- Count lines in large files
- 15 Answers 15
- 5 Ways to Count the Number of Lines in a File
- 1. Count Number Of Lines Using wc Command
- 2. Count Number Of Lines Using Awk Command
- 3. Count Number Of Lines Using Sed Command
- 4. Count Number Of Lines Using Grep Command
- 5. Count Number Of Lines Using nl and cat Commands
- 8 Ways to Count Lines in a File in Linux
- The concept of Data Streams and Piping
- Data streams
- Piping
- Ways to Count Lines in a File in Linux
- WC
- count lines in a file
Count lines in large files
I commonly work with text files of ~20 Gb size and I find myself counting the number of lines in a given file very often. The way I do it now it’s just cat fname | wc -l , and it takes very long. Is there any solution that’d be much faster? I work in a high performance cluster with Hadoop installed. I was wondering if a map reduce approach could help. I’d like the solution to be as simple as one line run, like the wc -l solution, but not sure how feasible it is. Any ideas?
Thanks. yes. but to access many nodes I use an LSF system which sometimes exhibits quite an annoying waiting time, that’s why the ideal solution would be to use hadoop/mapreduce in one node but it’d be possible to use other nodes (then adding the waiting time may make it slower than just the cat wc approach)
wc -l fname may be faster. You can also try vim -R fname if that is faster (it should tell you the number of lines after startup).
15 Answers 15
Also cat is unnecessary: wc -l filename is enough in your present way.
mmm interesting. would a map/reduce approach help? I assume if I save all the files in a HDFS format, and then try to count the lines using map/reduce would be much faster, no?
@lvella. It depends how they are implemented. In my experience I have seen sed is faster. Perhaps, a little benchmarking can help understand it better.
@KingsIndian. Indeeed, just tried sed and it was 3 fold faster than wc in a 3Gb file. Thanks KingsIndian.
@Dnaiel If I would guess I’d say you ran wc -l filename first, then you ran sed -n ‘$=’ filename , so that in the first run wc had to read all the file from the disk, so it could be cached entirely on your probably bigger than 3Gb memory, so sed could run much more quickly right next. I did the tests myself with a 4Gb file on a machine with 6Gb RAM, but I made sure the file was already on the cache; the score: sed — 0m12.539s, wc -l — 0m1.911s. So wc was 6.56 times faster. Redoing the experiment but clearing the cache before each run, they both took about 58 seconds to complete.
This solution using sed has the added advantage of not requiring an end of line character. wc counts end of line characters («\n»), so if you have, say, one line in the file without a \n, then wc will return 0. sed will correctly return 1.
Your limiting speed factor is the I/O speed of your storage device, so changing between simple newlines/pattern counting programs won’t help, because the execution speed difference between those programs are likely to be suppressed by the way slower disk/storage/whatever you have.
But if you have the same file copied across disks/devices, or the file is distributed among those disks, you can certainly perform the operation in parallel. I don’t know specifically about this Hadoop, but assuming you can read a 10gb the file from 4 different locations, you can run 4 different line counting processes, each one in one part of the file, and sum their results up:
$ dd bs=4k count=655360 if=/path/to/copy/on/disk/1/file | wc -l & $ dd bs=4k skip=655360 count=655360 if=/path/to/copy/on/disk/2/file | wc -l & $ dd bs=4k skip=1310720 count=655360 if=/path/to/copy/on/disk/3/file | wc -l & $ dd bs=4k skip=1966080 if=/path/to/copy/on/disk/4/file | wc -l & Notice the & at each command line, so all will run in parallel; dd works like cat here, but allow us to specify how many bytes to read ( count * bs bytes) and how many to skip at the beginning of the input ( skip * bs bytes). It works in blocks, hence, the need to specify bs as the block size. In this example, I’ve partitioned the 10Gb file in 4 equal chunks of 4Kb * 655360 = 2684354560 bytes = 2.5GB, one given to each job, you may want to setup a script to do it for you based on the size of the file and the number of parallel jobs you will run. You need also to sum the result of the executions, what I haven’t done for my lack of shell script ability.
If your filesystem is smart enough to split big file among many devices, like a RAID or a distributed filesystem or something, and automatically parallelize I/O requests that can be paralellized, you can do such a split, running many parallel jobs, but using the same file path, and you still may have some speed gain.
EDIT: Another idea that occurred to me is, if the lines inside the file have the same size, you can get the exact number of lines by dividing the size of the file by the size of the line, both in bytes. You can do it almost instantaneously in a single job. If you have the mean size and don’t care exactly for the the line count, but want an estimation, you can do this same operation and get a satisfactory result much faster than the exact operation.
5 Ways to Count the Number of Lines in a File
On Linux, you can do a single task in several ways. Likewise, if you want to count the number of lines in single or multiple files, you can use different commands. In this article, I’ll share five different ways including that you can use to print a total number of lines in a large file.
1. Count Number Of Lines Using wc Command
As wc stands for “word count“, it is the most suitable and easy command that has the sole purpose of counting words, characters, or lines in a file.
Let’s suppose you want to count the number of lines in a text file called distros.txt.
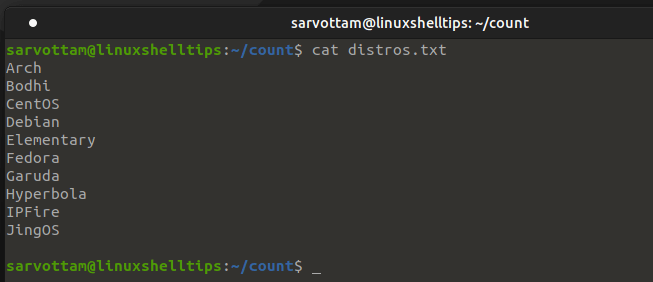
You can use «-l» or «—line» option with wc command as follows:
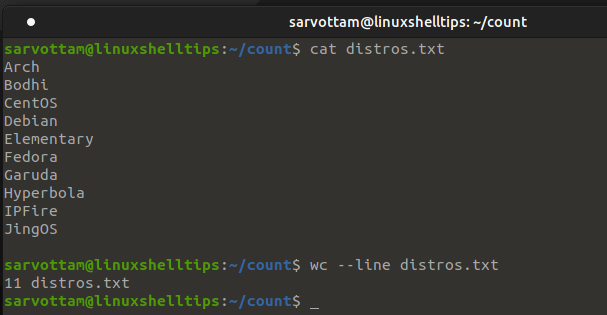
You can see that wc also counts the blank line and print the number of lines along with the filename. In case, you want to display only the total number of lines, you can also hide the filename by redirecting the content of the file to wc using a left-angle bracket (<) instead of passing the file as a parameter.

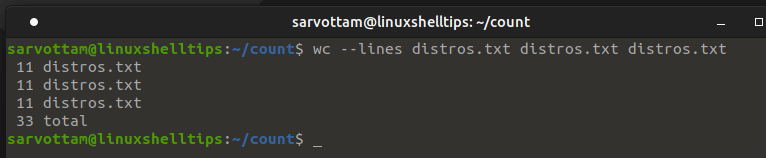
Moreover, to display a number of lines from more than one file at the same time, you need to pass the filenames as arguments separated by space.
$ wc --lines distros.txt distros.txt distros.txt
In another way, you can also make use of the cat command to redirect the file content to the wc command as input via pipe (‘|’) .

Though it will also count the number of lines in a file, here the use of cat seems redundant.
2. Count Number Of Lines Using Awk Command
Awk is a very powerful command-line utility for text processing. If you already know awk, you can use it for several purposes including counting the number of lines in files.
However, mastering it may take time if you’re at a beginner level. Hence, if you just want to use it to count the total number of lines in a file, you can remember the following command:

Here, NR is the number of records or say line numbers in a file being processed at the END section.
3. Count Number Of Lines Using Sed Command
Sed is a also very useful tool for filtering and editing text. More than a text stream editor, you can also use sed for counting the number of lines in a file using the command:

Here, ‘=’ prints the current line number to standard output. So, combining it with the -n option, it counts the total number of lines in a file passed as an argument.
4. Count Number Of Lines Using Grep Command
Using yet another useful pattern search command grep, you can get the total number of lines in a file using ‘-e’ or ‘—regexp’ and ‘-c’ or ‘—count’ options.
$ grep -e "$" -c distros.txt Or $ grep -e "^" -c distros.txt

Here, ‘$’ is a regular expression representing the end of a line and the ‘^’ start of a line. You can use either of the regular expression.
5. Count Number Of Lines Using nl and cat Commands
Instead of directly getting the total no of lines, you can also print the file content and get the total number of lines by peeking at the last line number. For such purpose, nl is a simple command to print data with numbered lines.
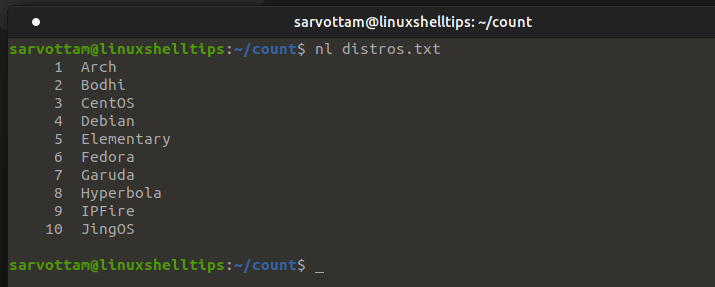
For large files, it does not seem like a suitable method to display all data in a terminal. So what you can also do is pipe the data to tail command to just print only some of the last numbered lines.
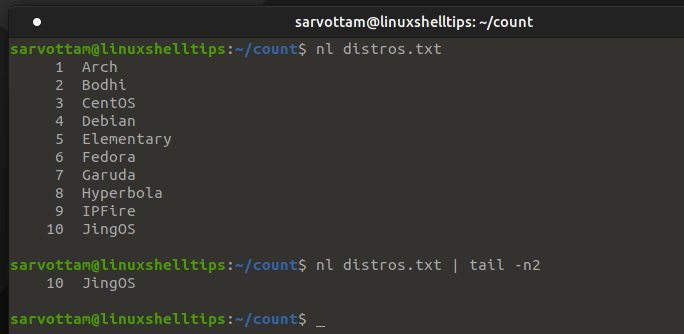
Likewise, a cat command with ‘-n’ can also be used to print file content with line numbers.
$ cat -n distros.txt | tail -n1

Conclusion
After learning five ways to count a number of lines, you must be wondering which is the best way for you? In my opinion, whether you’re a beginner or advanced user of Linux, the wc command is the easiest and fastest approach.
However, if you’re in process of learning other powerful tools like grep, awk, and sed, you can also practice these commands for such purpose to hone your skills.
8 Ways to Count Lines in a File in Linux
![wc -l < [filename] on a green background](https://bytexd.com/wp-content/uploads/2022/06/8-Ways-to-Count-Lines-in-a-File-in-Linux-800x500.png)
Counting lines in a Linux file can be hectic if you don’t know the applicable commands and how to combine them. This tutorial makes the process comfortable by walking you through eight typical commands to count lines in a file in Linux.
For example, the word count, wc , command’s primary role, as the name suggests, is to count words. However, since a group of words forms a line, you can use the command to count lines besides characters and words.
All you do is redirect the input of a file to the command alongside the -l flag.
Apart from the wc , you can use the awk, sed, grep, nl , pr , cat and perl commands. Before that, it would help to understand data streams and piping in Linux.
Table of Contents
The concept of Data Streams and Piping
Data streams
Three files come together to complete the request when you run a command: standard input, standard output, and error files.
The standard input, abbreviated as stdin and redirected as < , feeds the computer with data. The standard output, abbreviated as stdout and redirected as >, shows the result of running a command. If an error occurs when processing the result, we see the standard error, often abbreviated as stderr .
The primary stdin is the keyboard, while the stdout is the (monitor) screen. However, due to the flexibility of Linux and the fact that everything in Linux is a file, we can change the stdin , stdout , or stderr to suit our needs, as you will see when counting lines with the wc command.
Before that, you should understand the concept of piping in Linux.
Piping
Piping in Linux, denoted by | , means running two or more commands simultaneously on the terminal. For example, we can cat a file, let’s call the file index.txt . But instead of waiting to see the output, we redirect it to the sort command, which outputs the data alphabetically.
Now that you understand the main concepts applied when customizing a file’s input to get the number of lines, let’s see eight ways to count lines in a file in Linux.
Ways to Count Lines in a File in Linux
WC
The wc command returns a file’s line numbers, words, and characters, respectively.
Let’s create a file, practice.txt , and append the following lines.
We are counting file lines. We use the wc, awk, sed, grep, and perl commands. The process is easy because we can redirect ouptut and pipe commands. Linux is becoming fun!
Running the wc command on the file, we get the following output:
Likewise, we can control the output using specific flags with the input redirection symbol.
count lines in a file
The standard way is with wc , which takes arguments to specify what it should count (bytes, chars, words, etc.); -l is for lines:
$ wc -l file.txt 1020 file.txt How do I count the lines in a file if I want to ignore comments? Specifically, I want to not count lines that begin with a +, some white space (could be no white space) and then a %, which is the way comment lines appear in a git diff of a MATLAB file. I tried doing this with grep, but couldn’t figure out the correct regular expression.
@Gdalya I hope the following pipeline will do this (no tests were perfomed): cat matlab.git.diff | sed -e ‘/^\+[ ]*.*\%$/d’ | wc -l . /regexp/d deletes a line if it matches regexp , and -e turns on an adequate (IMNSHO) syntax for regexp .
@celtschk , as long as this is usual in comment lines: is it possible to modify your grep command in order to consider as comment cases like » + Hello» (note the space(s) before the + )?
@SopalajodeArrierez: Of course it is possible: grep -v ‘^ *+’ matlab.git.diff | wc -l (I’m assuming the quote signs were not actually meant to be part of the line; I also assume that both lines with and without spaces in front of the + are meant to be comments; if at least one space is mandatory, either replace the star * with \+ , or just add another space in front of the star). Probably instead of matching only spaces, you’d want to match arbitrary whitespace; for this replace the space with [[:space:]] . Note that I’ve also removed matching the % since it’s not in your example.