- Linux пайпы что такое
- NAME
- DESCRIPTION
- SEE ALSO
- COLOPHON
- Что такое пайп в Linux
- Как работают каналы в Linux
- Синтаксис каналов в Linux
- Как использовать каналы в Linux
- Как использовать канал для отправки списка файлов и каталогов команде «больше» в Linux
- Как использовать канал для отделения файлов из списка всех файлов и каталогов в Linux
- Как использовать канал для подсчета количества определенных файлов из списка всех файлов и каталогов в Linux
- Как использовать конвейер для сортировки файла и печати его уникальных значений в Linux
- Как использовать конвейер для получения определенных данных в Linux
- Как использовать конвейер для печати строк файлов в определенном диапазоне в Linux
- Заключение
Linux пайпы что такое
NAME
pipe - overview of pipes and FIFOs
DESCRIPTION
Pipes and FIFOs (also known as named pipes) provide a unidirectional interprocess communication channel. A pipe has a read end and a write end. Data written to the write end of a pipe can be read from the read end of the pipe. A pipe is created using pipe(2), which creates a new pipe and returns two file descriptors, one referring to the read end of the pipe, the other referring to the write end. Pipes can be used to create a communication channel between related processes; see pipe(2) for an example. A FIFO (short for First In First Out) has a name within the filesystem (created using mkfifo(3)), and is opened using open(2). Any process may open a FIFO, assuming the file permissions allow it. The read end is opened using the O_RDONLY flag; the write end is opened using the O_WRONLY flag. See fifo(7) for further details. Note: although FIFOs have a pathname in the filesystem, I/O on FIFOs does not involve operations on the underlying device (if there is one). I/O on pipes and FIFOs The only difference between pipes and FIFOs is the manner in which they are created and opened. Once these tasks have been accomplished, I/O on pipes and FIFOs has exactly the same semantics. If a process attempts to read from an empty pipe, then read(2) will block until data is available. If a process attempts to write to a full pipe (see below), then write(2) blocks until sufficient data has been read from the pipe to allow the write to complete. Nonblocking I/O is possible by using the fcntl(2) F_SETFL operation to enable the O_NONBLOCK open file status flag. The communication channel provided by a pipe is a byte stream: there is no concept of message boundaries. If all file descriptors referring to the write end of a pipe have been closed, then an attempt to read(2) from the pipe will see end-of-file (read(2) will return 0). If all file descriptors referring to the read end of a pipe have been closed, then a write(2) will cause a SIGPIPE signal to be generated for the calling process. If the calling process is ignoring this signal, then write(2) fails with the error EPIPE. An application that uses pipe(2) and fork(2) should use suitable close(2) calls to close unnecessary duplicate file descriptors; this ensures that end-of-file and SIGPIPE/EPIPE are delivered when appropriate. It is not possible to apply lseek(2) to a pipe. Pipe capacity A pipe has a limited capacity. If the pipe is full, then a write(2) will block or fail, depending on whether the O_NONBLOCK flag is set (see below). Different implementations have different limits for the pipe capacity. Applications should not rely on a particular capacity: an application should be designed so that a reading process consumes data as soon as it is available, so that a writing process does not remain blocked. In Linux versions before 2.6.11, the capacity of a pipe was the same as the system page size (e.g., 4096 bytes on i386). Since Linux 2.6.11, the pipe capacity is 65536 bytes. Since Linux 2.6.35, the default pipe capacity is 65536 bytes, but the capacity can be queried and set using the fcntl(2) F_GETPIPE_SZ and F_SETPIPE_SZ operations. See fcntl(2) for more information. PIPE_BUF POSIX.1 says that write(2)s of less than PIPE_BUF bytes must be atomic: the output data is written to the pipe as a contiguous sequence. Writes of more than PIPE_BUF bytes may be nonatomic: the kernel may interleave the data with data written by other processes. POSIX.1 requires PIPE_BUF to be at least 512 bytes. (On Linux, PIPE_BUF is 4096 bytes.) The precise semantics depend on whether the file descriptor is nonblocking (O_NONBLOCK), whether there are multiple writers to the pipe, and on n, the number of bytes to be written: O_NONBLOCK disabled, n PIPE_BUF All n bytes are written atomically; write(2) may block if there is not room for n bytes to be written immediately O_NONBLOCK enabled, n PIPE_BUF If there is room to write n bytes to the pipe, then write(2) succeeds immediately, writing all n bytes; otherwise write(2) fails, with errno set to EAGAIN. O_NONBLOCK disabled, n > PIPE_BUF The write is nonatomic: the data given to write(2) may be interleaved with write(2)s by other process; the write(2) blocks until n bytes have been written. O_NONBLOCK enabled, n > PIPE_BUF If the pipe is full, then write(2) fails, with errno set to EAGAIN. Otherwise, from 1 to n bytes may be written (i.e., a "partial write" may occur; the caller should check the return value from write(2) to see how many bytes were actually written), and these bytes may be interleaved with writes by other processes. Open file status flags The only open file status flags that can be meaningfully applied to a pipe or FIFO are O_NONBLOCK and O_ASYNC. Setting the O_ASYNC flag for the read end of a pipe causes a signal (SIGIO by default) to be generated when new input becomes available on the pipe (see fcntl(2) for details). On Linux, O_ASYNC is supported for pipes and FIFOs only since kernel 2.6. Portability notes On some systems (but not Linux), pipes are bidirectional: data can be transmitted in both directions between the pipe ends. POSIX.1 requires only unidirectional pipes. Portable applications should avoid reliance on bidirectional pipe semantics.
SEE ALSO
dup(2), fcntl(2), open(2), pipe(2), poll(2), select(2), socketpair(2), splice(2), stat(2), mkfifo(3), epoll(7), fifo(7)
COLOPHON
© 2019 Canonical Ltd. Ubuntu and Canonical are registered trademarks of Canonical Ltd.
Что такое пайп в Linux
В операционных системах на базе Linux Pipe — это тип перенаправления, используемый для передачи стандартного вывода одной команды в пункт назначения или другой команды. Он используется для отправки вывода одного процесса, программы или команды другому процессу, программе или команде для дополнительной обработки. В Linux системы позволяют соединить стандартный вывод или стандартный вывод команды со стандартным вводом или стандартным вводом другой команды. В Linux каналы представлены с помощью символа «|«Дудочник».
Канал соединяет два или более процессов, программ или команд на ограниченное время. Для дополнительной обработки в системе Linux используется программа командной строки, известная как фильтры. Прямое соединение, которое создается между несколькими процессами, командами и программами, позволяет им работать одновременно. Однако каналы также позволяют передавать данные между ними, минуя экран дисплея или временные текстовые файлы.
Как работают каналы в Linux
Данные перемещаются слева направо по каналам, поэтому каналы являются однонаправленными. Использование каналов в терминале Linux имеет много преимуществ. Вы можете сгруппировать множество программ, используя каналы для создания очень мощных команд. Большинство программ командной строки поддерживают несколько режимов работы. Эти программы могут записывать и читать данные в файлы и принимать стандартный ввод и вывод. Этот оператор заявляет, что вывод одной программы может использоваться как ввод для другой. Затем вы можете отправить вывод второй программы в качестве ввода в третью программу или сохранить его в файл. Так работают конвейеры в операционной системе на базе Linux.
Синтаксис каналов в Linux
Персонаж трубы «|”Используется для добавления канала в команду. Общий синтаксис каналов в Linux следующий:
$ первая_команда | вторая_команда | третья_команда.. .
Запишите первая_команда в терминале; затем укажите вертикальную черту «|”. После этого добавьте вторая_команда. До этого момента конвейер будет отправлять стандартный вывод first_command в качестве ввода для second_command. Каналы можно использовать для генерации цепочки команд. Однако функциональность каналов останется во всей цепочке команд.
Как использовать каналы в Linux
В терминале Linux каналы представлены с помощью символа «|«Дудочник». Теперь мы напишем несколько команд, содержащих конвейеры, для практического объяснения работы конвейеров в Linux.
Примечание: Для демонстрации примеров каналов мы используем Ubuntu 20.04. Однако каналы работают одинаково во всех системах на базе Linux.
Как использовать канал для отправки списка файлов и каталогов команде «больше» в Linux
В этом примере мы будем использовать вертикальную черту между «ls» а также «более»Команды. Значок «ls»Используется для вывода списка каталогов и файлов, а опция« -l »добавляется для их вывода в длинном формате. В то время как «более”Команда отобразит список с возможностью прокрутки, по одному экрану за раз:
Выполнение указанной выше команды отправит список файлов и каталогов в качестве входных данных в «более»Команда с использованием вертикальной черты«|”:
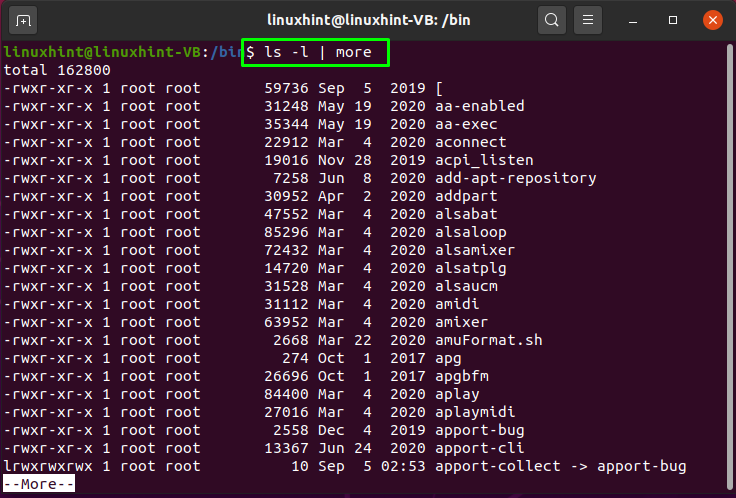
Теперь нажмите «Входить»Просмотреть другие каталоги и файлы списка:


Как использовать канал для отделения файлов из списка всех файлов и каталогов в Linux
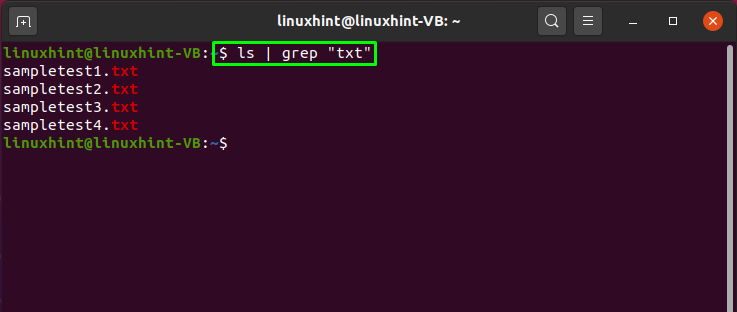
Канал также предоставляет вам возможность отделять и перечислять определенные файлы из списка. Для этого вы можете использовать значок «ls»Для вывода списка файлов и«grep»Для поиска определенного шаблона и добавить« | » вертикальная черта между этими командами.
В приведенном ниже примере вертикальная черта отправляет список файлов и каталогов в папку «grepКоманда. Затем команда grep извлечет файл с меткой «текст»Узор в них:
Как использовать канал для подсчета количества определенных файлов из списка всех файлов и каталогов в Linux
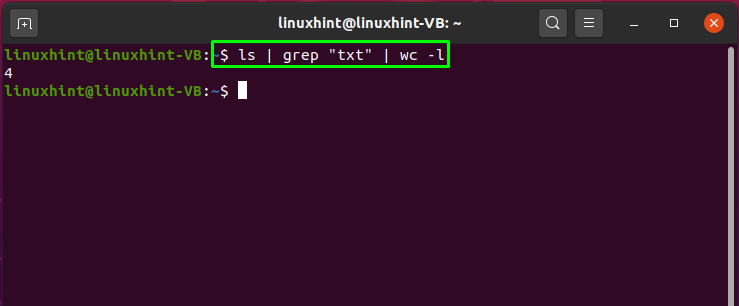
Вы можете использовать каналы для создания цепочки команд. Эта цепочка команд сразу выполняется в терминале Linux. Например, мы можем расширить ранее выполненную команду, добавив вертикальную черту и «ТуалетКоманда. Второй канал отправит вывод «grep«Команда для»Туалет”.
Вывод команды распечатает общее количество файлов, содержащих «текст» шаблон:
Как использовать конвейер для сортировки файла и печати его уникальных значений в Linux
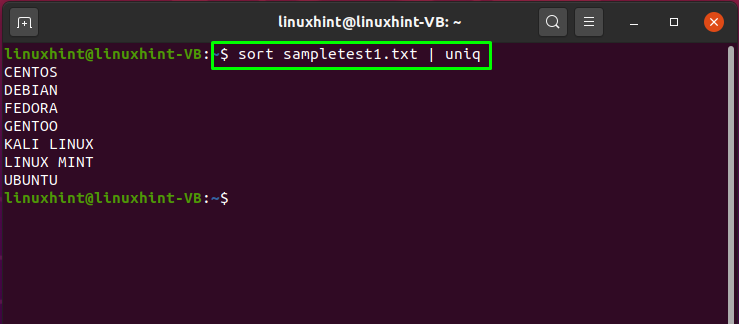
Если вы хотите отсортировать файл, а затем распечатать его уникальные значения в терминале, выполните следующую команду:
$ Сортировать sampletest1.txt | уникальный
Здесь значок «Сортировать»Используется для сортировки«sampletest1.txt» файл. Труба «|» отправляет «СортироватьВывод команды на «уникальный“. Затем значок «уникальный”Команда отфильтрует повторяющиеся значения:
Как использовать конвейер для получения определенных данных в Linux
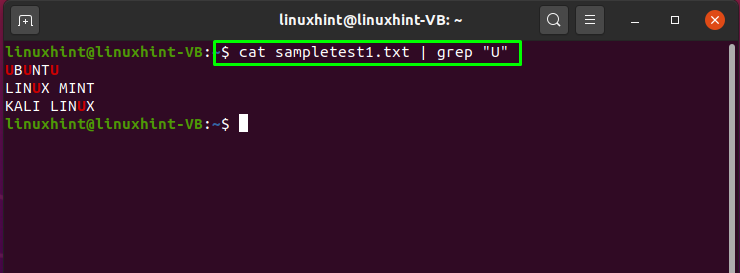
Вы можете использовать трубу «|»Между командой cat и grep. Значок «Кот»Команда извлечет данные из«sampletest1.txt», Тогда как«grep«Команда будет искать»U«Письмо в»sampletest1.txt» содержание. Для дальнейшей обработки труба «|«Отправит»КотВывод команды на «grep”:
$ Кот sampletest1.txt | grep «U»
На выходе вы увидите текст с буквой «U»:
Как использовать конвейер для печати строк файлов в определенном диапазоне в Linux
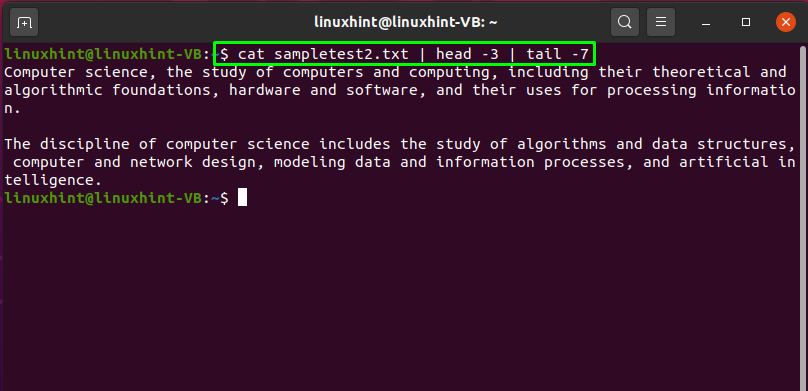
“голова» а также «хвост»Команды используются для печати первой и последней части файла. В этом примере мы будем использовать трубу «|«, Чтобы получить»sampletest2.txt«Данные файла получены из»Кот», А затем передайте ее команде«голова» а также «хвост”В качестве входных данных:
$ Кот sampletest2.txt | голова -3 | хвост -7
Он покажет вам приведенный ниже результат:
Заключение
В Системы на базе Linux, конвейер используется для объединения двух или более команд таким образом, что выходные данные одной команды передаются в качестве входных данных другой. Знак «|» символ обозначает оператора трубы. С помощью оператора конвейера каждый выход процесса напрямую передается в качестве входных данных для следующей команды. В этом посте вы узнали что такое оператор канала в Linux. Кроме того, мы также продемонстрировали различные примеры, связанные с конвейерами в системе Linux.