- How can I extract pages containing a given string from a PDF file?
- 1 Answer 1
- How to extract pages from a PDF in Linux
- How to extract PDF pages in Linux via GUI:
- Step 1:
- Step 2:
- Step 3:
- Step 4:
- Step 5:
- Step 6:
- How to extract PDF pages in Linux via terminal:
- Conclusion:
- About the author
- Sam U
- Extract a page from a pdf flle
- 4 Answers 4
- pdftk
- Split PDF document from command line in Linux?
How can I extract pages containing a given string from a PDF file?
I have a PDF file containing 100 pages. I would like to extract those pages containing a particular string. How can I achieve this? Maybe by using ghostscript on the command line? For what it’s worth: I am using Edubuntu 12.04 LTS.
Is there a specific reason why it has to be using Ghostscript? Because if you lose that requirement you could accomplish this quite easily with pdfgrep and pdftk . E.g.: Find $string in PDF with pdfgrep -n «$string» «$pdf» . Then extract the page numbers in front of the colon (e.g. 1 2 3 4 5 6), remove the duplicates and pass them on to pdftk «$pdf» cat 1 2 3 4 5 6 output extracted_pages.pdf . It shouldn’t be too difficult to compose a script if you are familiar with bash.
1 Answer 1
Here’s a script I quickly put together which should do the job. Make sure to read the preamble and the comments for information on how to use the script and how it works.
#!/bin/bash # NAME: extract_pdf_results # VERSION: 0.1 # AUTHOR: (c) 2014 Glutanimate # DESCRIPTION: Extracts PDF pages that contain supplied string and concatenates them to a new file. # FEATURES: # DEPENDENCIES: pdfgrep pdftk # ➥install on Ubuntu/Debian with sudo apt-get install pdfgrep pdftk # # LICENSE: GNU GPLv3 (http://www.gnu.de/documents/gpl-3.0.en.html) # # NOTICE: THERE IS NO WARRANTY FOR THE PROGRAM, TO THE EXTENT PERMITTED BY APPLICABLE LAW. # EXCEPT WHEN OTHERWISE STATED IN WRITING THE COPYRIGHT HOLDERS AND/OR OTHER PARTIES # PROVIDE THE PROGRAM “AS IS” WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESSED OR # IMPLIED, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY # AND FITNESS FOR A PARTICULAR PURPOSE. THE ENTIRE RISK AS TO THE QUALITY AND # PERFORMANCE OF THE PROGRAM IS WITH YOU. SHOULD THE PROGRAM PROVE DEFECTIVE, # YOU ASSUME THE COST OF ALL NECESSARY SERVICING, REPAIR OR CORRECTION. # # IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING WILL ANY # COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MODIFIES AND/OR CONVEYS THE PROGRAM AS # PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES, INCLUDING ANY GENERAL, SPECIAL, # INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING OUT OF THE USE OR INABILITY TO USE # THE PROGRAM (INCLUDING BUT NOT LIMITED TO LOSS OF DATA OR DATA BEING RENDERED # INACCURATE OR LOSSES SUSTAINED BY YOU OR THIRD PARTIES OR A FAILURE OF THE # PROGRAM TO OPERATE WITH ANY OTHER PROGRAMS), EVEN IF SUCH HOLDER OR OTHER # PARTY HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES. # # USAGE: extract_pdf_results STRING="$1" FILE="$2" FILENAME="$)" BASENAME="$" DIRNAME="$" echo "Processing $FILE. " ## find pages that contain string, remove duplicates, convert newlines to spaces echo "Looking for $STRING. " PAGES="$(pdfgrep -n "$STRING" "$FILE" | cut -f1 -d ":" | uniq | tr '\n' ' ')" echo "Matching pages: $PAGES" ## extract pages to new file in original directory echo "Extracting result pages. " pdftk "$FILE" cat $PAGES output "$/$_pages_with_$.pdf" echo "Done." ./extract_pdf_results.sh Lagrange ./test.pdf Processing ./test.pdf. Looking for Lagrange. Matching pages: 3 Extracting result pages. Done. How to extract pages from a PDF in Linux
![]()
If you are a keen book reader, it would be quite difficult for you to carry even more than two books. That’s no more the case, thanks to ebooks that save a lot of space in your home and your bag as well. Carrying hundreds of books with you is literally no more a dream.
Ebooks come in different formats, but the common one is PDF. Most of the ebook PDFs have hundreds of pages, and just like real books, with the help of a PDF reader navigating these pages is quite easy.
Suppose you are reading a PDF file and want to extract some specific pages from it and save it as a separate file; how would you do that? Well, it is a cinch! No need to get premium applications and tools to accomplish it.
This guide focuses on extracting a specific part from any PDF file and saving it with a different name in Linux. Though there are multiple ways to do this, I will be focusing on the less cluttered approach. So, let’s begin:
There are two main approaches:
You can follow any method according to your convenience.
How to extract PDF pages in Linux via GUI:
This method is more like a trick for extracting pages from a PDF file. Most of the Linux distributions come with a PDF reader. So, let’s learn a step by step process of extracting pages using the default PDF reader of Ubuntu:\
Step 1:
Simply open your PDF file in the PDF reader. Now click on the menu button and as shown in the following image:
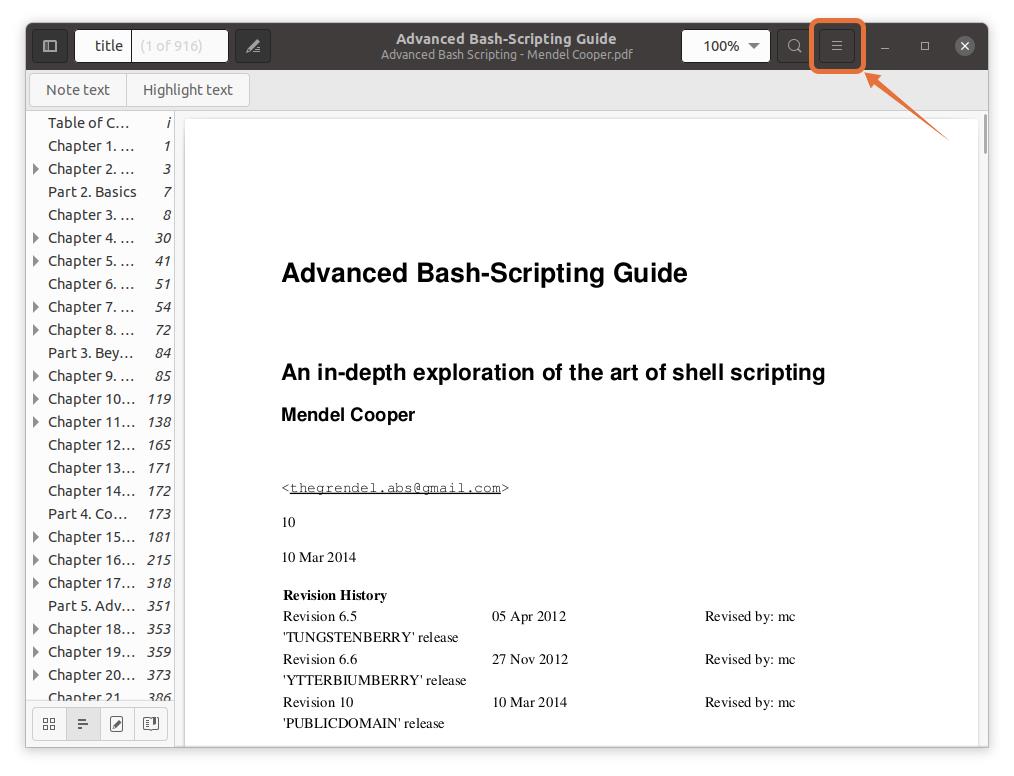
Step 2:
A menu will appear; now click on the “Print” button, a window will come out with print options. You can also use the shortcut keys “ctrl+p” to quickly get this window:
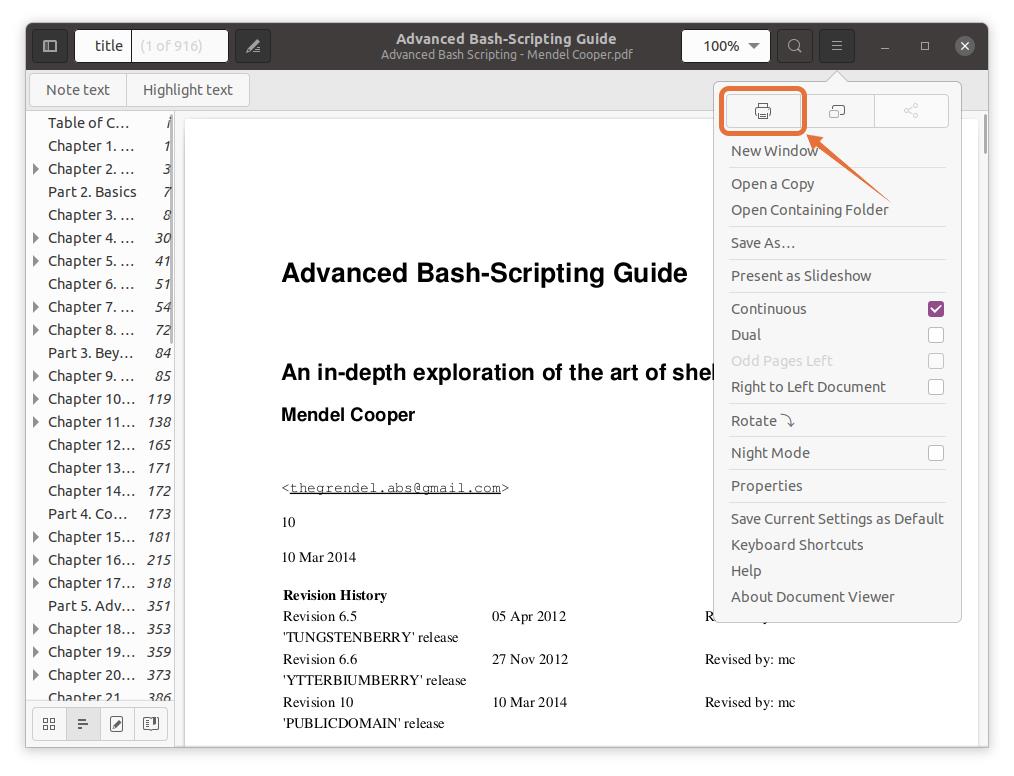
Step 3:
To extract pages in a separate file, click on the “File” option, a window will open, give the file name, and select a location to save it:
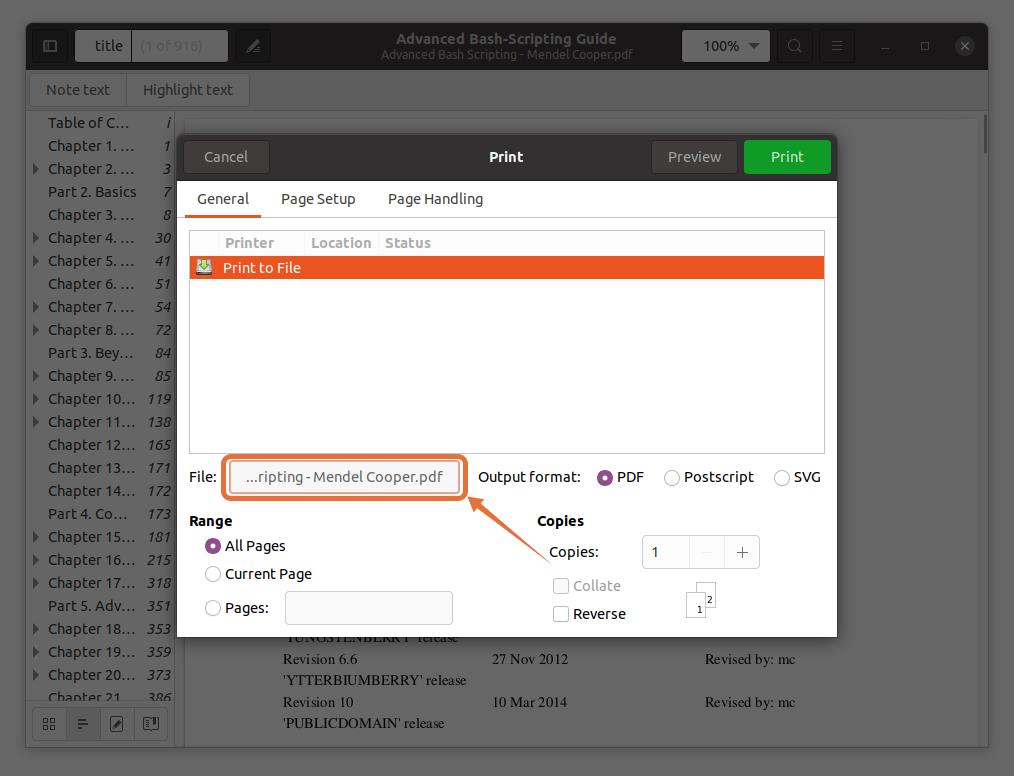
I am selecting “Documents” as the destination location:
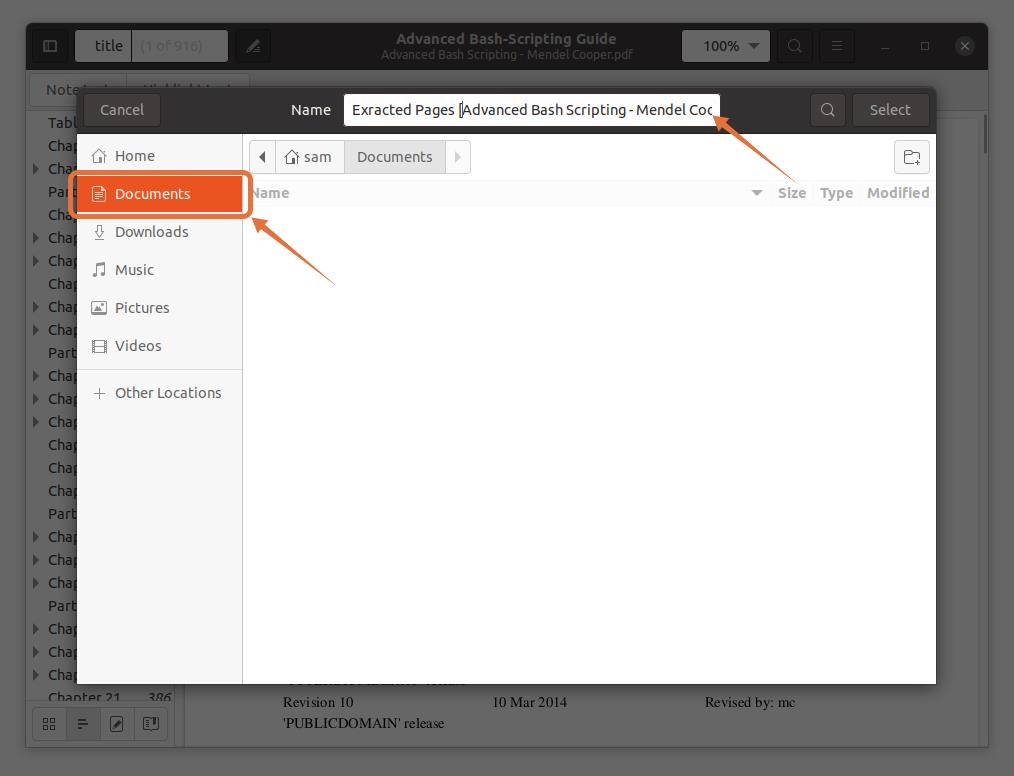
Step 4:
These three output formats PDF, SVG, and Postscript check PDF:
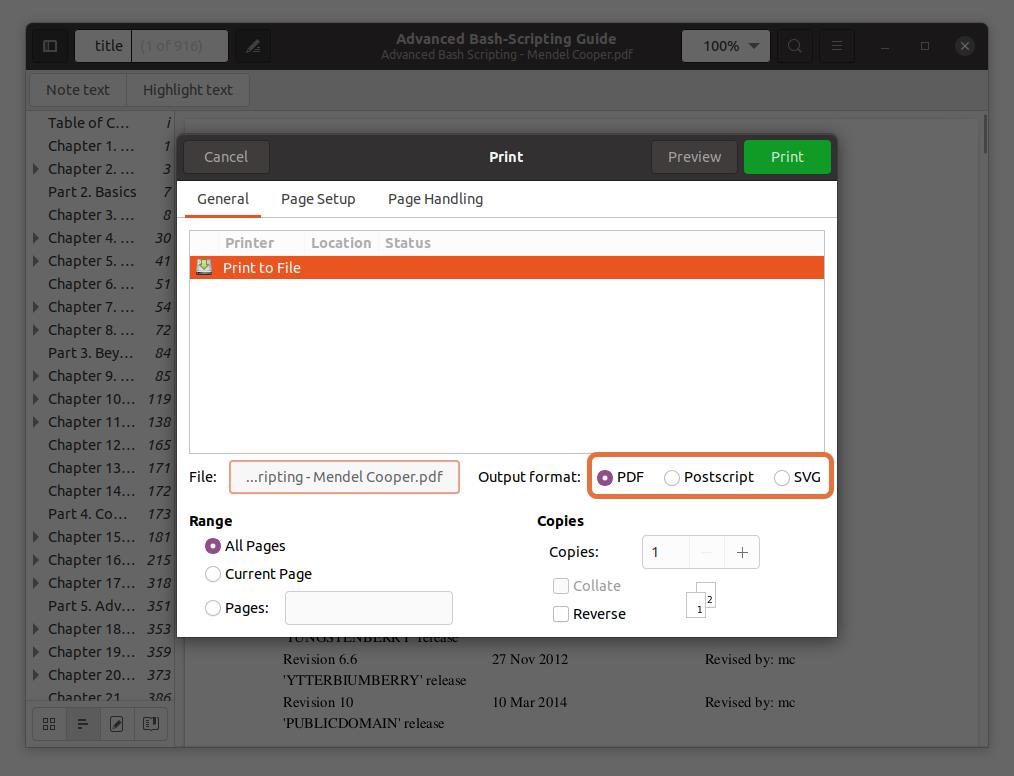
Step 5:
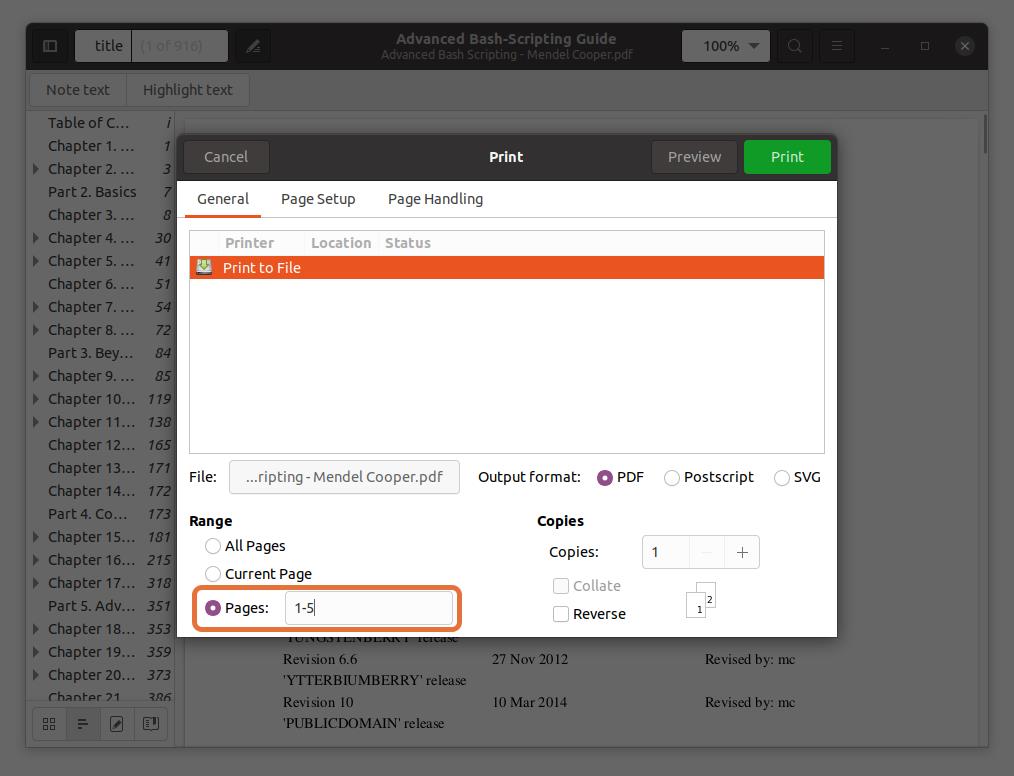
In the “Range” section, check the “Pages” option and set the range of page numbers you want to extract. I am extracting the first five pages so that I would type “1-5”.
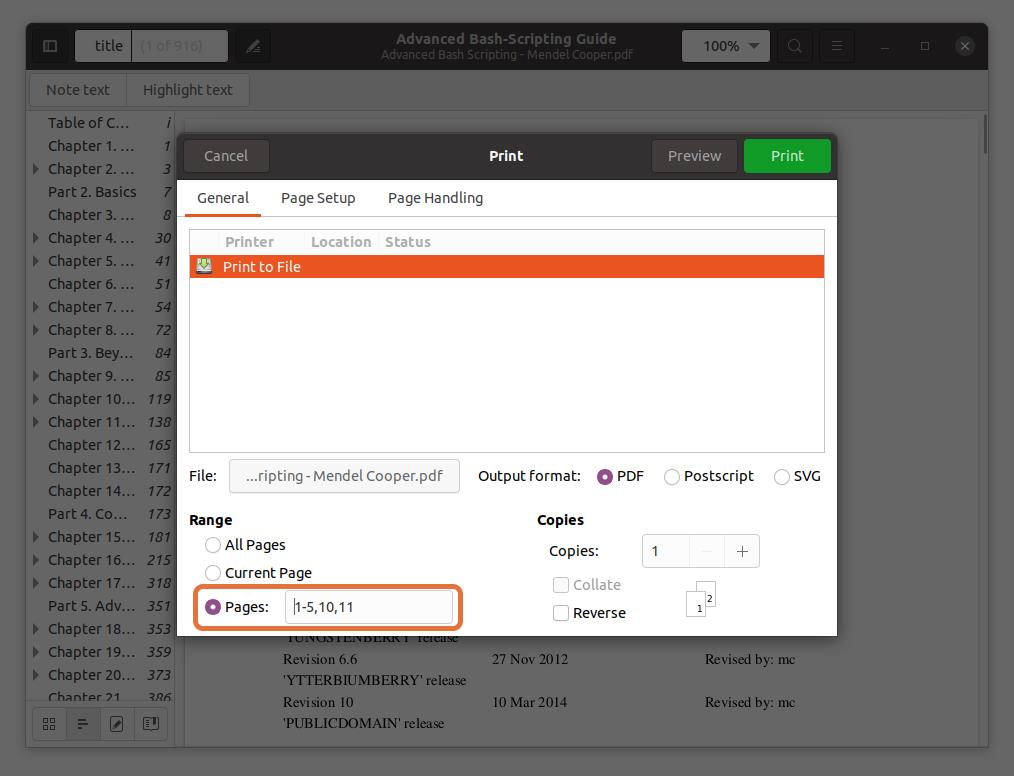
You can also extract any page from the PDF file by typing the page number and separating it by a comma. I am extracting pages number 10 and 11 along with a range for the first five pages.
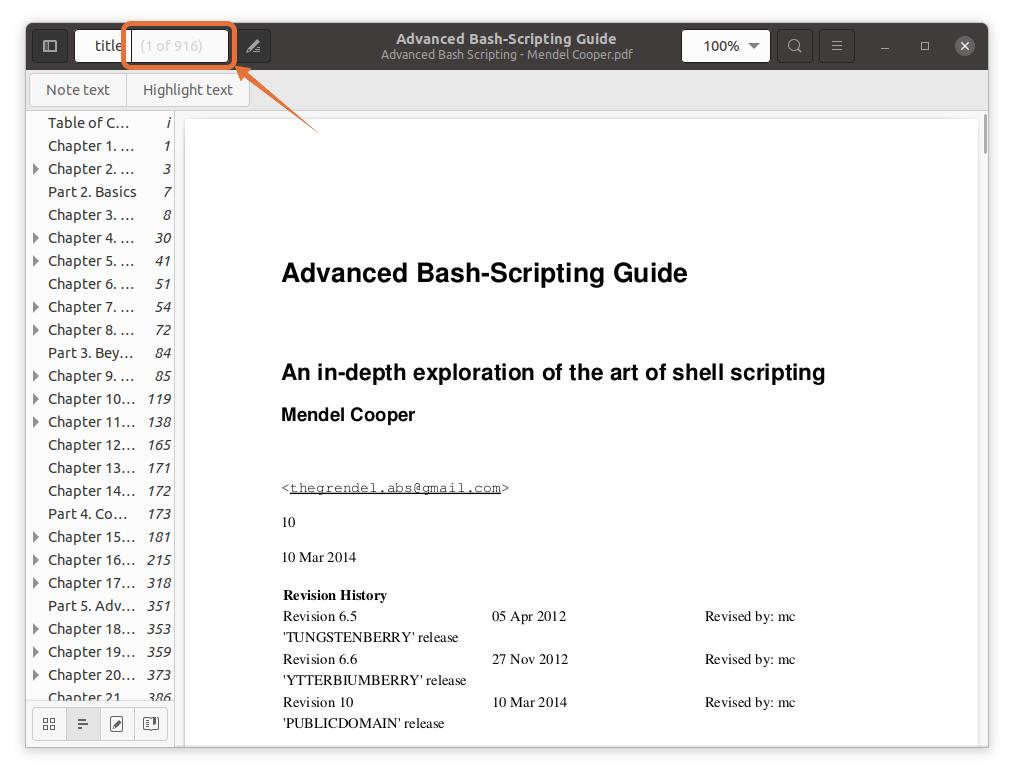
Note that the page numbers I am typing are according to the PDF reader, not the book. Ensure that you enter the page numbers that the PDF reader indicates.
Step 6:
Once all the settings are done, click on the “Print” button, the file will be saved in the specified location:
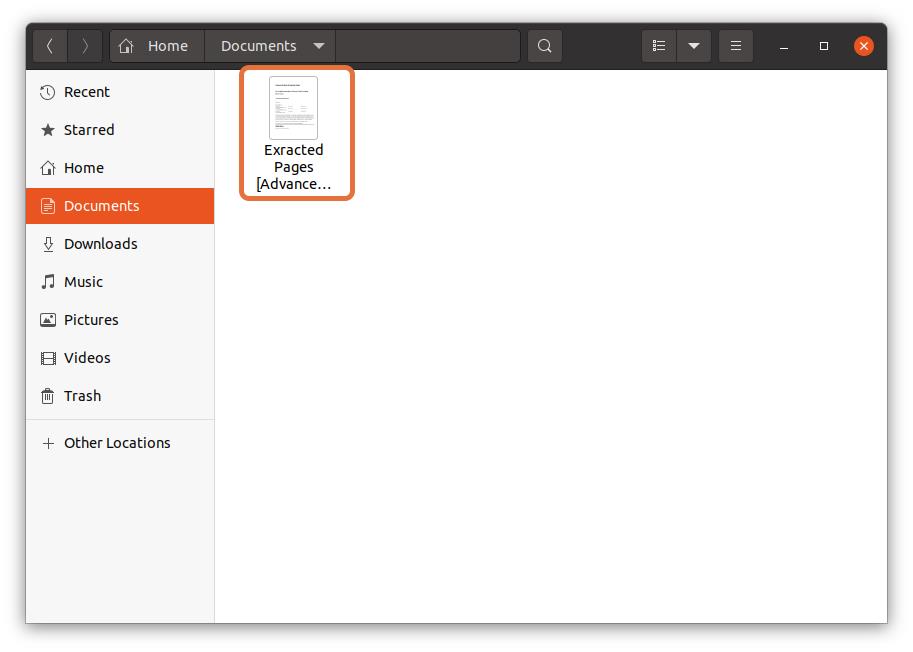
How to extract PDF pages in Linux via terminal:
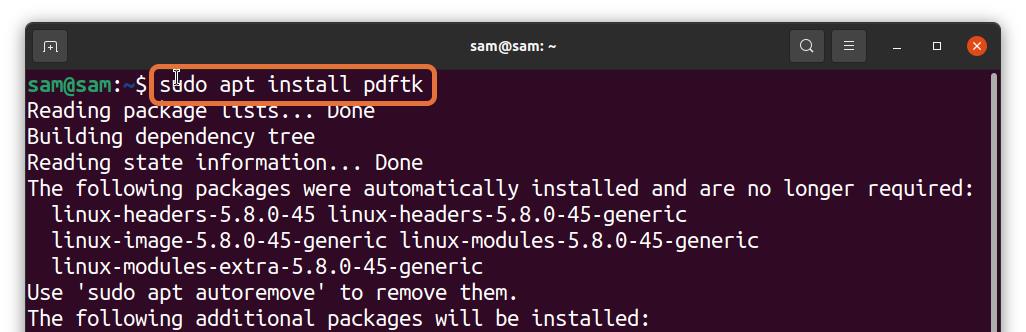
Many Linux users prefer to work with the terminal, but can you extract PDF pages from the terminal? Absolutely! It can be done; all you need a tool to install called PDFtk. To get PDFtk on Debian and Ubuntu, use the command given below:
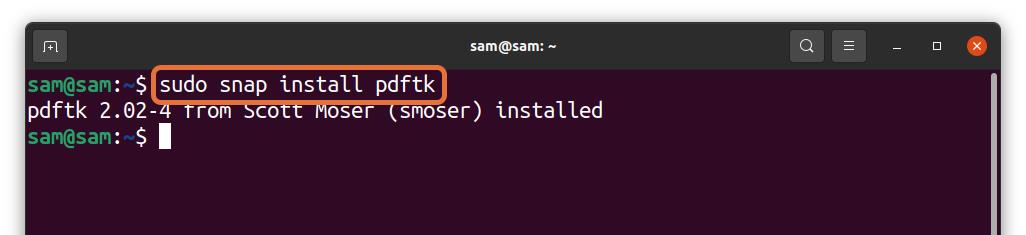
PDFtk can also be installed through snap:
Now, follow the below-mentioned syntax to use PDFtk tool for extracting pages from a PDF file:
- [sample.pdf] – Replace it with the file name from where you want to extract pages.
- [page_numbers] – Replace it with the range of page numbers, for example, “3-8”.
- [output_file_name.pdf] – Type the name of the output file of extracted pages.
Let’s understand it with an example:
$pdftk adv_bash_scripting.pdf cat 3 — 8 output
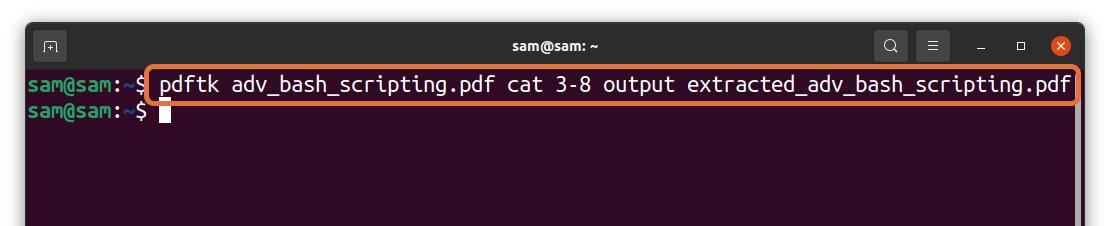
In the above command, I am extracting 6 pages (3 – 8) from a file “adv_bash_scripting.pdf” and saving extracted pages by the name of “extracted_adv_bash_scripting.pdf.” The extracted file will be saved in the same directory.
If you need to extract a specific page, then type the page number and separate them by a “space”:
$pdftk adv_bash_scripting.pdf cat 5 9 11 output

In the above command, I am extracting page numbers 5, 9, and 11 and saving them as “extracted_adv_bash_scripting_2”.
Conclusion:
You may occasionally need to extract some specific portion of a PDF file for several purposes. There are many ways to do it. Some are complex, and some are obsolete. This write-up is about how to extract pages from a PDF file in Linux through two simple methods.
The first method is a trick to extract a certain part of a PDF through Ubuntu’s default PDF reader. The second method is via terminal since many geeks prefer it. I used a tool called PDFtk to extract pages from a pdf file through the use of commands. Both methods are simple; you can choose any according to your convenience.
About the author
Sam U
I am a professional graphics designer with over 6 years of experience. Currently doing research in virtual reality, augmented reality and mixed reality.
I hardly watch movies but love to read tech related books and articles.
Extract a page from a pdf flle
Both your command lines work for me, and the second matches @ajgringo619’s comment. Try adding —verbose to the second one? Try page 1?
4 Answers 4
The magic combination of options is qpdf —empty —pages infile.pdf 1-5 — outfile.pdf .
On Ubuntu I use Evince for PDFs, and I use the normal print dialog for extracting pages. In the printer selection, I have an option «Print to file». Then there is the field where I can enter which pages I want to be «printed». The result is a saved .pdf file.
Both your command lines should work, try adding —verbose to the second one ( qpdf —verbose 0092434747.pdf —pages . 10 — mtg.pdf ) to see why it’s failing. They name a primary input file, so as the qpdf docs say «Document-level information, such as outlines, tags, etc., is taken from the primary input file». A ‘dot’ works as a file name because «You can use . as a shorthand for the primary input file, if not empty,»
If you don’t want any document information from your input file, you can start with an empty file and select page(s) from your input file:
qpdf --empty --pages infile.pdf 10 -- outfile.pdf Be careful, qpdf will overwrite existing files without warning, so work with a copy of your file(s) unless you’re sure what you’re doing.
pdftk
For your case would be pdftk input.pdf cat 10-10 output output.pdf .
# tldr:pdftk # pdftk # PDF toolkit. # More information: . # Extract pages 1-3, 5 and 6-10 from a PDF file and save them as another one: pdftk input.pdf cat 1-3 5 6-10 output output.pdf # Merge (concatenate) a list of PDF files and save the result as another one: pdftk file1.pdf file2.pdf . cat output output.pdf # Split each page of a PDF file into a separate file, with a given filename output pattern: pdftk input.pdf burst output out_%d.pdf # Rotate all pages by 180 degrees clockwise: pdftk input.pdf cat 1-endsouth output output.pdf # Rotate third page by 90 degrees clockwise and leave others unchanged: pdftk input.pdf cat 1-2 3east 4-end output output.pdf Split PDF document from command line in Linux?
You (should) know that Pdftk is nothing more than a very old version of iText (a Java-PDF library) compiled with GCJ and extended with some command line functionality.
The keywords in the above statement are «VERY OLD».
$ java -classpath /path/to/Multivalent20091027.jar tool.pdf.Split -page 1 input.pdf Exception in thread "main" java.lang.NoClassDefFoundError: tool/pdf/Split Caused by: java.lang.ClassNotFoundException: tool.pdf.Split at java.net.URLClassLoader$1.run(URLClassLoader.java:202) at java.security.AccessController.doPrivileged(Native Method) at java.net.URLClassLoader.findClass(URLClassLoader.java:190) at java.lang.ClassLoader.loadClass(ClassLoader.java:306) at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:301) at java.lang.ClassLoader.loadClass(ClassLoader.java:247) Could not find the main class: tool.pdf.Split. Program will exit.
Turns out, this is a bit of a tricky software: even if it’s on SourceForge, and says here that
Practical Thought generously provides these tools for free use on the command line
The browser is open source. The document tools are a free bonus and not open source.
All releases of Multivalent linked from the official sourceforge site are missing the tools package.
(edit: there seems to be an old Multivalent version with the tools included, see the SO link; but as it looks somewhat like abandonware, I’d rather not use it)
Finally, I’d like to avoid tools that are essentially front ends for LaTeX like pdfjam.
Are there any options for such a PDF splitting command line tool under Linux?