Как вывести количество ожидающих приёма соединений?
@Hipster по ссылке в вашем вопросе, пример проводится на машине с одной из BSD системой, где есть поддержка опции -L, наверняка вы пробуете (надо бы описать, где пробуете в вопросе) на одной из GNU/Linux системе.
3 ответа 3
вероятно, подразумеваются tcp-соединения, находящиеся в состоянии listen
получить их список можно, например, программой lsof (приведён пример вывода):
$ sudo lsof -n -itcp -stcp:listen COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME sshd 725 root 3u IPv4 104540750 0t0 TCP *:ssh (LISTEN) sshd 725 root 4u IPv6 104540752 0t0 TCP *:ssh (LISTEN) dnsmasq 1969 nobody 6u IPv4 22700 0t0 TCP 192.168.1.1:domain (LISTEN) adb 8882 user 6u IPv4 31077050 0t0 TCP 127.0.0.1:5037 (LISTEN) qemu-syst 10337 libvirt-qemu 17u IPv4 70173191 0t0 TCP 127.0.0.1:5900 (LISTEN) exim4 10685 Debian-exim 3u IPv4 27902129 0t0 TCP 127.0.0.1:smtp (LISTEN) exim4 10685 Debian-exim 4u IPv6 27902130 0t0 TCP [::1]:smtp (LISTEN) cupsd 17961 root 9u IPv6 111981277 0t0 TCP [::1]:ipp (LISTEN) cupsd 17961 root 10u IPv4 111981278 0t0 TCP 127.0.0.1:ipp (LISTEN) чтобы отобрать только сокеты, созданные процессом, запущенном из файла с именем, начинающимся, например, с символов exim , надо добавить опцию -c имя и опцию -a (логическое «и» по отношению к опциям):
$ sudo lsof -n -itcp -stcp:listen -c exim -a COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME exim4 10685 Debian-exim 3u IPv4 27902129 0t0 TCP 127.0.0.1:smtp (LISTEN) exim4 10685 Debian-exim 4u IPv6 27902130 0t0 TCP [::1]:smtp (LISTEN) точное совпадение с именем можно указать с помощью регулярного выражения (см. $ man lsof ):
$ sudo lsof -n -itcp -stcp:listen -c '/^exim4$/' -a . чтобы подсчитать количество строк, можно воспользоваться программой wc с опцией -l , предварительно удалив первую строку, например, программой tail с опцией -n +2 :
$ sudo lsof -n -itcp -stcp:listen -c exim -a | tail -n +2 | wc -l 2 
22 Сен 2017 10:09:57 | 0 comments
Анализ количества tcp-соединений в Debian Linux
Иногда нужно быстро проанализировать количество tcp-соединений как во всей системе, так и по конкретному порту.
Какими способами это можно сделать в Debian Linux ?
1. Анализ соединений на 80 порт с использованием tcpdump:
Вначале пишем в лог-файл 1000 пакетов:
tcpdump -i eth0 -v -n -w attack.log dst port 80 -c 1000
Далее анализируем данные с сортировкой
tcpdump -nr attack.log | awk '' |grep -oE '8\.4\.8\.5' |sort |uniq -c |sort -rn
или сокращенный вариант вывода
tcpdump -nr attack.log | awk '' |grep -oE '8\.5\.6\.4' |sort |uniq -c |sort -rn | head -20
2. Анализ количества tcp-соединений через /proc/net/ip_conntrack
awk '' /proc/net/ip_conntrack | sort | uniq -c | sort -rn | head -25 | column -t
Смотрим количество соединений и с каких IP их больше всего.
3. Анализ количества tcp-соединений через netstat
Общий анализ количества tcp-соединений через netstat:
netstat -npt | awk '' | grep -Eo '(4\.)3' | cut -d: -f1 | sort | uniq -c | sort -nr | head
Общее количество tcp-соединений в разных состояниях:
netstat -npt | awk '' | sort | uniq -c | sort -nr | head
Анализ количества tcp-соединений через netstat на 80 порт в состоянии ESTABLISHED:
netstat -npt | grep 80 | grep ESTABLISHED | awk '' | grep -Eo '(7\.)3' | cut -d: -f1 | sort | uniq -c | sort -nr | head
Анализ количества tcp-соединений через netstat на 80 порт:
netstat -plane | grep :80 | awk | cut -d ':' -f1 | sort -n | uniq -c | sort -rn | head -10
netstat -npt | grep 80 | awk '' | grep -Eo '(9\.)1' | cut -d: -f1 | sort | uniq -c | sort -nr | head
На этом все, до скорых встреч. Если у Вас возникли вопросы или Вы хотите чтобы я помог Вам, то Вы всегда можете связаться со мной разными доступными способами.
Мониторинг сетевого стека linux

Часто мониторинг сетевой подсистемы операционной системы заканчивается на счетчиках пакетов, октетов и ошибок сетевых интерфейсах. Но это только 2й уровень модели OSI!
С одной стороны большинство проблем с сетью возникают как раз на физическом и канальном уровнях, но с другой стороны приложения, работающие с сетью оперируют на уровне TCP сессий и не видят, что происходит на более низких уровнях.
Я расскажу, как достаточно простые метрики TCP/IP стека могут помочь разобраться с различными проблемами в распределенных системах.
Netlink
Почти все знают утилиту netstat в linux, она может показать все текущие TCP соединения и дополнительную информацию по ним. Но при большом количестве соединений netstat может работать достаточно долго и существенно нагрузить систему.
Есть более дешевый способ получить информацию о соединениях — утилита ss из проекта iproute2.
$ time netstat -an|wc -l 62109 real 0m0.467s user 0m0.288s sys 0m0.184s$ time ss -ant|wc -l 62111 real 0m0.126s user 0m0.112s sys 0m0.016sУскорение достигается за счет использования протола netlink для запросов информации о соединениях у ядра. Наш агент использует netlink напрямую.
Считаем соединения
Disclaimer: для иллюстрации работы с метриками в разных срезах я буду показывать наш интерфейс (dsl) работы с метриками, но это можно сделать и на opensource хранилищах.
В первую очередь мы разделяем все соединения на входящие (inbound) и исходящие (outbound) по отношению к серверу.
Каждое TCP соединения в определенный момент времени находится в одном из состояний, разбивку по которым мы тоже сохраняем (это иногда может оказаться полезным):
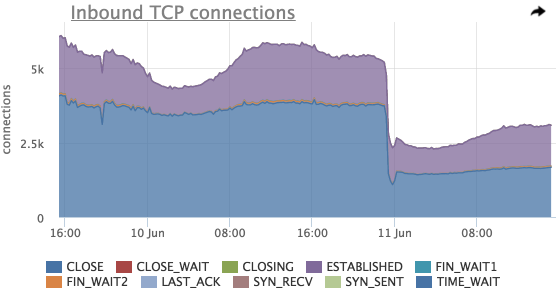
По этому графику можно оценить общее количество входящих соединений, распределение соединений по состояниям.
Здесь так же видно резкое падение общего количества соединений незадолго до 11 Jun, попробуем посмотреть на соединения в разрезе listen портов:

На этом графике видно, что самое значительное падение было на порту 8014, посмотрим только 8014 (у нас в интерфейсе можно просто нажать на нужном элементе легенды):

Попробуем посмотреть, изменилось ли количество входящий соединений по всем серверам?
Выбираем серверы по маске “srv10*”:
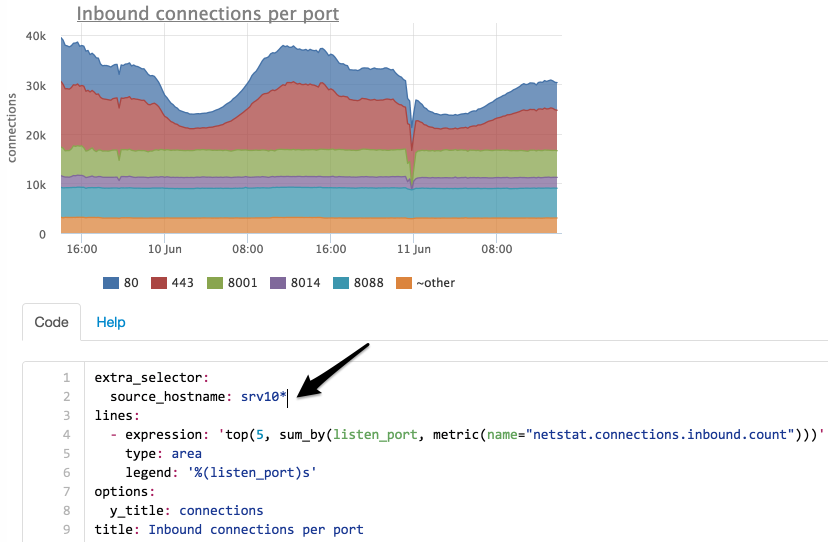
Теперь мы видим, что количество соединений на порт 8014 не изменилось, попробуем найти на какой сервер они мигрировали:

Мы ограничили выборку только портом 8014 и сделали группировку не по порту, а по серверам.
Теперь понятно, что соединения с сервера srv101 перешли на srv102.
Разбивка по IP
Часто бывает необходимо посмотреть, сколько было соединений с различных IP адресов. Наш агент снимает количество TCP соединений не только с разбивкой по listen портам и состояниям, но и по удаленному IP, если данный IP находится в том же сегменте сети (для всех остальный адресов метрики суммируются и вместо IP мы показываем “~nonlocal”).
Рассмотрим тот же период времени, что и в предыдущих случаях:
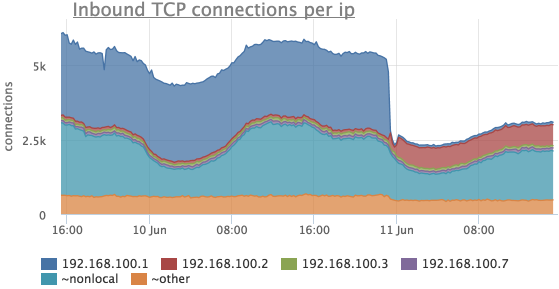
Здесь видно, что соединений с 192.168.100.1 стало сильно меньше и в это же время появились соединения с 192.168.100.2.
Детализация рулит
На самом деле мы работали с одной метрикой, просто она была сильно детализирована, индентификатор каждого экземпляра выглядит примерно так:
Например, у одно из клиентов на нагруженном сервере-фронтенде снимается ~700 экземпляров этой метрики
TCP backlog
По метрикам TCP соединений можно не только диагностировать работу сети, но и определять проблемы в работе сервисов.
Например, если какой-то сервис, обслуживающий клиентов по сети, не справляется с нагрузкой и перестает обрабатывать новые соединения, они ставятся в очередь (backlog).
На самом деле очереди две:
- SYN queue — очередь неустановленных соединений (получен пакет SYN, SYN-ACK еще не отправлен), размер ограничен согласно sysctl net.ipv4.tcp_max_syn_backlog;
- Accept queue — очередь соединений, для которых получен пакет ACK (в рамках «тройного рукопожатия»), но не был выполнен accept приложением (очередь ограничивается приложением)
При достижении лимита accept queue ACK пакет удаленного хоста просто отбрасывается или отправляется RST (в зависимости от значения переменной sysctl net.ipv4.tcp_abort_on_overflow).
Наш агент снимает текущее и максимальное значение accept queue для всех listen сокетов на сервере.
Для этих метрик есть график и преднастроенный триггер, который уведомит, если backlog любого сервиса использован более чем на 90%:

Счетчики и ошибки протоколов
Однажды сайт одного из наших клиентов подвергся DDOS атаке, в мониторинге было видно только увеличение трафика на сетевом интерфейсе, но мы не показывали абсолютно никаких метрик по содержанию этого трафика.
В данный момент однозначного ответа на этот вопрос окметр дать по-прежнему не может, так как сниффинг мы только начали осваивать, но мы немного продвинулись в этом вопросе.
Попробуем что-то понять про эти выбросы входящего трафика:
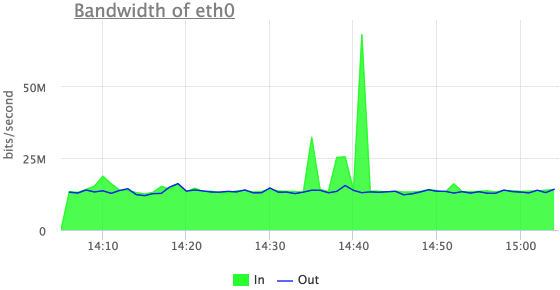

Теперь мы видим, что это входящий UDP трафик, но здесь не видно первых из трех выбросов.
Дело в том, что счетчики пакетов по протоколам в linux увеличиваются только в случае успешной обработки пакета.
Попробуем посмотреть на ошибки:
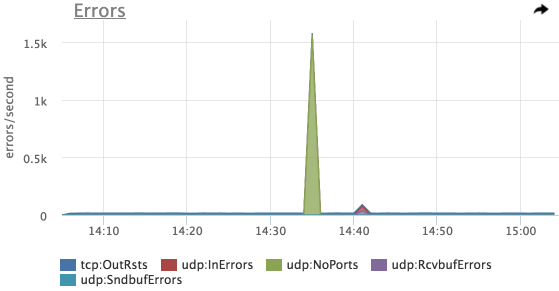
А вот и наш первый пик — ошибки UDP:NoPorts (количество датаграмм, пришедших на UPD порты, которые никто не слушает)
Данный пример мы эмулировали с помощью iperf, и в первый заход не включили на сервер-приемщик пакетов на нужном порту.
TCP ретрансмиты
Отдельно мы показываем количество TCP ретрансмитов (повторных отправок TCP сегментов).
Само по себе наличие ретрансмитов не означает, что в вашей сети есть потери пакетов.
Повторная передача сегмента осуществляется, если передающий узел не получил от принимающего подтверждение (ACK) в течении определенного времени (RTO).
Данный таймаут расчитывается динамически на основе замеров времени передачи данных между конкретными хостами (RTT) для того, чтобы обеспечивать гарантированную передачу данных при сохранении минимальных задержек.
На практике количество ретрансмитов обычно коррелирует с нагрузкой на серверы и важно смотреть не на абсолютное значение, а на различные аномалии:

На данном графике мы видим 2 выброса ретрансмитов, в это же время процессы postgres утилизировали CPU данного сервера:

Cчетчики протоколов мы получаем из /proc/net/snmp.
Conntrack
Еще одна распространенная проблема — переполнение таблицы ip_conntrack в linux (используется iptables), в этом случае linux начинает просто отбрасывать пакеты.
Это видно по сообщению в dmesg:
ip_conntrack: table full, dropping packetАгент автоматически снимает текущий размер данной таблицы и лимит с серверов, использующих ip_conntrack.
В окметре так же есть автоматический триггер, который уведомит, если таблица ip_conntrack заполнена более чем на 90%:
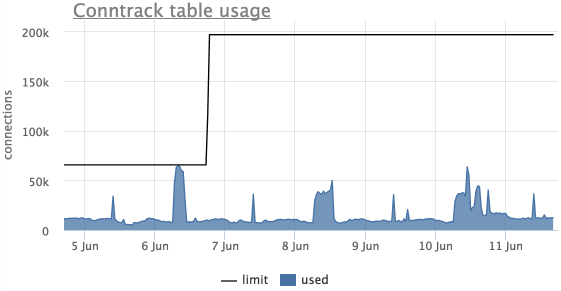
На данном графике видно, что таблица переполнялась, лимит подняли и больше он не достигался.
Вместо заключения
- детализация метрик очень важна
- если где-то что-то может переполниться, нужно обязательно покрывать мониторингом такие места
- мы снимаем еще много разного по TCP/IP (RTT, соединения с непустыми send/recv очередями), но пока не придумали, как c этим правильно работать
Примеры наших стандартных графиков можно посмотреть в нашем демо-проекте.
Там же можно постмотреть графики Netstat.