- CPU Load: когда начинать волноваться?
- Аналогия транспортного потока
- Так Вы говорите, 1.00 — идеальное значание load average?
- Что насчет многопроцессорных систем? Мой сервер показывает загрузку 3.00 и все ОК!
- Многоядерность vs. многопроцессорность
- Сведем все вместе
- Примечания переводчика
- PS
- PPS
- PPPS
- Как работает метрика Load Average в Linux
- Основы Load Average в Linux
- Метрика Load Average в Linux
- Проверка Load Average в Linux
- 1: Команда uptime
- 2: Команда top
- 3: Утилита glances
- Подводим итоги
CPU Load: когда начинать волноваться?
Данная заметка является переводом статьи из блога компании Scout. В статье дается простое и наглядное объяснение такого понятия, как load average . Статья ориентирована на начинающих Linux-администраторов, но, возможно, будет полезна и более опытным админам. Заинтересовавшимся добро пожаловать под кат.
Вероятно, Вы уже знакомы с понятием load average . Load average — это три числа, отображаемые при выполнении команд top и uptime . Выглядят они примерно так:
Большинство интуитивно понимают, что эти три числа обозначают средние значения загрузки процессора на прогрессивно увеличивающихся временных промежутках (одна, пять и пятнадцать минут) и чем меньше их значения — тем лучше. Большие числа свидетельствуют о слишком большой нагрузке на сервер. Но какие значения считать предельными? Какие значения являются «плохими», а какие — «хорошими»? Когда Вам следует просто волноваться о занчениях средней загрузки, а когда следует бросать другие дела и решать проблему так быстро, как это возможно?
Для начала, давайте разберемся, что же означает load average . Рассмотрим простейший случай: предположим, что у нас в наличии один сервер с одноядерным процессором.
Аналогия транспортного потока
Одноядерный процессор похож на дорогу с одной полосой движения. Представьте себе, что Вы управяете движением машин по мосту. Иногда, Ваш мост загружен настолько сильно, что машинам приходится ждать в очереди чтобы проехать по нему. Вы хотите дать людям понять, как долго им придется ждать чтобы перебраться на другую сторону реки. Хорошим способом сделать это будет показать как много машин ждут в очереди в конкретный момент времени. Если машин в очереди нет, подъезжающие водители будут знать, что они сразу смогут проехать по мосту. В противном случае, они будут понимать, что придется ждать своей очереди.
Итак, Управляющий Мостом, какую систему обозначений Вы будете использовать? Как насчет такой:
- 0.00 означает, что на мосту нет ни одной машины. Фактически, значения от 0.00 до 1.00 означают отсутствие очереди. Подъезжающая машина может воспользоваться мостом без ожидания;
- 1.00 означает, что на мосту находится как раз столько автомобилей, сколько он может вместить. Все еще идет хорошо, но, в случае увеличения потока машин, возможны проблемы;
- Значения, превышающие 1.00 означают наличие очереди на въезде. Насколько большой? Например, значение 2.00 показывает, что в очереди стоит столько же автомобилей, сколько движется по мосту. 3.00 означает, что мост полностью занят и в очереди ожидает в два раза больше машин, чем он может вместить. И так далее.
 load average = 1.00
load average = 1.00  load average = 0.50
load average = 0.50  load average = 1.70
load average = 1.70
Вот базовое значение загрузки процессора. «Машины» обрабатываются с использованием промежутков процессорного времени («пересекают мост»), либо ставятся в очередь. В Unix это называется длина очереди выполнения: количество всех процессов, выполняемых в данный момент времени, плюс количество процессов, ожидающих в очереди.
Вам, как управляющему мостом, хотелось бы, чтобы машины-процессы никогда не ждали в очереди. Таким образом, предпочтительно, чтобы загрузки процессора была всегда ниже 1.00. Периодически возможны всплески трафика, когда загрузка будет превышать 1.00, но если она постоянно превышает данное значение — это повод начать волноваться.
Так Вы говорите, 1.00 — идеальное значание load average?
- Практическое правило «Требуется присмотр»: 0.70. Если среднее значение загрузки постоянно превышает 0.70, следует выяснить причину такого поведения системы во избежании проблем в будущем;
- Практическое правило «Почини это немедленно!»: 1.00. Если средняя загрузка системы превышает 1.00, необходимо срочно найти причину и устранить ее. В противном случае, Вы рискуете быть разбуженным посреди ночи и это точно не будет весело;
- Практическое правило «Щас же 3 ночи. ШОЗАНАХ. »: 5.00. Если среднее значение загрузки процессора превышает 5.00, у Вас серьезные проблемы. Сервер может подвисать или работать очень медленно. Скорее всего, это произойдет в худший из возможных моментов. Например, посреди ночи или когда Вы выступаете с докладом на конференции.
Что насчет многопроцессорных систем? Мой сервер показывает загрузку 3.00 и все ОК!
У Вас четырехпроцессорная система? Все в порядке, если load average равен 3.00.
В мультипроцессорных системах загрузка вычисляется относительно количества доступных процессорных ядер. 100% загрузка обозначается числом 1.00 для одноядерной машины, числом 2.00 для двуядерной, 4.00 для четырехъядерной и т.д.
Если вернуться к нашей аналогии с мостом, 1.00 означает «одну полностью загруженную полосу движения». Если на мосту всего одна полоса, 1.00 означает, что мост загружен на 100%, если же в наличии две полосы, он загружен всего на 50%.
То же самое с процессорами. 1.00 означает 100% загрузки одноядерного процессора. 2.00 — 100% загрузки двуядерного и т.д.
Многоядерность vs. многопроцессорность
- «Количество ядер = максимальная загрузка». На многоядерной системе, загрузка не должна превышать количества доступных ядер;
- «Ядра — они и в Африке ядра». То, как ядра распределены по процессорам — неважно. Два четырехъядерных = четыре двуядерных = восем одноядерных процессоров. Имеет значение лишь общее число ядер.
Сведем все вместе
~$ uptime 09:14:44 up 1:20, 5 users, load average: 0,35, 0,32, 0,41 Здесь представлены показатели для системы с четырехъядерным процессором и мы видим, что имеется большой запас по нагрузке. Я даже не буду задумываться о ней, пока load average не превысит 3.70.
Какое среднее значение мне следует контролировать? Для одной, пяти или 15 минут?
Для значений, о которых мы говорили раньше (1.00 — почини это немедленно и т.д.), следует рассматривать временные промежутки в пять и 15 минут. Если загрузка Вашей системы превышает 1.00 на интервале в одну минуту, все в порядке. Если же загрузка превышает 1.00 на пяти- или 15-минутном интервале, Вам следует начать принимать меры (конечно, Вам следует также принимать во внимание количество ядер в Вашей системе).
Количество ядер важно для правильно понимания load average. Как мне его узнать?
Команда cat /proc/cpuinfo выводит информацию обо всех процессорах в вашей системе. Чтобы узнать количество ядер, «скормите» ее вывод утилите grep :
~$ cat /proc/cpuinfo | grep 'cpu cores' cpu cores : 4 cpu cores : 4 cpu cores : 4 cpu cores : 4 Примечания переводчика
Выше представлен перевод самой статьи. Также много интересной информации можно почерпнуть из комментариев к ней. Так, один из комментаторов говорит о том, что не для каждой системы важно иметь запас по производтельности и не допускать значения загрузки выше 0.70 — иногда нам нужно чтобы сервер работал «на всю катушку» и в таких случаях load average = 1.00 — то, что доктор прописал.
PS
Хабраюзер dukelion добавил в комментариях ценное замечание, что в некоторых сценариях, для достижения максимального КПД «железа», стоит держать значение load average несколько выше 1.00 в ущерб эффективности работы каждого отдельного процесса.
PPS
Хабраюзер enemo в комментариях добавил замечание о том, что высокий показатель load average может быть вызван большим количеством процессов, выполняющих в данный момент операции чтения/записи. То есть, load average > 1.00 на одноядерной машине не всегда говорит о том, что в Вашей системе отсутствует запас по загрузке процессора. Требуется более внимательное изучение причин такого показателя. Кстати, это хорошая тема для нового поста на Хабре 🙂
PPPS
Хабраюзер esvaf в комментариях интересуется, как интерпретировать значения load average в случае использования процессора с технологией HyperThreading. Однозначного ответа на данный момент я не нашел. В данной статье утверждается, что процессор, который имеет два виртуальных ядра при одном физическом, будет на 10-30% более производительным, чем простой одноядерный. Если принимать такое допущение за истину, считаю, при интерпретации load average стоит брать в расчет только количество физических ядер.
Как работает метрика Load Average в Linux
Load Average (cредняя нагрузка) — это метрика, которую используют пользователи Linux для отслеживания системных ресурсов. Она также помогает мониторить, как задействованы ресурсы системы.
Load Average является одной из самых основных метрик использования ресурсов, но она не принесет никакой пользы, если вы не понимаете, о чем она говорит. В этом мануале мы рассмотрим, что такое Load Average в Linux и как ее читать. Кроме того, мы обсудим несколько простых методов для мониторинга Load Average вашей системы.
Основы Load Average в Linux
Чтобы понять, что такое Load Average, нам нужно знать, что именно мы определяем как нагрузку. В системе Linux это показатель загруженности CPU в любой момент времени.
Она показывает количество процессов, которые выполняются или ожидают выполнения процессором в данный момент.
В состоянии бездействия нагрузка системы равна 0. Она увеличивается на 1 с каждым процессом, который выполняется или находится в списке ожидания.
Сама по себе нагрузка не дает пользователю никакой полезной информации. Она может измениться за доли секунды. Это происходит потому, что количество процессов, использующих процессорное время или находящихся в списке ожидания, не остается постоянным. Вот почему мы используем Load Average для мониторинга использования ресурсов.
Метрика Load Average в Linux
Как следует из названия, Load Average отображает среднюю нагрузку на CPU за определенный период времени. Эти значения представляют собой количество процессов, ожидающих выполнения на CPU или использующих его в данный период.
Большинство пользователей знакомы с процентами нагрузки в Windows, но в Linux Load Average представляется тремя десятичными значениями.

Посмотрите на скриншот выше, где показаны значения “load average: 0.03, 0.03, 0.01”.
Рассмотрим эти значения по порядку:
- Первое показывает среднюю нагрузку на CPU за последнюю минуту
- Второе дает нам среднюю нагрузку за последний 5-минутный интервал
- Третье значение показывает среднюю загрузку за последние 15 минут
Это помогает пользователю понять, как процессы в системе нагружают CPU с течением времени.
Значение 1 может означать примерно 100% использования ресурсов в однопроцессорной системе, но такие системы сегодня практически не встречаются. Если за последние 10 лет вы хотя бы раз обновляли свою систему, она должна работать на многоядерном процессоре.
Для двухъядерного процессора значение 1 означает, что одно ядро свободно на 100 %. То есть это примерно 50% использования CPU. Соответственно, для четырехъядерного процессора это 25% использования.
Load Average в Linux учитывает ожидающие и выполняемые процессы. Кроме того, это среднее значение, а не текущее.
Для приблизительного представления об использовании ресурсов можно разделить значение Load Average на количество ядер вашего процессора. Это не точное значение загрузки CPU, но это может быть полезно для мониторинга ресурсов.
Проверка Load Average в Linux
Теперь мы рассмотрим несколько способов проверки значения Load Average. Её можно посмотреть тремя способами.
1: Команда uptime
uptime — один из наиболее распространенных методов проверки Load Average в системе. Чтобы выполнить команду uptime, просто откройте терминал и введите следующее:
На скриншоте выше показано, что вы увидете при выполнении команды uptime. Здесь отображается время работы системы, количество активных пользователей и Load Average.
Как видите, Load Average за последнюю минуту равна 0.03. Значения за последние 5 и 15 минут составляют 0.03 и 0.01 соответственно .
2: Команда top
Ещё один способ мониторинга Load Average — выполнить команду top. Для этого откройте терминал и введите следующую команду:
Команда откроет интерфейс top в терминале. В отличие от uptime, эта команда выводит подробное описание об использовании ресурсов вашей системы.
На следующем скриншоте показано, что вы увидите при выполнении команды top.
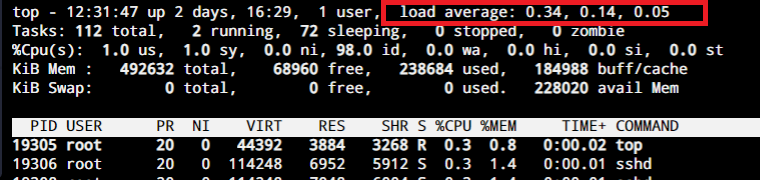
Как видно из самой верхней строки, Load Average за последнюю минуту составляет 0.34. За последние 5 минут и 15 минут значения равны 0.14 и 0.05 соответственно.
3: Утилита glances
glances — это утилита мониторинга системы, которая работает аналогично команде top. Она дает подробный обзор использования системных ресурсов. Чтобы использовать утилиту glances, необходимо установить её пакет с помощью этой команды:
sudo apt-get install glances
После завершения установки введите в терминале следующее:
Команда откроет интерфейс glances в терминале. В отличие от команды top, здесь отображается количество доступных процессорных ядер, а также Load Average системы.
На следующем скриншоте показано, что вы увидите, при выполнении команды glances.
Как видно из выделенной области, Load Average за последнюю минуту равна 0.14. За последние 5 минут и 15 минут значения равны 0.12 и 0.05 соответственно.
Подводим итоги
Load Average в Linux — это важная метрика, позволяющая легко мониторить использование системных ресурсов. Контроль Load Average гарантирует, что ваша система не столкнется со сбоями или медленными сессиями.