- how to merge 2 big files [closed]
- 3 Answers 3
- Can you merge two files without writing one file onto the other?
- Can we make this better than doubling the size of both files?
- Can we avoid using extra space?
- What about writing a little bit at a time, then deleting what we wrote?
- What about sparse files?
- Merge Files in the Linux Command Line
- Use the cat command to merge files in Linux
- Append changes to the existing file
- Automate the merging files using the loop in Linux
- Use the sed command to merge files in Linux (temporary)
- Wrapping Up
- how to merge multiple files into one single file in linux
- Merge Multiple files into One in Order
- Merge Two Files at Arbitrary Location
- How to merge all (text) files in a directory into one?
how to merge 2 big files [closed]
Suppose I have 2 files with size of 100G each. And I want to merge them into one, and then delete them. In linux we can use cat file1 file2 > final_file But that needs to read 2 big files, and then write a bigger file. Is it possible just append one file to the other, so that no IO is required? Since metadata of file contains the location of the file, and the length, I am wondering whether it is possible to change the metadata of the file to do the merge, so no IO will happen.
Someone who finds their way to this questions might find «hungrycat» useful. hungrycat prints contents of a file on the standard output, while simultaneously freeing disk space occupied by the file: github.com/jwilk/hungrycat
3 Answers 3
Can you merge two files without writing one file onto the other?
Only in obscure theory. Since disk storage is always based on blocks and filesystems therefore store things on block boundaries, you could only append one file to another without rewriting if the first file ended perfectly on a block boundary. There are some rare filesystem configurations that use tail packing, but that would only help if the first file where already using the tail block of the previous file.
Unless that perfect scenario occurs or your filesystem is able to mark a partial block in the middle of the file (I’ve never heard of this), this won’t work. Just to kick the edge case around, there’s also no way outside of changing the kernel interace to make such a call (re: Link to a specific inode)
Can we make this better than doubling the size of both files?
Yes, we can use the append ( >> ) operation instead.
That will still result in using all the space of consumed by file2 twice over until we can delete it.
Can we avoid using extra space?
No. Unless somebody comes back with something I don’t know, you’re basically out of luck there. It’s possible to truncate a file, forgetting about the existence of the end of it, but there is no way to forget about the existence of the start unless we get back to modifying inodes directly and having to alter the kernel interface to the filesystem since that’s definitely not a a POSIX operation.
What about writing a little bit at a time, then deleting what we wrote?
No again. Since we can’t chop the start of a file off, we’d have to rewrite everything from the point of interest all the way to the end of the file. This would be very costly for IO and only useful after we’ve already read half the file.
What about sparse files?
Maybe! Sparse file allow us to store a long string of zeroes without using up nearly that much space. If we were to read file2 in large chunks starting at the end, we could write those blocks to the end of file1 . file1 would immediately look (and read) as if it were the same size as both, but it would be corrupted until we were done because everything we hadn’t written would be full of zeroes.
Explaining all this is another answer in itself, but if you can do a spare allocation, you would be able to use only your chunk read size + a little bit extra in disk space to perform this operation. For a reference talking about sparse blocks in the middle of files, see http://lwn.net/Articles/357767/ or do a search involving the term, SEEK_HOLE .
Why is this «maybe» instead of «yes»? Two parts: you’d have to write your own tool (at least we’re on the right site for that), and sparse files are not universally respected by file systems and other processes alike. Fortunately you probably won’t have to worry about other processes respecting your file, but you will have to worry about setting the right flags and making sure your filesystem is amenable. Last of all, you’ll still be reading and re-writing the length of file2 , which isn’t what you want. This method does mean you can append with just a small amount of disk space, though, rather at using at least 2*file2 amount of space.
Merge Files in the Linux Command Line
Learn various ways of merging multiple files into another file in the Linux command line.
Got two or more files and need to merge them in a single file? The simplest way would be to use the cat command. After all, the cat command’s original purpose is to concatenate files.
Use the cat command to merge files in Linux
Merging two files is simple. You just have to append the filename to the cat command and that’s it:

As you can see, I used the cat command to show the contents of a file and then merged them.
But it won’t save any changes. To save those changes, you have to redirect the file contents to another file.

Remember, the > will override the contents of the file so I would recommend using a new file as the cat will create the file if it doesn’t exist.
So how can you modify the editing file while keeping the previous content intact?
Append changes to the existing file
To modify the existing file, you just have to use >> instead of single > and you’d be good to go.
For example, I will make edit the existing file File_3.txt by appending Hello.txt and Sagar.txt :
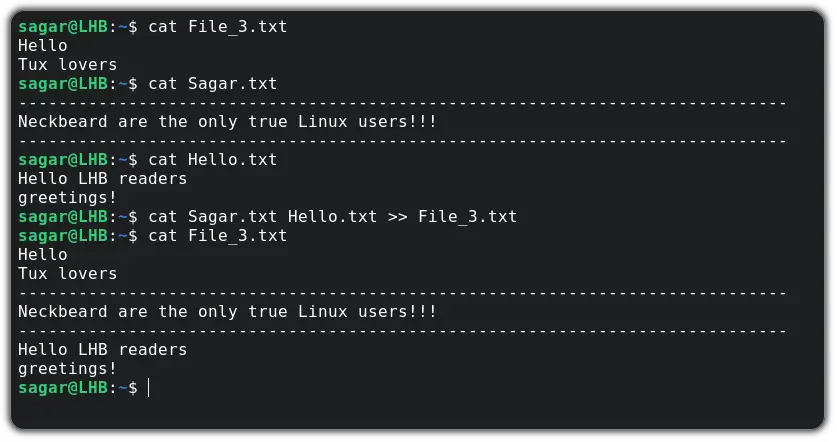
As you can see, it added new text in the end line while keeping the old content intact.
Automate the merging files using the loop in Linux
Here, I will be using for loop (till three iterations as I want to merge three files) also you can use > or >> as per your needs.
for i in ; do cat "File_$i.txt" >> NewFile.txt; done
Use the sed command to merge files in Linux (temporary)
There are many times when you want to apply changes only for a specific time and in those cases, you can use sed.
Being a non-interactive way of editing files, the sed utility can be tremendously useful when used in the right way.
And when used with the h flag, it will hold the buffer temporarily:

Wrapping Up
This was my take on how you can merge files using the sed and cat command. And if you have any queries, leave us a comment.
This post and this website contains affiliate links. See my disclosure about affiliate links.
how to merge multiple files into one single file in linux
Many a times you may have multiple files that needs to merged into one single file. It could be that you previously split a single file into multiple files, and want to just merge them back or you have several log files that you want merged into one. Whatever the reason, it is very easy to merge multiple text files into a single file in Linux.
The command in Linux to concatenate or merge multiple files into one file is called cat. The cat command by default will concatenate and print out multiple files to the standard output. You can redirect the standard output to a file using the ‘>‘ operator to save the output to disk or file system.
Another useful utility to merge files is called join that can join lines of two files based on common fields. It can however work only on two files at a time, and I have found it to be quite cumbersome to use. We will cover mostly the cat command in this post.
Merge Multiple files into One in Order
The cat command takes a list of file names as its argument. The order in which the file names are specified in the command line dictates the order in which the files are merged or combined. So, if you have several files named file1.txt, file2.txt, file3.txt etc…
bash$ cat file1.txt file2.txt file3.txt file4.txt > ./mergedfile.txt
The above command will append the contents of file2.txt to the end of file1.txt. The content of file3.txt is appended to the end of merged contents of file1.txt and file2.txt and so on…and the entire merged file is saved with the name mergedfile.txt in the current working directory.
Many a time, you might have an inordinately large number of files which makes it harder to type in all the file names. The cat command accepts regular expressions as input file names, which means you can use them to reduce the number of arguments.
bash$ cat file*.txt my*.txt > mergedfile.txt
This will merge all the files in the current directory that start with the name file and has a txt extension followed by the files that start with my and has a txt extension. You have to be careful about using regular expressions, if you want to preserve the order of files. If you get the regular expression wrong, it will affect the exact order in which the files are merged.
A quick and easy way to make sure the files get merged in the exact order you want, is to use the output of another file listing program such as ls or find and pipe it to the cat command. First execute the find command with the regular expression and verify the file order…
bash$ find . -name «file*.txt» -o -name «my*.txt»
This will print the files in order such that you can verify it to be correct or modify it to match what you want. You can then pipe that output into the cat command.
bash$ find . -name «file*.txt» -o -name «my*.txt» | xargs cat > ./mergedfile.txt
When you merge multiple files into one file using regular expressions to match them, especially when it is piped and where the output file is not very obvious, make sure that the regular expression does not match the filename of the merged file. In the case that it does match, usually the cat command is pretty good at error-ing out with the message “input file is output file”. But it helps to be careful to start with.

Merge Two Files at Arbitrary Location
Sometimes you might want to merge two files, but at a particular location within the content of a file. This is more like the process of inserting contents of one file into an another at a particular position in the file.
If the file sizes are small and manageable, then vi is a great editor tool to do this. Otherwise the option is to split the file first and then merge the resulting files in order. The easiest way is to split the file is based on the line numbers, exactly at where you want to insert the other file.
bash$ split -l 1234 file1.txt
You can split the file into any number of output files depending on your requirement. The above example will split the file file1.txt to chunks of 1234 lines. It is quite possible that you might end up with more than two files, named xaa, xab, xac etc..You can merge all of it back using the same cat command as mentioned earlier.
The above command will merge the files in order with the contents of file2.txt in between the contents of xaa and xab.
Another use case is when you need to merge only specific parts of certain files depending on some condition. This is especially useful for me when I have to analyze several large log files, but am only interested in certain messages or lines. So, I will need to extract the important log messages based on some criteria from several log files and save them in a different file while also maintaining or preserving the order of the messages.
Though you can do this using cat and grep commands, you can do it with just the grep command as well.
bash$ grep -h «[Error]» logfile*.log > onlyerrors.log
The above will extract all the lines that match the pattern [Error] and save it to another file. You will have to make sure that the log files are in order when using the regular expression to match them, as mentioned earlier in the post.
How to merge all (text) files in a directory into one?
This is technically what cat («concatenate») is supposed to do, even though most people just use it for outputting files to stdout. If you give it multiple filenames it will output them all sequentially, and then you can redirect that into a new file; in the case of all files just use ./* (or /path/to/directory/* if you’re not in the directory already) and your shell will expand it to all the filenames (excluding hidden ones by default).
Make sure you don’t use the csh or tcsh shells for that which expand the glob after opening the merged-file for output, and that merged-file doesn’t exist before hand, or you’ll likely end up with an infinite loop that fills up the filesystem.
The list of files is sorted lexically. If using zsh , you can change the order (to numeric, or by age, size. ) with glob qualifiers.
To include files in sub-directories, use:
find . ! -path ./merged-file -type f -exec cat <> + > merged-file Though beware the list of files is not sorted and hidden files are included. -type f here restricts to regular files only as it’s unlikely you’ll want to include other types of files. With GNU find , you can change it to -xtype f to also include symlinks to regular files.
Would do the same ( (-.) achieving the equivalent of -xtype f ) but give you a sorted list and exclude hidden files (add the D qualifier to bring them back). zargs can be used there to work around argument list too long errors.