- 4 инструмента для одновременного выполнения команд на нескольких Linux-серверах
- 1. PSSH — Parallel SSH
- 2. Pdsh — Parallel Remote Shell Utility
- 3. ClusterSSH
- 4. Ansible
- Итоги
- MNorin.com
- Блог про Linux, Bash и другие информационные технологии
- Параллельное выполнение в bash
- Использование фонового режима
- Использование пайпа
- Параллельное выполнение и ограничение количества фоновых задач в скрипте
- Похожие посты:
4 инструмента для одновременного выполнения команд на нескольких Linux-серверах
Статья, перевод которой мы сегодня публикуем, посвящена технологиям одновременного выполнения команд на нескольких Linux-серверах. Речь здесь пойдёт о нескольких широко известных инструментах, реализующих подобный функционал. Этот материал пригодится системным администраторам, которым, например, регулярно приходится проверять состояние множества удалённых систем. Предполагается, что у читателя уже имеется несколько серверов, к которым организован доступ по SSH. Кроме того, при одновременной работе с несколькими машинами весьма полезно настроить SSH-доступ к ним по ключу, без пароля. Такой подход, с одной стороны, повышает безопасность сервера, а с другой — облегчает работу с ним.

1. PSSH — Parallel SSH
PSSH — это опенсорсный набор инструментов командной строки, написанный на Python и предназначенный для параллельного выполнения SSH-команд на множестве Linux-систем. Он быстро работает и лёгок в освоении. PSSH включает в себя такие средства, как parallel-ssh , parallel-scp, parallel-rsync , parallel-slurp и parallel-nuke (подробности об этих средствах можно посмотреть в man).
Перед установкой parallel-ssh в Linux-системе сначала надо установить pip . Вот как это делается в разных дистрибутивах:
$ sudo apt install python-pip python-setuptools #Debian/Ubuntu # yum install python-pip python-setuptools #RHEL/CentOS # dnf install python-pip python-setuptools #Fedora 22+Затем parallel-ssh устанавливают с использованием pip :
$ sudo pip install parallel-sshДалее, нужно внести имена хостов или IP-адреса удалённых Linux-серверов и сведения о портах в файл hosts (на самом деле, назвать его можно как угодно). Тут нам пригодится такая команда:
Вот пример содержимого такого файла:
192.168.0.10:22 192.168.0.11:22 192.168.0.12:22После того, как в файл будет внесено всё необходимое, пришло время запустить parallel-ssh , передав этой утилите имя файла с использованием опции -h , а также — команды, которые нужно выполнить на всех серверах, адреса которых имеются в файле hosts . Флаг -i утилиты используется для того, чтобы вывести на экран то, что попадёт в стандартные потоки вывода и ошибок после завершения выполнения команд на серверах.
Команда запуска parallel-ssh может выглядеть так:
$ parallel-ssh -h hosts "uptime; df -h"На следующем рисунке показано использование утилиты при работе с тремя серверами.

Утилита parallel-ssh выполняет команды на нескольких серверах
2. Pdsh — Parallel Remote Shell Utility
Pdsh — это, опять же, опенсорсное решение, представляющее собой оболочку для одновременного выполнения команд на нескольких Linux-серверах.
Вот как установить pdsh в различных дистрибутивах:
$ sudo apt install pdsh #Debian/Ubuntu # yum install pdsh #RHEL/CentOS # dnf install pdsh #Fedora 22+Для того чтобы выполнять команды на нескольких серверах, адреса этих серверов, как и при использовании parallel-ssh , надо добавить в файл, который тоже можно назвать hosts . Затем нужно запустить pdsh в следующем виде:
$ pdsh -w ^hosts -R ssh "uptime; df -h"Здесь флаг -w используется для указания файла со списком серверов, флаг -R применяется для указания модуля удалённых команд (среди доступных модулей удалённых команд имеются ssh , rsh , exec ; по умолчанию используется rsh ). Обратите внимание на значок ^ перед именем файла со списком серверов.
Вот как выглядит работа с этой командой.
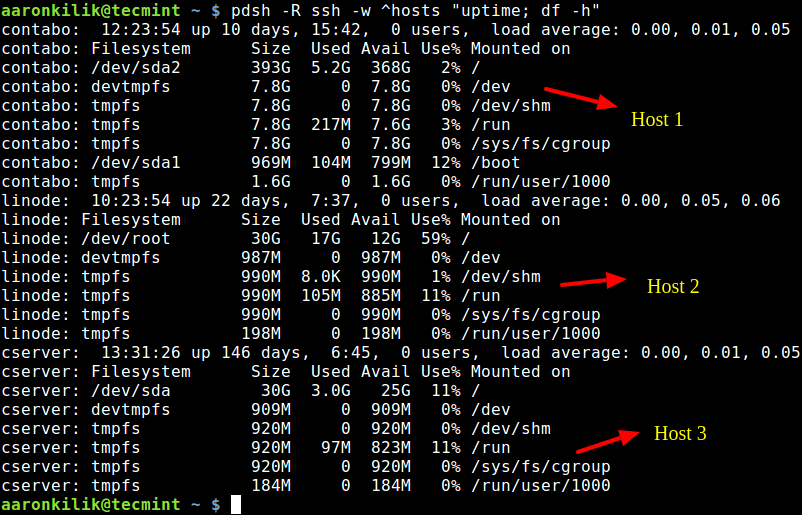
Выполнение команд на нескольких серверах с использованием pdsh
Если вы, при вызове pdsh , не указали список команд, которые надо выполнить на серверах, эта утилита запустится в интерактивном режиме. Подробности о pdsh можно узнать на соответствующей странице man.
3. ClusterSSH
ClusterSSH — это инструмент командной строки, предназначенный для администрирования кластеров серверов. Он запускает консоль администратора и, для каждого сервера, отдельное окно xterm . После этого на всех этих серверах можно одновременно выполнять одни и те же команды.
$ sudo apt install clusterssh #Debian/Ubuntu # yum install clusterssh #RHEL/CentOS $ sudo dnf install clusterssh #Fedora 22+Теперь, для подключения к серверам, нужно выполнить команду следующего вида:
$ clusterssh linode cserver contaboМожно воспользоваться и такой конструкцией:
$ clusterssh username@server1 username@server2 username@server3После этого вы увидите нечто, подобное тому, что показано на следующем рисунке.
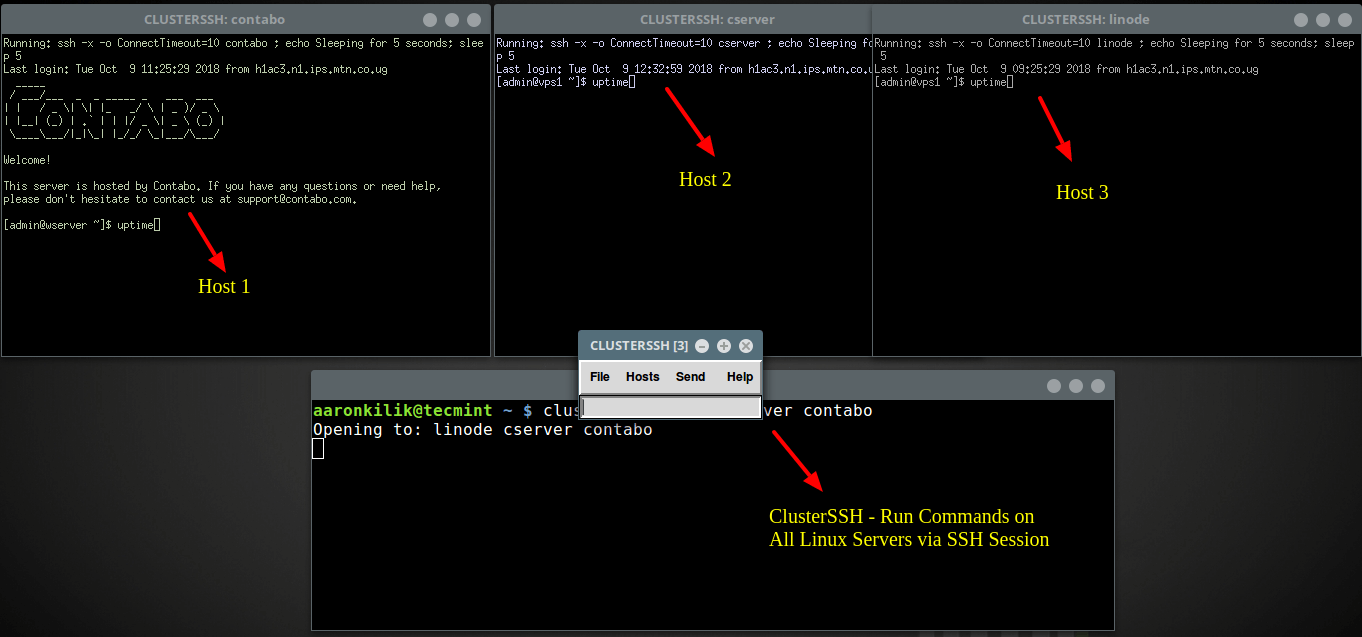
Работа с несколькими серверами с помощью clusterssh
Команды, введённые в консоли администратора, выполняются на всех серверах. Для выполнения команд на отдельном сервере нужно вводить их в окне, открытом для него.
4. Ansible
Ansible — это популярный опенсорсный инструмент для автоматизации IT-процессов. Он используется для настройки систем и для управления ими, для установки приложений и для решения других задач.
$ sudo apt install ansible #Debian/Ubuntu # yum install ansible #RHEL/CentOS $ sudo dnf install ansible #Fedora 22+После этого надо добавить адреса серверов в файл /etc/ansible/hosts .
Вот пример фрагмента подобного файла с несколькими системами, объединёнными в группу webservers :
# Ex 2: A collection of hosts belonging to the 'webservers' group [webservers] 139.10.100.147 139.20.40.90 192.30.152.186Теперь, для того, чтобы получить сведения команды uptime и узнать, какие пользователи подключены к хостам, входящим в группу webservers , можно воспользоваться следующей конструкцией:
$ ansible webservers -a "w " -u adminЗдесь опция -a используется для указания аргументов, передаваемых модулю, а флаг -u позволяет задать имя пользователя по умолчанию, применяемое для подключения к удалённым серверам по SSH.
Обратите внимание на то, что интерфейс командной строки ansible позволяет выполнять команды лишь по одной.
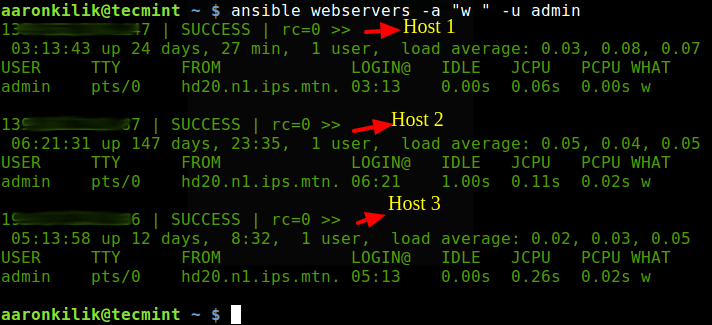
Взаимодействие с несколькими серверами средствами ansible
Итоги
В этом материале мы рассказали об инструментах, которые предназначены для одновременного выполнения команд на нескольких серверах, работающих под управлением Linux. Если вы подумываете об автоматизации задач по управлению множеством серверов — надеемся, вы найдёте здесь что-нибудь такое, что вам подойдёт.
Уважаемые читатели! Знаете ли вы о каких-нибудь полезных утилитах, упрощающих администрирование большого количества серверов?

MNorin.com
Блог про Linux, Bash и другие информационные технологии
Параллельное выполнение в bash

В большинстве командных оболочек команды выполняются по умолчанию последовательно. И это, в принципе, нормально. Потому что человек с системой взаимодействует последовательно, обычно нет необходимости несколько команд выполнять параллельно. Bash в этом смысле тоже не исключение. Но при автоматизации возможность параллельного выполнения может быть полезной. Давайте посмотрим, как организовать параллельное выполнение в bash.
Использование фонового режима
Для организации параллельной работы нескольких программ часто используется запуск в фоновом режиме при помощи знака амперсанда — &. Например:
Команда будет работать в фоне, при этом из текущей оболочки можно выполнять команды. Таким образом уже можно распараллелить какие-то действия. Можно запустить сразу несколько команд таким образом и дождаться, пока они все отработают. Для ожидания запущенных дочерних процессов используется команда wait. Эта команда без параметров ожидает окончания работы всех дочерних процессов, соответственно, для ожидания окончания 5 процессов понадобится выполнить команду всего 1 раз. В принципе, это легко реализуется через цикл. Например, так:
for i in do # запуск одного фонового процесса sleep 10 && echo $i & done # ожидание окончания работы wait echo Finished
И результат работы этого скрипта:
$ ./wait5.sh 1 5 4 2 3 Finished
Как видите, с виду одинаковые команды завершились не в том порядке, в котором мы их запустили. Давайте посмотрим теперь общее время выполнения скрипта.
$ time ./wait5.sh 4 5 2 3 1 Finished real 0m10.029s user 0m0.000s sys 0m0.008s
Общее время работы скрипта чуть больше 10 секунд, что доказывает, что наши команды выполнились параллельно, а увеличение времени выполнения говорит о том, что они были запущены не в одно и то же время, были небольшие таймауты между запусками. Но они были очень маленькими, поэтому такой запуск пяти процессов занимает практически такое же время, как запуск одного.
Использование пайпа
При использовании пайпов, которые перенаправляют вывод одной программы на вход другой, процессы выполняются параллельно. Отсюда вытекает еще один способ параллельного выполнения нескольких команд — перенаправить между ними какие-то данные с помощью пайпа. Например:
program1 | program2 | program3
Тут важно помнить вот что: если вам не нужно передавать реально какие-то данные между программами, то надо предварительно убедиться, что входные данные эти программы получат в виде опций командной строки и не будут использовать те данные, которые были переданы им с помощью пайпа. Хотя здесь, в принципе, возможен такой вариант:
command1 --option > dev/null | command2 param1 param2 > /dev/null | command3
Этот вариант до использования в скриптах, естественно, нужно обязательно проверить в ручном режиме и посмотреть в страницах руководств используемых программ (если там есть такая информация), что имеет больший приоритет — опции командной строки или стандартный поток ввода, потому что некоторые программы могут игнорировать командную строку, если данные передаются через стандартный поток ввода.
Параллельное выполнение и ограничение количества фоновых задач в скрипте
Давайте рассмотрим такую практическую задачу — запустить 100 процессов параллельно, но так, чтобы работало одновременно не более 10 процессов. В общем, достаточно простая задача. Предположим, что все процессы работают произвольное количество времени. Пусть запуск одной задачи будет выглядеть как запуск команды sleep со случайным параметром от 0 до 29. Тогда скрипт будет выглядеть следующим образом:
#!/bin/bash RANDOM=10 JOBS_COUNTER=0 MAX_CHILDREN=10 MY_PID=$$ for i in do echo Cycle counter: $i JOBS_COUNTER=$((`ps ax -Ao ppid | grep $MY_PID | wc -l`)) while [ $JOBS_COUNTER -ge $MAX_CHILDREN ] do JOBS_COUNTER=$((`ps ax -Ao ppid | grep $MY_PID | wc -l`)) echo Jobs counter: $JOBS_COUNTER sleep 1 done sleep $(($RANDOM % 30)) & done echo Finishing children . # wait for children here while [ $JOBS_COUNTER -gt 1 ] do JOBS_COUNTER=$((`ps ax -Ao ppid | grep $MY_PID | wc -l`)) echo Jobs counter: $JOBS_COUNTER sleep 1 done echo Done
Смысл этого скрипта в целом такой: ограничиваем максимально число дочерних фоновых процессов так, чтобы их одновременно было не более 10. Как только один процесс заканчивает свою работу, запускаем следующий. И так далее, пока не выполним 100 фоновых задач. Для порядка отслеживаем в скрипте окончание работы дочерних процессов после запуска последних, только потом заканчиваем работу самого скрипта.
Таким простым способом можно ограничить количество одновременно запущенных фоновых задач в скрипте и при этом отслеживать, сколько из них в данный момент работают. Чтобы было более понятно, запустите скрипт и увидите, когда запускается следующие итерации цикла, и когда изменяется количество дочерних процессов.