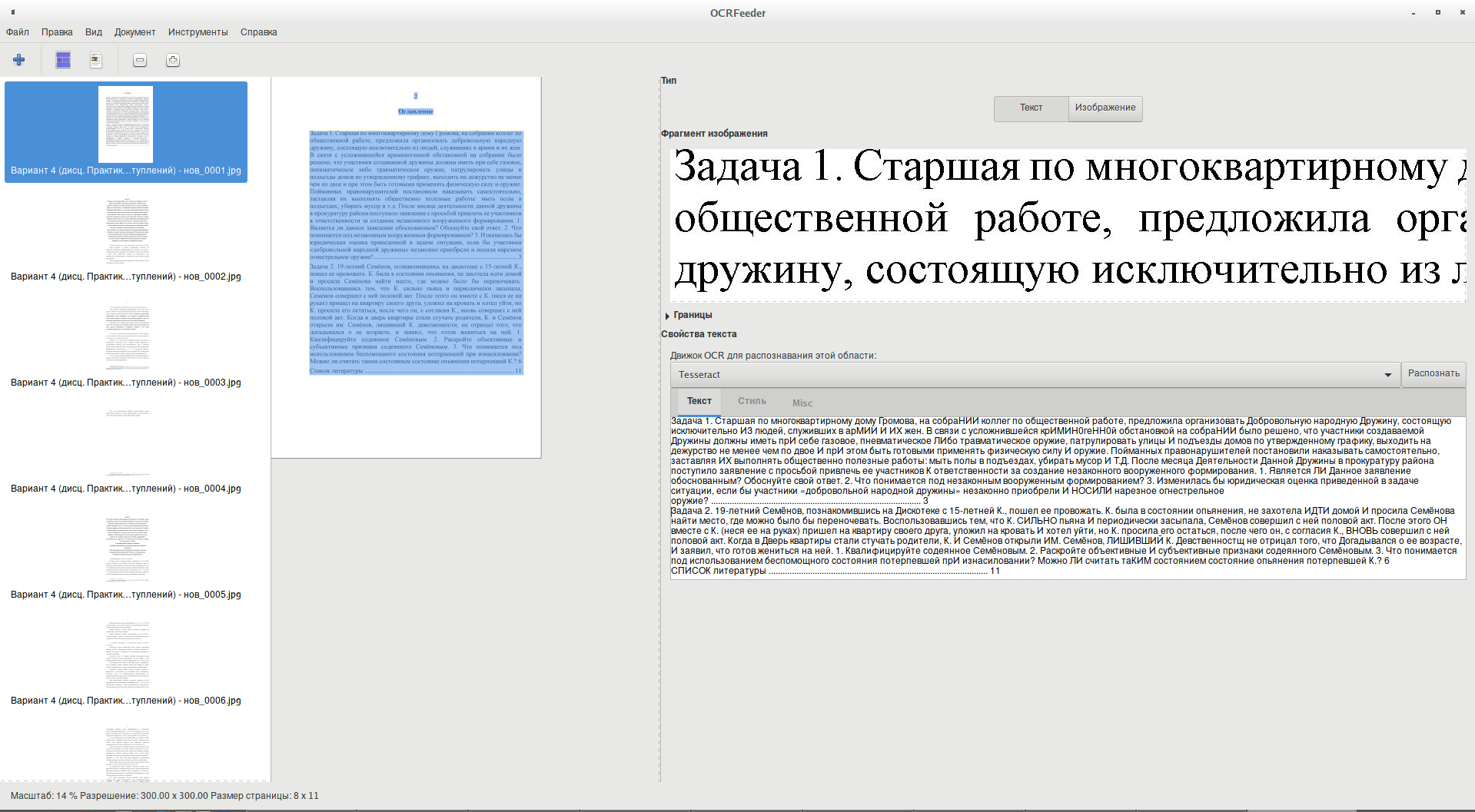 По умолчанию языком для распознавания установлен тот же язык, что имеет ваша система, то есть, скорее всего, русский язык. Вы можете изменить язык в Меню → Настройки → Распознавание → Default language. Если вы выбрали неверный язык, то движок оптического распознавания символов вернёт плохие результаты. Если вы выбрали язык, который не поддерживается движком, то он может вернуть пустую страницу.
По умолчанию языком для распознавания установлен тот же язык, что имеет ваша система, то есть, скорее всего, русский язык. Вы можете изменить язык в Меню → Настройки → Распознавание → Default language. Если вы выбрали неверный язык, то движок оптического распознавания символов вернёт плохие результаты. Если вы выбрали язык, который не поддерживается движком, то он может вернуть пустую страницу.
Вы можете экспортировать для распознавания PDF документы. А полученные результаты сохранять в различных форматах: Также вы можете сохранить весь проект целиком в собственном формате программы. Если вы запускаете OCRFeeder из командной строки, то вы можете использовать несколько опций для ускорения процесса добавления изображений.
gImageReader
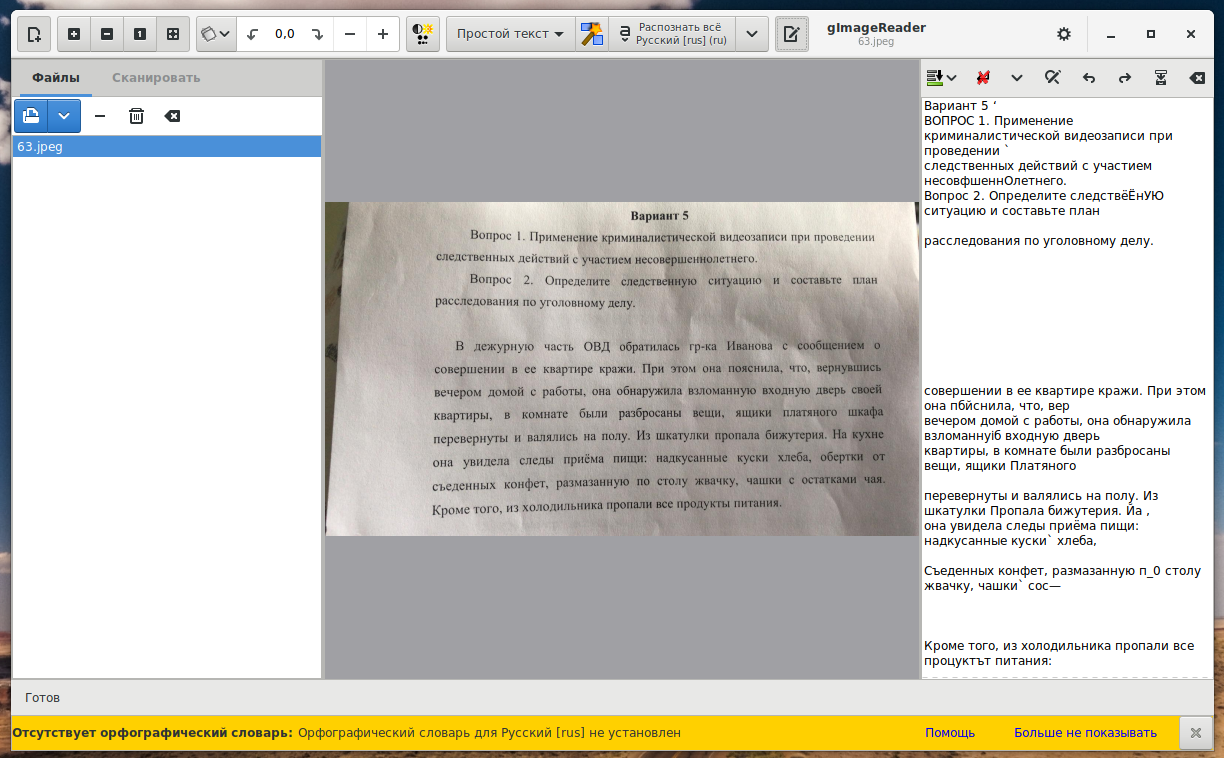
gImageReader — это графический GTK+ интерфейс для tesseract-ocr. Tesseract — пожалуй, самое точное программное обеспечение с открытым исходным кодом для оптического распознавания символов (OCR) и может распознавать текст на более чем 60 языках. gImageReader поддерживает автоматическое определение макета страницы, но пользователь также может вручную задать и отредактировать области распознавания. Есть возможность импортировать изображения с диска, устройств сканирования, буфера обмена и скриншотов. gImageReader также поддерживает многостраничные документы PDF. Распознанный текст отображается непосредственно рядом с изображением и базовое редактирование текста включает поиск/замену и удаление сломанных строк если это возможно. Также поддерживается проверка орфографии для выводимого текста если установлены соответствующие словари.
- Импорт PDF документов и изображений с диска, сканирующих устройств, буфера обмена и скриншотов
- Обработка нескольких изображений и документов за один проход
- Ручное или автоматическое определение области распознавания
- Распознавание в простой текст или в документ hOCR
- Распознанный текст отображается рядом с исходным изображением
- Последующая обработка текста, включая проверку орфографии
- Геренирование PDF документов из hOCR документов
Установка OCRFeeder в Ubuntu, Linux Mint, Debian, Kali Linux и их производные:
Установка OCRFeeder в Arch Linux, BlackArch и их производные:
ocrgui
ocrgui — это графический интерфейс для OCR программ (Tesseract, GOCR). Программа давно не обновлялась и может отсутствовать в стандартных репозиториях.
Установка OCRFeeder в Arch Linux, BlackArch и их производные:
screentranslator
Это экранный переводчик, программа захватывает область экрана, распознаёт текст и выполняет его перевод. Если вам не нужен перевод, то его можно отключить.
Установка OCRFeeder в Arch Linux, BlackArch и их производные:
В настройках укажите путь к tesseract: /usr/bin/tesseract
Утилиты командной строки для OCR
Далее будут рассмотрены движки оптического распознавания символов, которые имеют интерфейс командной строки. Эта информация может пригодиться продвинутым пользователям, привыкшим иметь дело с консолью, а также пользователям OCRFeeder, поскольку эта программа умеет работать с каждым из рассмотренных ниже OCR инструментов, и знание их особенностей и различий помогут вам правильно выбрать используемый движок OCR:

Tesseract
Tesseract — это движок оптического распознавания символов (OCR) с открытым исходным кодом. Его можно использовать напрямую, с помощью API для извлечения печатного текста из изображений, а также программы с графическим интерфейсом, такие как OCRFeeder, могут использовать Tesseract. Этот движок поддерживает большое количество языков. Пакет включает в себя утилиту командной строки.
Обратите внимание на опцию -l, после которой нужно указать используемый язык. Если он не указан, то подразумевается английский. Можно указать несколько языков, разделённых знаком плюс. Tesseract использует 3-символьные коды языков ISO 639-2.
Ocrad
GNU Ocrad это OCR (Optical Character Recognition — оптическое распознавание символов) программа, основывающаяся на методе извлечения признаков. Она считывает битовую карту изображения в формате pgm/pbm и выдаёт текств в байтовом (8-бит) или UTF-8 форматах.
Ocrad включает анализатор разметки, способный разделять столбцы или блоки текста, какие обычно бывают на печатных страницах.
Для лучшего результата символы должны быть по крайней мере 20 пикселей в высоту. Если они меньше, попробуйте опцию —scale. Сканированные изображения на 300 dpi обычно дают размер символов достаточно хорошего размера для ocrad.
Слитые, очень смелые или очень светлые (сломанные) символы обычно не распознаются правильно. Старайтесь избегать их.
Если файлы не указаны, то ocrad считывает изображения из стандартного ввода. Если опция -o не указана, ocrad отправляет текст в стандартный вывод.
Статусы выхода: 0 для нормального выхода, 1 при проблемах в среде (файл не найден, неверные флаги, ошибки ввода/вывода и т.д.), 2 говорит о повреждённом или неверном файле ввода, 3 для ошибки внутренней консистенции (например, баг), которая вызвала панику в ocrad.
gocr — это мультиплатформенная программа распознавания текстов (OCR). Она принимает файлы изображений pnm, pbm, pgm, ppm, some pcx и tga. В настоящее время программа должна быть способна хорошо работать со сканами, в которых есть текст в один столбец и нет таблиц. Поддерживается размер шрифта от 20 до 60 пикселей.
gocr [options] pnm_file_name # use — for stdin
Опции (больше подробностей в мануале man gocr):
Использовать файл jpeg переданный по трубе:
Cuneiform
Cuneiform — это многоязычная система OCR (распознавания текста). В дополнении к распознаванию текста, она также анализирует разметку и распознаёт формат текста.
Поддерживаются следующие языки: болгарский, хорватский, чешский, датский, голландский, английский, эстонский, французский, немецкий, венгерский, итальянский, латышский, литовский, польский, португальский, румынский, русский, сербский, словенский, испанский, шведский, турецкий и украинский.
Режим распознавания оптимизирован для текстов, напечатанных на принтерах с точечной матрицей
Использовать режим распознавания, оптимизированный для текстов, переданных по факсу.
—singlecolumn
Отключить анализ разметки страницы и исходить из того, что изображение состоит из одной колонки текста.
Выбрать формат вывода. Доступны следующие форматы:
- html (HTML формат),
- hocr (hOCR HTML формат),
- native (родной формат Cuneiform 2000),
- rtf (RTF формат),
- smarttext (простой текст с TeX параграфами),
- text (простой текст).
По умолчанию это plain text.
По умолчанию Cuneiform распознаёт английский текст. Для изменения языка используйте переключатель командной строки, после -l после которого следует код языка (обычно трёхбуквенный код ISO 639-2).
Поддерживаются следующие языки:
Если вы не указали файл вывода с переключателем -o, то Cuneiform запишет результаты в файл ‘cuneiform-out.format’. Расширение файла зависит от вашего формата вывода.
Форматы ввода
Cuneiform может обрабатывать любые изображения с единичной страницой, которые GraphicsMagick знает как открывать. Посмотрите мануала gm(1) для полного списка поддерживаемых форматов изображений.
ocropy
ocropy — это написанный на Python OCR пакет, использующий рекуррентные нейронные сети (ранее назывался OCRopus).
ocropy — это коллекция программ для анализа документов, это не простая OCR система, которая распознаёт тексты в графическом интерфейсе или с запуском одной команды. Функции ocropy разбиты на отдельные модули и, например, для простого распознавания текста может потребоваться ввести несколько команд для подготовки документа.
В дополнении к самим скриптам распознавания, имеется ряд скриптов для базового редактирования и коррекции, измерению процента ошибок, определению матриц путаницы и т. п.
Установка OCRFeeder в Arch Linux, BlackArch и их производные: