- odt2txt(1) — Linux man page
- Options
- Copyright
- Linux odt to text
- NAME
- SYNOPSIS
- DESCRIPTION
- OPTIONS
- COPYRIGHT
- SEE ALSO
- 3 Ways of .odt to .txt File Conversion in Command Line in Linux
- .odt to .txt file conversion using LibreOffice
- Convert .odt to .txt file using pandoc
- Convert .odt to Markdown .txt file using pandoc
- Summary
- Linux odt to text
- NAME
- SYNOPSIS
- DESCRIPTION
- OPTIONS
- COPYRIGHT
- SEE ALSO
- Convert .odt .doc .ods files to .txt files
odt2txt(1) — Linux man page
odt2txt is a command-line tool which extracts the text out of OpenDocument Texts, as produced by OpenOffice.org, KOffice, StarOffice and others.
odt2txt can also extract text from some file formats similar to OpenDocument Text, such as OpenOffice.org XML (*.sxw), which was used by OpenOffice.org version 1.x and older StarOffice versions. To a lesser extend, odt2txt may be useful to extract content from OpenDocument spreadsheets (*.ods) and OpenDocument presentations (*.odp).
The FILENAME argument is mandatory.
Options
—width=WIDTH Wrap text lines after WIDTH characters. The default value is 65, which means that any words which would extend beyond column 65 are moved to a new line. If WIDTH is set to -1 then no lines will be broken —output=FILE Write output to FILE and not to standard output. —subst=SUBST Select which non-ascii characters shall be replaced by ascii look-a-likes. Valid values for SUBST are all, some and none. —subst=all Substitute all characters for which substitutions are known —subst=some Substitute all characters which the output charset does not contain This is the default —subst=none Substitute no characters —encoding=X Do not try to autodetect the terminal encoding, but convert the document to encoding X unconditionally To find out, which terminal encoding will be used in automatic mode, use —encoding=show —raw Print raw XML —version Show version and copyright information
Copyright
Copyright © 2006,2007 Dennis Stosberg
Uses parts of the kunzip library, Copyright 2005,2006 by Michael Kohn
This program is free software; you can redistribute it and/or modify it under the terms of the GNU General Public License, version 2 as published by the Free Software Foundation
Linux odt to text
NAME
odt2txt - a simple converter from OpenDocument Text to plain text
SYNOPSIS
odt2txt [OPTIONS] FILENAME
DESCRIPTION
odt2txt is a command-line tool which extracts the text out of OpenDocument Texts, as produced by OpenOffice.org, KOffice, StarOffice and others. odt2txt can also extract text from some file formats similar to OpenDocument Text, such as OpenOffice.org XML (*.sxw), which was used by OpenOffice.org version 1.x and older StarOffice versions. To a lesser extend, odt2txt may be useful to extract content from OpenDocument spreadsheets (*.ods) and OpenDocument presentations (*.odp). The FILENAME argument is mandatory.
OPTIONS
--width=WIDTH Wrap text lines after WIDTH characters. The default value is 65, which means that any words which would extend beyond column 65 are moved to a new line. If WIDTH is set to -1 then no lines will be broken --output=FILE Write output to FILE and not to standard output. --subst=SUBST Select which non-ascii characters shall be replaced by ascii look-a-likes. Valid values for SUBST are all, some and none. --subst=all Substitute all characters for which substitutions are known --subst=some Substitute all characters which the output charset does not contain This is the default --subst=none Substitute no characters --encoding=X Do not try to autodetect the terminal encoding, but convert the document to encoding X unconditionally To find out, which terminal encoding will be used in automatic mode, use --encoding=show --raw Print raw XML --version Show version and copyright information
COPYRIGHT
Copyright © 2006,2007 Dennis Stosberg dennis@stosberg.net> Uses parts of the kunzip library, Copyright 2005,2006 by Michael Kohn This program is free software; you can redistribute it and/or modify it under the terms of the GNU General Public License, version 2 as published by the Free Software Foundation
SEE ALSO
© 2019 Canonical Ltd. Ubuntu and Canonical are registered trademarks of Canonical Ltd.
3 Ways of .odt to .txt File Conversion in Command Line in Linux
The Open Document .odt files can contain rich formats for the content. However, some times a plain text file is more handy. We may convert .odt files to plain text files for such needs. In this post, we discuss 3 ways of how to convert .odt files to .text files in command line in Linux. The ways here can be easily organized into a Bash script to do batch processing of a set of files too. Together with the ways of .docx/.doc to .odt File Conversion in Command Line in Linux, the methods here can be used to do .docx/.doc to plain text file conversion.
We use the LibreOffice and pandoc software. Make sure the software packages are installed in the Linux system. As an example, we use a .odt file as follows.
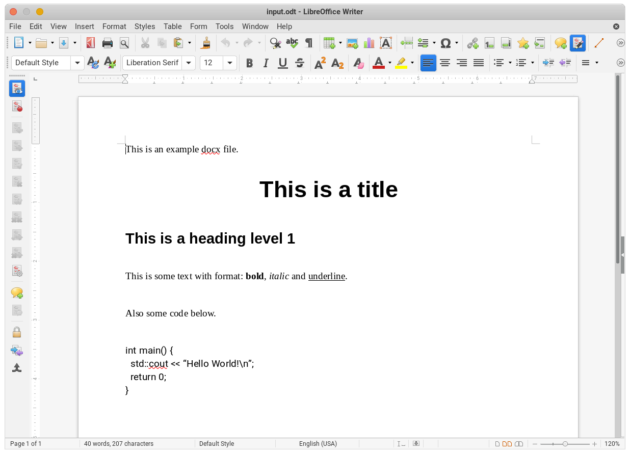
As shown in the following examples, different ways have different pros/cons. In actual usage, we may choose one suitable way or combine the results from different ways together according to the files or the purposes.
.odt to .txt file conversion using LibreOffice
We can use the —convert-to feature of the LibreOffice software to conver the .odt file to .txt file. The command to convertt the .odt file to .txt file is as follows.
$ libreoffice --convert-to txt input.odt convert /home/davidy/Downloads/input.odt -> /home/davidy/Downloads/input.txt using filter : TextThe converted .txt file looks like this.
$ cat input.txt This is an example docx file. This is a title This is a heading level 1 This is some text with format: bold, italic and underline. Also some code below. int main()
Here, we can see all the text including spaces (those in the code section) are kept. However, the format (like bold, italic, titles) are not included.
Convert .odt to .txt file using pandoc
The pandoc tool can convert many file formats. It can also read .odt files and generate .txt files.
Here is the command to convert the .odt file to .txt file is as follows.
The .txt file generated is as follows.
$ cat input-pandoc.txt This is an example docx file. This is a title THIS IS A HEADING LEVEL 1 This is some text with format: BOLD, _italic_ and _underline_. Also some code below. int main()
Here, we can see pandoc keeps some of the format (using BOLD for bold fonts, and _italic_ for italic format). However, it removes some spaces in the code section.
Convert .odt to Markdown .txt file using pandoc
Markdown format is a plain text format with its special markup elements into the text document to indicate formats. The markup elements are also in plain text and readable. It can be a good alternative plain text format.
Here is the command to convert the .odt file to Markdown format.
$ pandoc -t markdown input.odt > input-pandoc.mdThe converted Markdown file is as follows.
$ cat input-pandoc.md This is an example docx file. This is a title This is a heading level 1 ========================= This is some text with format: **bold**, *italic* and *underline*. Also some code below. int main()
Here, we can see the format are marked using Markdown markups ( **bold** , ==== and *italic* ). It is much better although it is not ideal regarding the code section handling.
Summary
This post introduce 3 ways of how to convert .odt to .txt files in command line in Linux. The ways have their pros and cons. But these methods can help us do the majority part of the conversion job. For example, for the example document in this post, by manually adjusting the Markdown plain text file based on pandoc ‘s output and LibreOffice ‘s output (for the code section), we can have a good plain text for the document.
This is an example docx file. This is a title This is a heading level 1 ========================= This is some text with format: **bold**, *italic* and *underline*. Also some code below. ``` int main() < std::cout ```The Markdown, if converted to HTML, will look like this:

Linux odt to text
NAME
odt2txt - a simple converter from OpenDocument Text to plain text
SYNOPSIS
odt2txt [OPTIONS] FILENAME
DESCRIPTION
odt2txt is a command-line tool which extracts the text out of OpenDocument Texts, as produced by OpenOffice.org, KOffice, StarOffice and others. odt2txt can also extract text from some file formats similar to OpenDocument Text, such as OpenOffice.org XML (*.sxw), which was used by OpenOffice.org version 1.x and older StarOffice versions. To a lesser extent, odt2txt may be useful to extract content from OpenDocument spreadsheets (*.ods) and OpenDocument presentations (*.odp). The FILENAME argument is mandatory.
OPTIONS
--width=WIDTH Wrap text lines after WIDTH characters. The default value is 65, which means that any words which would extend beyond column 65 are moved to a new line. If WIDTH is set to -1 then no lines will be broken --output=FILE Write output to FILE and not to standard output. --subst=SUBST Select which non-ascii characters shall be replaced by ascii look-a-likes. Valid values for SUBST are all, some and none. --subst=all Substitute all characters for which substitutions are known --subst=some Substitute all characters which the output charset does not contain This is the default --subst=none Substitute no characters --encoding=X Do not try to autodetect the terminal encoding, but convert the document to encoding X unconditionally To find out, which terminal encoding will be used in automatic mode, use --encoding=show --raw Print raw XML --version Show version and copyright information
COPYRIGHT
Copyright © 2006,2007 Dennis Stosberg dennis@stosberg.net> Uses parts of the kunzip library, Copyright 2005,2006 by Michael Kohn This program is free software; you can redistribute it and/or modify it under the terms of the GNU General Public License, version 2 as published by the Free Software Foundation
SEE ALSO
https://github.com/dstosberg/odt2txt
© 2019 Canonical Ltd. Ubuntu and Canonical are registered trademarks of Canonical Ltd.
Convert .odt .doc .ods files to .txt files
That being said, I have had some troubles getting that to work in the past- If you're having trouble, take a look at similar programs for AbiWord (another open source word processor).
For word documents, you can try antiword , at least on linux. It's a command line utility that takes a word document as an argument, and spits out the text from that document (as best as it can figure) to Standard Output. Maybe you can specify an ouput file too. I can't remember the details of how it works. I haven't used it in a while. Not sure if it can handle OO documents.
It's certainly possible to do this, though there is something strange and impenetrable about the OO project and its documentation that makes things like this hard to research and follow. However, OO has the capability to convert all of those types, not just the OO native ones, and it can do it via two different forms of automatic control.
These are the two general approaches.
- You can start OO and tell it to execute a macro which does this job for you for a given file. You then just have to write the macro and a script to loop over your files. The syntax is something like $ oowriter -headless filename macro://dir/Standard.Module1.sMySub
- The other thing OO has is a network API. This is based on something called UNO. $ oowriter -accept=accept-string
Notifies the OpenOffice.org software that upon the creation of "UNO Acceptor Threads", a "UNO Accept String" will be used. You will need some sort of client library. I think they have one for Python at least. Using this technology a Python program or some other scripting language with an OO client library could drive the program and convert all the files. Since OO reads MSO, it should be able to do all of them.