- Remove empty lines in a text file via grep
- How to Delete Empty Lines in Files Using Grep, Sed, and Awk
- Create a File with Empty/Blank Lines in Linux
- How to Remove Blank/Empty Lines in Files
- 1. Delete Empty Lines Using Grep Command
- 2. Delete Empty Lines Using Sed Command
- 3. Delete Empty Lines Using Awk Command
- remove all empty lines from text files while keeping format
- 3 Answers 3
Remove empty lines in a text file via grep
grep . FILE doesn’t work for me. It’s probably better to stick with grep for searching file contents, and sed for editing file contents.
sed -ne/./p works too, and awk /./ is shorter (action is
For those that don’t understand, the . is a regular expression that matches any character except for newline.
grep . FILE works with the given example, but not necessarily when the file can have bytes not part of the charset. For instance, with GNU grep 2.20, printf «\x80\n» | grep . outputs nothing.
«grep» looks for any line that matches the pattern. «.» matches any character. «grep . FILE» matches any line with at least 1 character. Whereas «grep -v» excludes lines matching the pattern. OP said «remove all the empty new lines». If you want to exclude lines with just spaces, «grep -v ‘^ $'». The «» will match zero or more of the preceding pattern, in this case a space. Though you might prefer to match and exclude other whitespace characters (tabs, form-feeds, etc) too.
This method allowed me to combine multiple excludes more easily than just «grep . FILE». For example, I was looking at a conf file and wanted to exclude all commented lines and all empty lines. So I used «grep -v -e ‘#’ -e ‘^$’ squid.conf». Worked a treat.
this one is a lot faster than the ‘grep . FILE’. This is due to the more complex tasks of verifying the regex ‘.’ than excluding as soon as ^$ does not matches.
grep -v -e ‘^$’ always works, which is not the case of grep . . For instance, with GNU grep 2.20, printf «\x80\n» | grep . outputs nothing, while printf «\x80\n» | grep -v ‘^$’ outputs the non-empty line.
with awk, just check for number of fields. no need regex $ more file hello world foo bar $ awk 'NF' file hello world foo bar its just my good practice to put quotes, since you are running it from shell.. for composite awk statements, you still have to put quotes. so why not cultivate this habit.
Here is a solution that removes all lines that are either blank or contain only space characters:
If removing empty lines means lines including any spaces, use:
$ printf "line1\n\nline2\n \nline3\n\t\nline4\n" > FILE $ cat -v FILE line1 line2 line3 line4 $ grep '\S' FILE line1 line2 line3 line4 $ grep . FILE line1 line2 line3 line4 [root@node1 ~]# cat /etc/sudoers | grep -v -e ^# -e ^$ Defaults !visiblepw Defaults always_set_home Defaults match_group_by_gid Defaults always_query_group_plugin Defaults env_reset Defaults env_keep = "COLORS DISPLAY HOSTNAME HISTSIZE KDEDIR LS_COLORS" Defaults env_keep += "MAIL PS1 PS2 QTDIR USERNAME LANG LC_ADDRESS LC_CTYPE" Defaults env_keep += "LC_COLLATE LC_IDENTIFICATION LC_MEASUREMENT LC_MESSAGES" Defaults env_keep += "LC_MONETARY LC_NAME LC_NUMERIC LC_PAPER LC_TELEPHONE" Defaults env_keep += "LC_TIME LC_ALL LANGUAGE LINGUAS _XKB_CHARSET XAUTHORITY" Defaults secure_path = /sbin:/bin:/usr/sbin:/usr/bin root ALL=(ALL) ALL %wheel ALL=(ALL) ALL [root@node1 ~]# Try this: sed -i ‘/^[ \t]*$/d’ file-name
It will delete all blank lines having any no. of white spaces (spaces or tabs) i.e. (0 or more) in the file.
Note: there is a ‘space’ followed by ‘\t’ inside the square bracket.
The modifier -i will force to write the updated contents back in the file. Without this flag you can see the empty lines got deleted on the screen but the actual file will not be affected.
THIS IS THE FILE EOF_MYFILE it gives as output only lines with at least 2 characters.
THIS IS THE FILE EOF_MYFILE See also the results with grep ‘^’ my_file outputs
THIS IS THE FILE EOF_MYFILE and also with grep ‘^.’ my_file outputs
THIS IS THE FILE EOF_MYFILE How to Delete Empty Lines in Files Using Grep, Sed, and Awk
An experienced Linux user knows exactly what kind of a nuisance blank lines can be in a processable file. These empty/blank lines not only get in the way of correctly processing such files but also make it difficult for a running program to read and write the file.
On a Linux operating system environment, it is possible to implement several text manipulation expressions to get rid of these empty/blank lines from a file. In this article, empty/blank lines refer to the whitespace characters.
Create a File with Empty/Blank Lines in Linux
We need to create a reference file with some empty/blank lines. We will later amend it in the article through several techniques we will be discussing. From your terminal, create a text file of your choice with a name like “i_have_blanks” and populate it with some data and some blank spaces.
$ nano i_have_blanks.txt Or $ vi i_have_blanks.txt
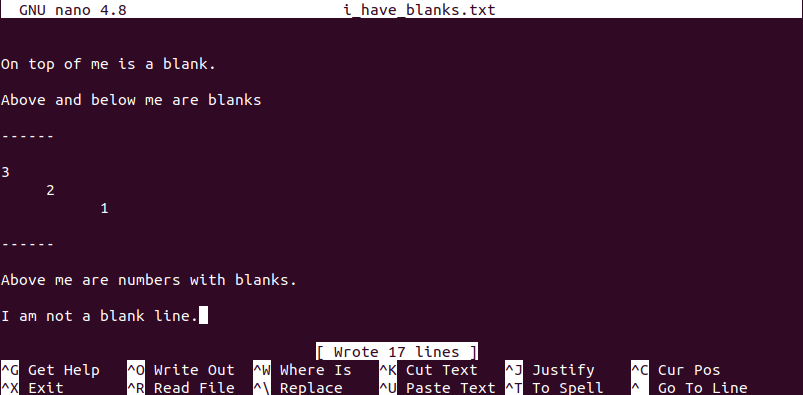
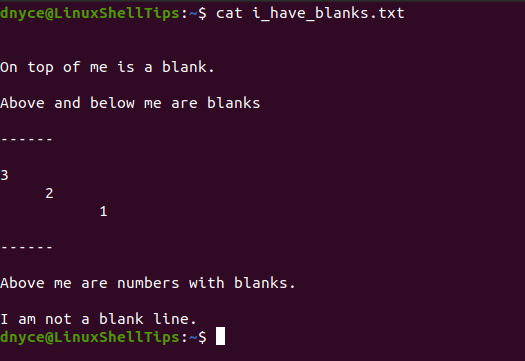
Throughout the article, we will be outputting the contents of a file on our terminal using the cat command for flexible referencing.
The three Linux commands that will propel us towards an ideal solution to this empty/blank lines problem are grep, sed, and awk.
Therefore, create three copies of your i_have_blanks.txt file and save them with different names so that each can be accommodated by one of the stated three Linux commands.
Through regex (regular expressions), we can identify blank lines with the POSIX standard character “[:space:]” .
How to Remove Blank/Empty Lines in Files
With this problem statement, we are considering the elimination of all existing empty/blank lines from a given readable file using the following commands.
1. Delete Empty Lines Using Grep Command
Supported use of shorthand character classes can reduce the grep command to a simple one like:
$ grep -v '^[[:space:]]*$' i_have_blanks.txt OR $ grep '\S' i_have_blanks.txt
To fix a file with blank/empty lines, the above output needs to pass through a temp file before overwriting the original file.
$ grep '\S' i_have_blanks.txt > tmp.txt $ mv tmp.txt i_have_blanks.txt $ cat i_have_blanks.txt

As you can see, all the blank lines that spaced the content of this text file are gone.
2. Delete Empty Lines Using Sed Command
The d action in the command tells it to delete any existing whitespace from a file. This command’s blank line matching and deleting mechanism can be represented in the following manner.
$ sed '/^[[:space:]]*$/d' i_have_blanks_too.txt
The above command scans through the text file lines for non-blank characters and deletes all the other remaining characters. Through its non-blank character class support, the above command can be simplified to the following:
$ sed '/\S/!d' i_have_blanks_too.txt
Also, because of the command’s in-place editing support, we don’t need a temp file to temporarily hold our converted file before overwriting the original text file like with the case of the grep command. You however need to use this command with an -i option as an argument.
$ sed -i '/\S/!d' i_have_blanks_too.txt i_have_blanks_too.txt $ cat i_have_blanks_too.txt

3. Delete Empty Lines Using Awk Command
The awk command runs a non-white character check on each line of a file and only prints them if this condition is true. The flexibility of this command comes with various implementation routes. Its straightforward solution is as follows:
$ awk '!/^[[:space:]]*$/' i_have_blanks_first.txt
The interpretation of the above command is straightforward, only the file lines that do not exist as whitespaces are printed. The longer version of the above command will look similar to the following:
$ awk '< if($0 !~ /^[[:space:]]*$/) >' i_have_blanks_first.txt
Through awk non-blank character class support, the above command can also be represented in the following manner:
$ awk -d '/\S/' i_have_blanks_first.txt
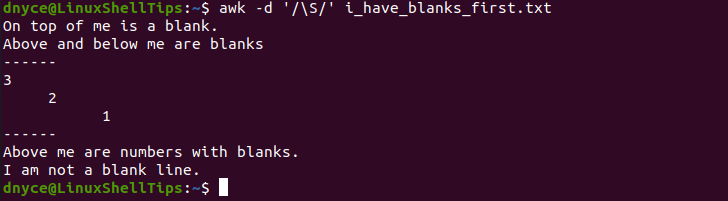
The -d an option lets awk dump the final file lines on the system terminal. As you can see, the file no longer has whitespaces.
The three discussed and implemented solutions to dealing with blank lines from files through grep, sed, and awk commands will take us a long way into implementing stable and efficient read and write file operations on a Linux system.
remove all empty lines from text files while keeping format
I have multiple notepad text files which contains one empty line (the last line of each file). I want to delete the empty line form all files. I tried different grep and awk lines but they didn’t work plus they messed up the file format; all text are shown on one line instead of separate line. i also tried with notepad++ regex to find ^\s*$ and replace it with nothing, but it also didn’t work. Current text file looks like this:
apples oranges peaches [empty line] 3 Answers 3
- Ctrl + H
- Find what: \R^$
- Replace with: LEAVE EMPTY
- check Wrap around
- check Regular expression
- Replace all
Explanation:
\R : any kind of linebreak ^ : begining of line $ : end of line Result for given example:
If you want to delete the last line of the file, use sed ‘$d’ . If you want to do that only when the last line is empty, use sed ‘$‘ (This treats a line with some whitespace as a non-blank line, so you might prefer sed ‘$‘ or some variant.
The «empty last line» may be a matter of interpretation. From the wikipedia «Newline» article:
Two ways to view newlines, both of which are self-consistent, are that newlines either separate lines or that they terminate lines. If a newline is considered a separator, there will be no newline after the last line of a file. Some programs have problems processing the last line of a file if it is not terminated by a newline. On the other hand, programs that expect newline to be used as a separator will interpret a final newline as starting a new (empty) line. Conversely, if a newline is considered a terminator, all text lines including the last are expected to be terminated by a newline. If the final character sequence in a text file is not a newline, the final line of the file may be considered to be an improper or incomplete text line, or the file may be considered to be improperly truncated.
In my little world, the Visual Studio Code editor takes the former view; vim the latter.