- How do I delete the first n lines and last line of a file using shell commands?
- 9 Answers 9
- head; head
- OR with a POSIX sed :
- Sed Command to Delete a Line
- Sed on Linux
- Deleting line using sed
- Delete single line
- Delete a range of line
- Delete multiple lines
- Delete all lines except specified range
- Delete empty lines
- Delete lines based on pattern
- Delete lines starting with a specific character
- Delete lines ending with specific character
- Deleting lines that match the pattern and the next line
- Deleting line from the pattern match to the end
- Final thought
- About the author
- Sidratul Muntaha
- Deleting Specific Lines from a File in Linux Command Line
- Remove nth line from the file
- Remove the last line using sed
- Delete a range of lines
- Remove lines containing a string
- Remove lines starting with a word
- Bonus Tip: Remove all empty lines
How do I delete the first n lines and last line of a file using shell commands?
You’re probably best off fixing this inside SQL*Plus; rather than generating a file and then trying to trim the stuff you don’t want, you can just tell SQL*Plus not to generate that stuff to begin with. One approach is described in the «Creating a Flat File» section at docs.oracle.com/cd/A84870_01/doc/sqlplus.816/a75664/ch44.htm; another approach is described at stackoverflow.com/q/2299375/978917.
9 Answers 9
How it works :
- -i option edit the file itself. You could also remove that option and redirect the output to a new file or another command if you want.
- 1d deletes the first line ( 1 to only act on the first line, d to delete it)
- $d deletes the last line ( $ to only act on the last line, d to delete it)
Going further :
- You can also delete a range. For example, 1,5d would delete the first 5 lines.
- You can also delete every line that begins with SQL> using the statement /^SQL> /d
- You could delete every blank line with /^$/d
- Finally, you can combine any of the statement by separating them with a semi-colon ( statement1;statement2;satement3;. ) or by specifying them separately on the command line ( -e ‘statement1’ -e ‘statement 2’ . )
If its 3rd line to delete. then i have to use 3d in place of 1d? if its 3rd line from last to delete. then what will be the command?
@Nainita You can specify a range ( 1,3d will delete the first three lines) but it’s a little more difficult for the end. Depending on what you want, you could be better off using this : sed -i ‘/^SQL> /d’ Element_query to delete lines that begins with SQL> no matter where it is in the file.
@Nainita — see my answer here for arbitrary tail counts — it offers two solutions for stripping count lines as relative to the end of the file. One is a sed one-liner — which will work for stripping arbitrary line counts from the head and tail of a file, Better though, as long as input is a regular file, is just to group a single input across two head processes — it is the fastest way to do this usually.
head; head
< head -n[num] >/dev/null head -n[num] > outfile With the above you can specify the first number of lines to strip off of the head of the output w/ the first head command, and the number of lines to write to outfile with the second. It will also typically do this faster than sed — especially when input is large — despite requiring two invocations. Where sed definitely should be preferred though, is in the case that not a regular, lseekable file — because this will typically not work as intended in that case, but sed can handle all output modifications in a single, scripted process.
With a GNU head you can use the — negative form for [num] in the second command as well. In which case the following command will strip first and last lines from input:
OR with a POSIX sed :
Say, for example, I was reading an input of 20 lines and I wanted to strip the first 3 and the last 7. If I resolved to do so w/ sed , I would do it with a tail buffer. I would first add together three and seven for a total strip count of ten and then do:
seq 20 | sed -ne:n -e '3d;N;1,10bn' -eP\;D That is an example which strips the first 3 and last 7 lines from input. The idea is that you can buffer as many lines as you wish to strip from the tail of input in the pattern space on a stack but only P rint the first of these for every line pulled in.
- On lines 1,10 sed P rints nothing because for each of those it is stacking input in pattern space line-by-line in a b ranch loop.
- On the 3rd line all of sed ‘s stack is d eleted — and so the first 3 lines are stripped from output in one fell swoop.
- When sed reaches the $ last line of input and attempts to pull in the N ext it hits EOF and stops processing entirely. But at that time pattern space contains all of lines 14,20 — none of which have yet been P rinted, and never are.
- On every other line sed P rints only up to the first occurring \n ewline in pattern space, and D eletes same before beginning a new cycle with what remains — or the next 6 lines of input. The 7th line is appended again to the stack with the N ext command in the new cycle.
And so, of seq ‘s output (which is 20 sequentially numbered lines), sed only prints:
This gets to be problematic when the number of lines you desire to strip from the tail of input is large — because sed ‘s performance is directly proportional to the size of its pattern space. Still, though, it is a viable solution in many cases — and POSIX specs a sed pattern space to handle at least 4kb before busting.
Sed Command to Delete a Line
![]()
Sed is a built-in Linux tool for text manipulation. The term sed stands for stream editor. Despite the name, sed isn’t a text editor by itself. Rather, it takes text as input, performs various text modifications according to instructions, and prints the output.
This guide will demonstrate how to use sed to delete a line from a text.
Sed on Linux
The full name of sed gives us a hint at its working method. Sed takes the input text as a stream. The text can come from anywhere – a text file or standard output (STDOUT). After taking the input, sed operates on it line by line.
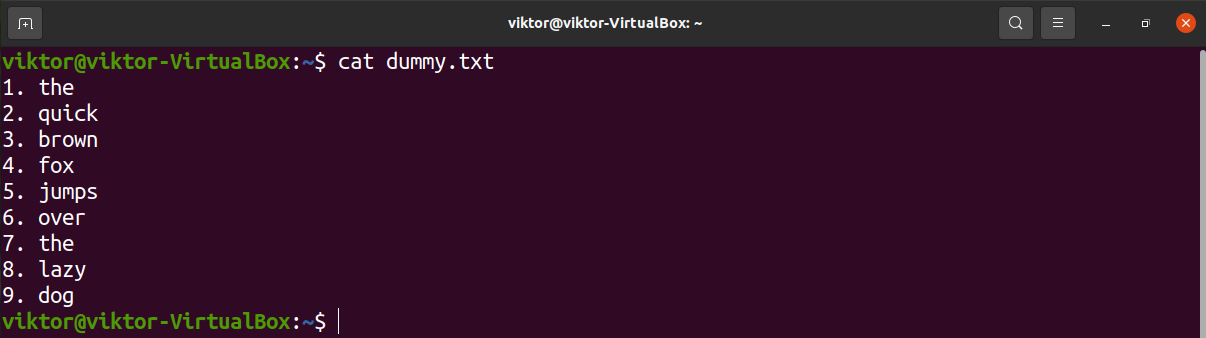
For demonstration, here’s a simple text file I’ve generated.
Deleting line using sed
To delete a line, we’ll use the sed “d” command. Note that you have to declare which line to delete. Otherwise, sed will delete all the lines.
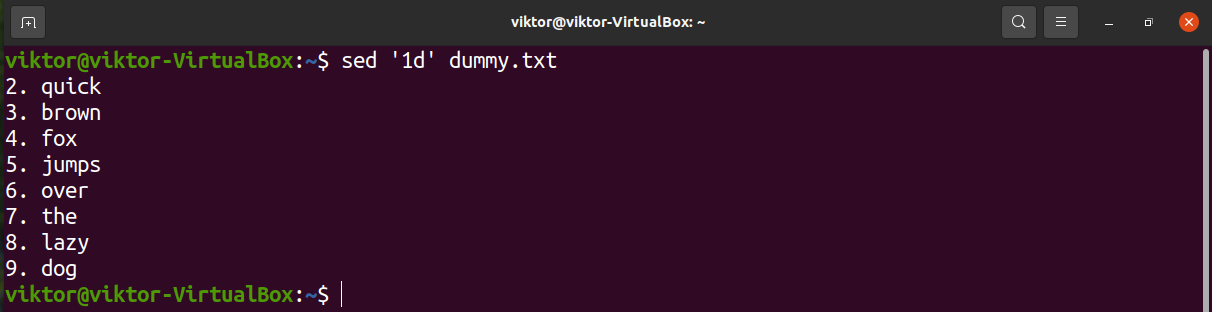
Delete single line
The following sed command will delete the first line of the text.
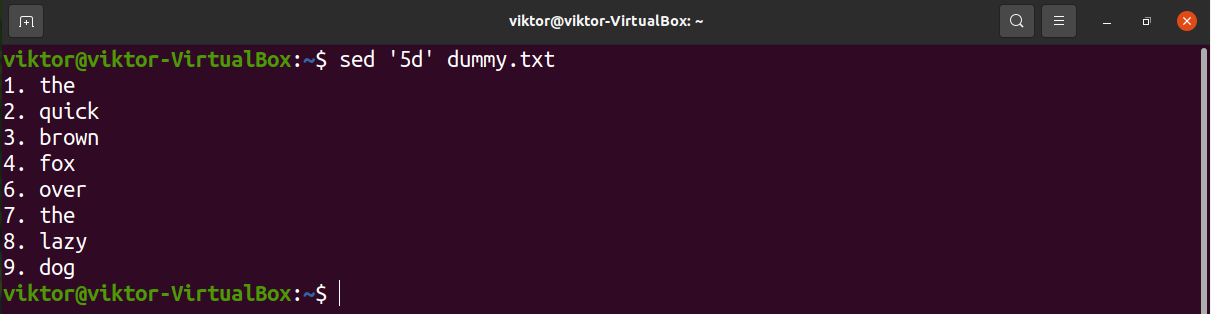
Basically, to delete a line, you need the line number of the target line. Let’s remove line 5.
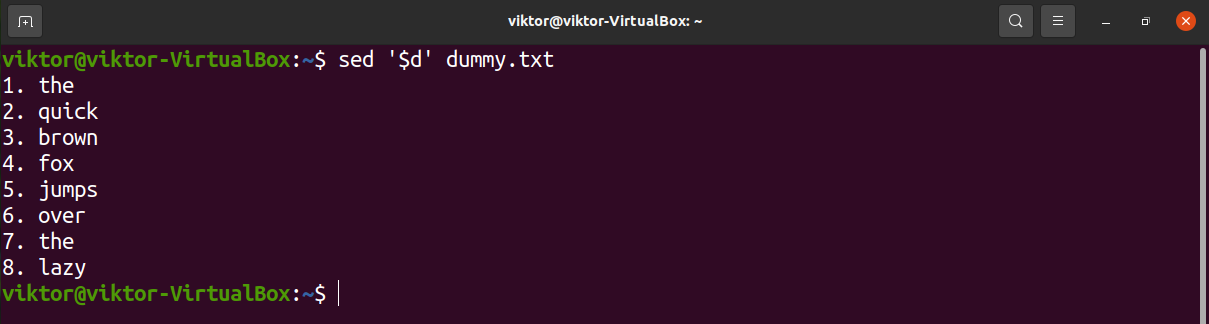
To delete the last line of the text file, instead of manually calculating the line number, use “$” instead.
Delete a range of line
Sed can delete a range of lines. Here, the minimum line value is 1, and the maximum line value is 5. To declare range, we’re using comma (,).

Delete multiple lines
What if the lines you desire to remove are not in a fixed range? Have a look at the following sed command. Note that we’re using a semicolon (;) as the delimiter. Essentially, each delimited option is a separate sed command.

Delete all lines except specified range
In the next example, sed will only keep the lines described by the range. Here, “!” is the negation operator, telling sed to keep the specific lines.

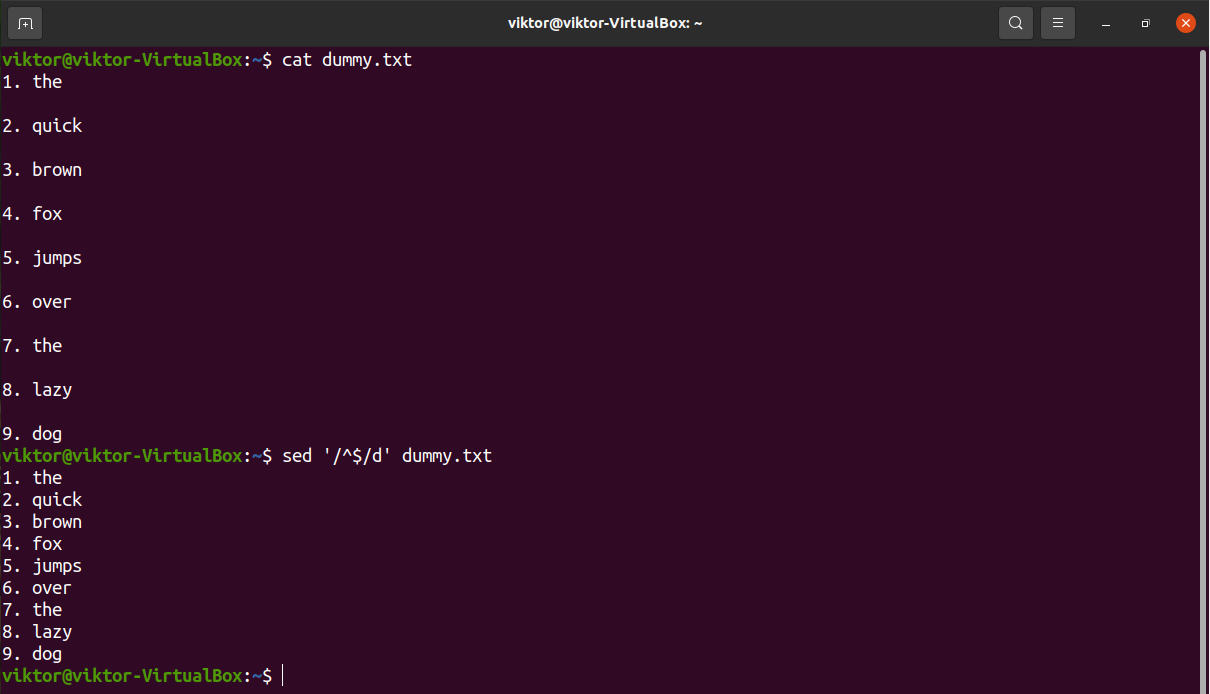
Delete empty lines
If there are multiple empty or blank lines in the text, the following sed command will remove all of them.
Delete lines based on pattern
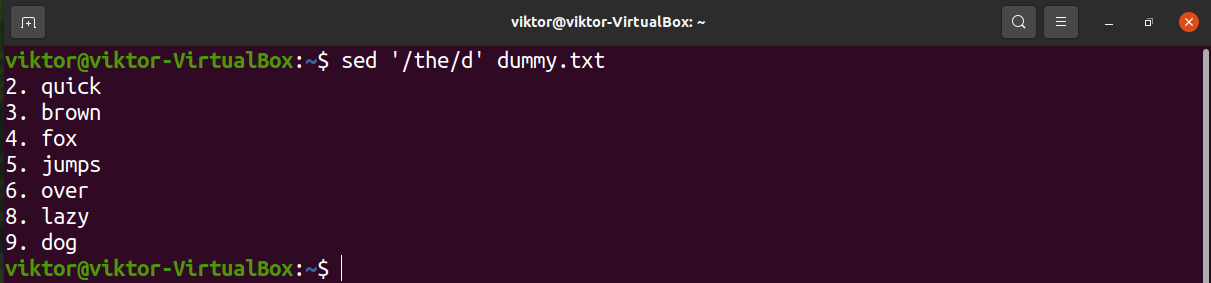
Sed can search for a particular pattern and perform the specified actions on the line. We can use this feature to delete specific lines that match a pattern.
Let’s have a look at the following demonstration. Sed will remove any line that contains the string “the”.
We can also describe multiple strings to search for. Each string is delimited using the symbol “\|”.

Delete lines starting with a specific character
To denote the starting of a line, we’ll use the caret (^) symbol.
The following sed command will remove all the lines starting with a digit. Here, the character group “[:digit:]” describes all digits (0-9).

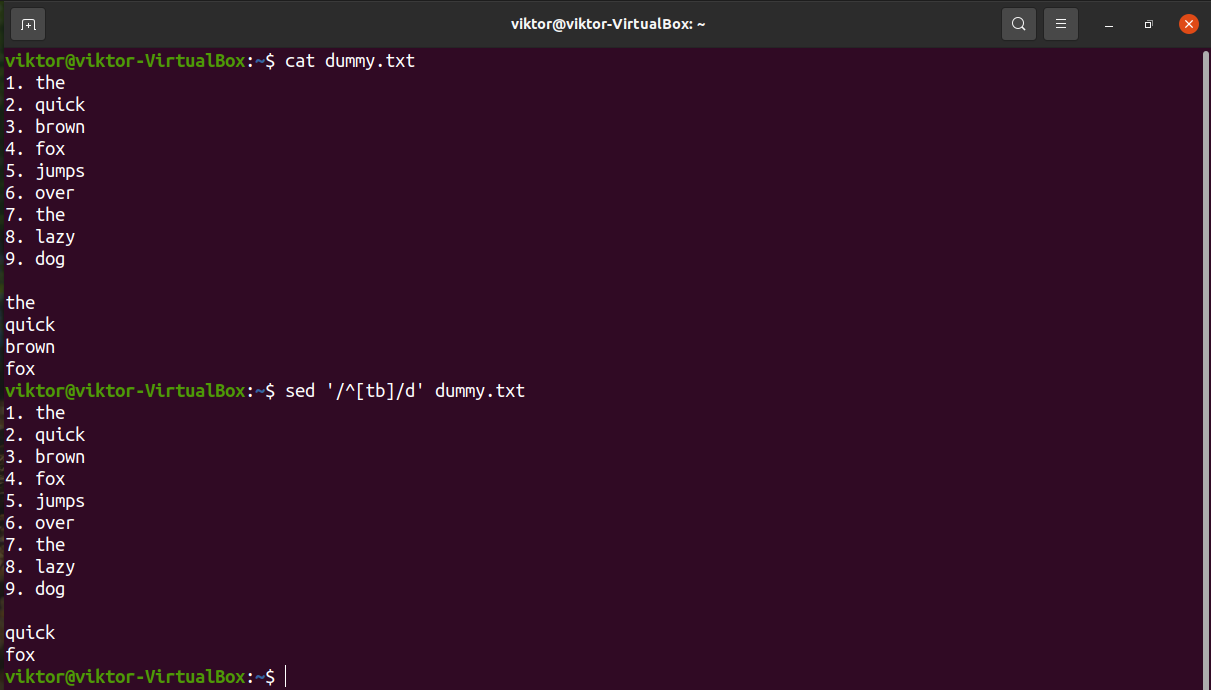
We can also describe multiple characters for a valid match. The following example will match all the lines that start with “t” and “b”.
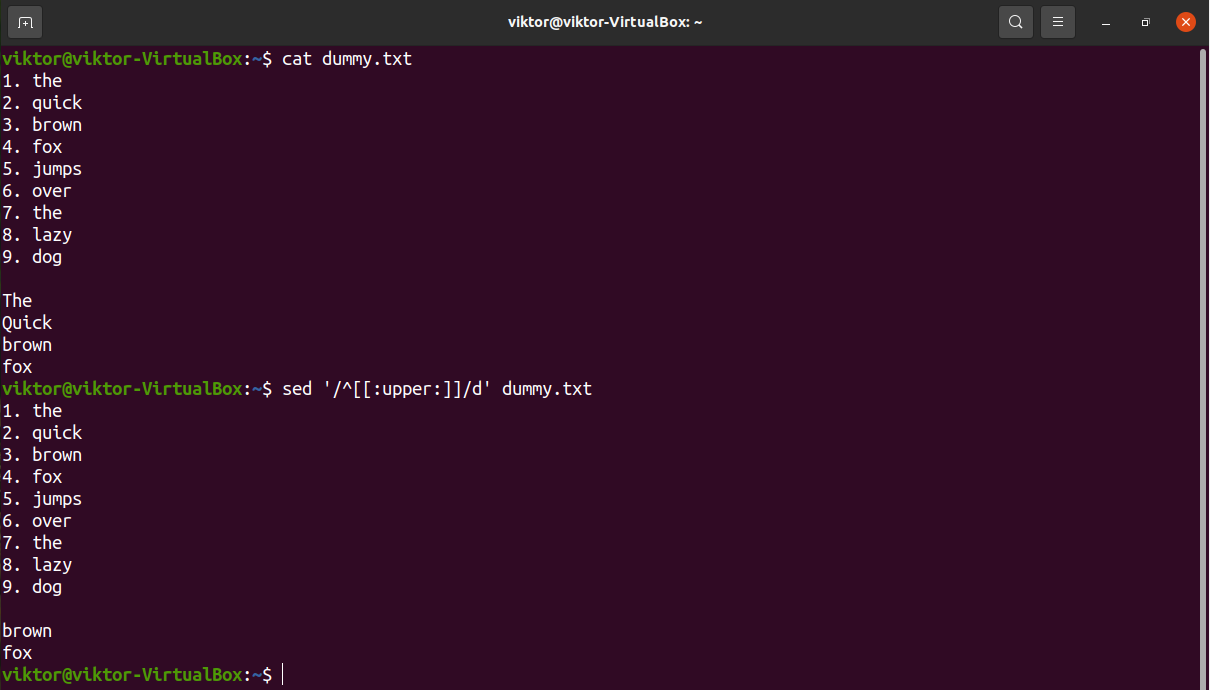
In the next example, check out how to remove all the lines that start with an uppercase character. Here, we’re using the uppercase character group “[:upper:]”.
If the target lines have lowercase characters at the start, use the lowercase character group “[:lower:]”.
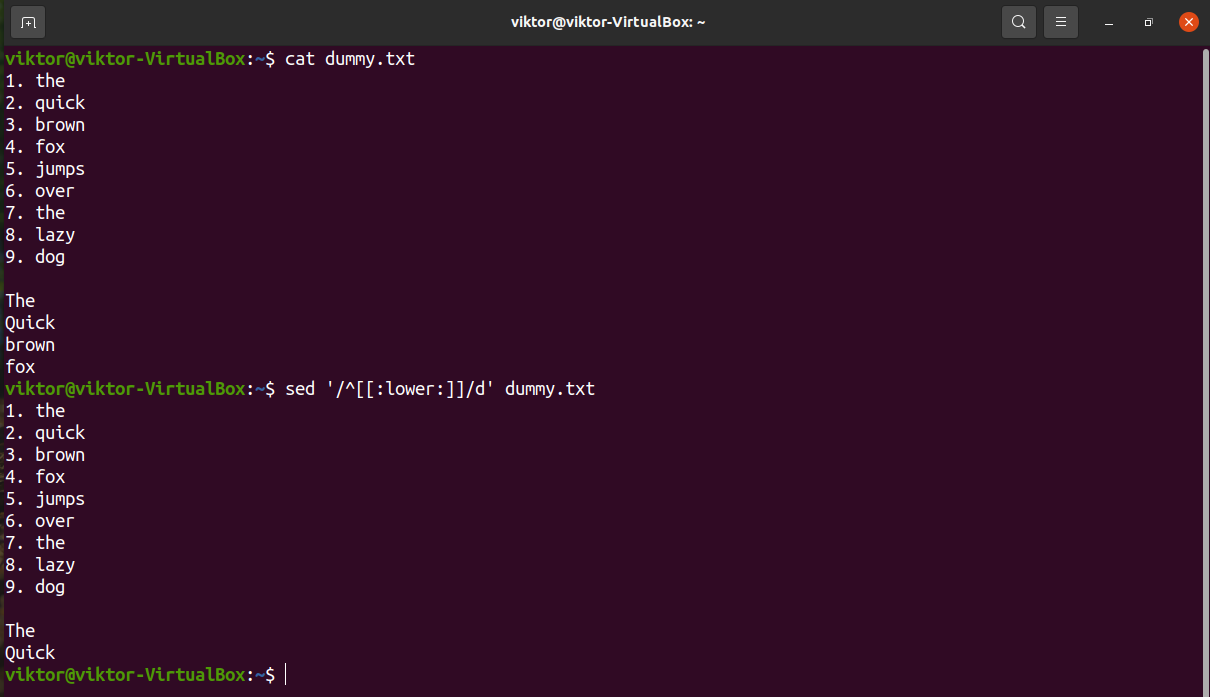
Delete lines ending with specific character
To denote the end of a line, we can use the symbol “$”. It describes the match with the last occurrence of the pattern.
In the next example, sed will delete lines ending with “e”.
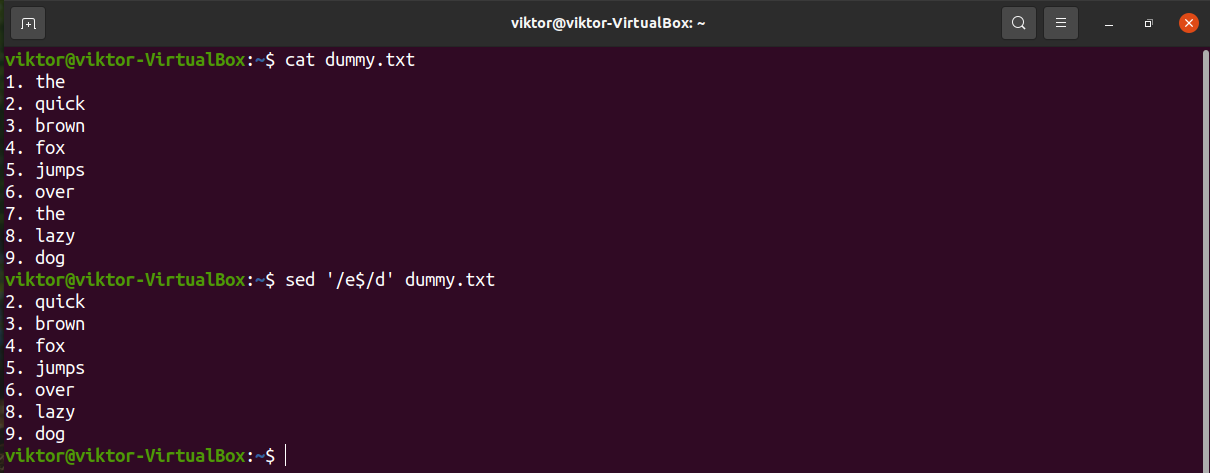
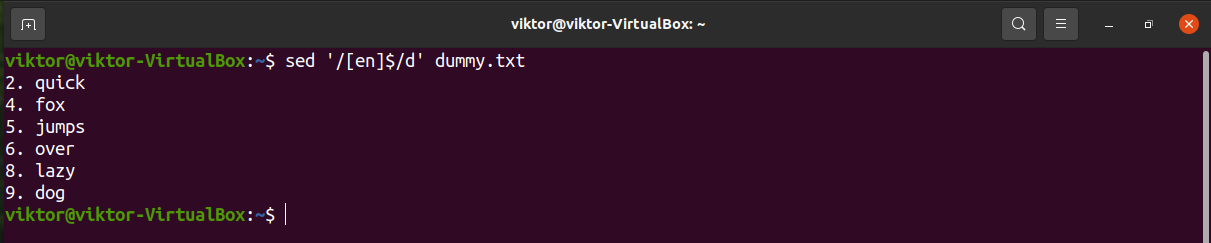
Let’s try with a multiple-character search.
Deleting lines that match the pattern and the next line
We’ve already demonstrated how to delete a line if a pattern matches. We can further extend and delete the subsequent line as well.
Check out the following sed command.

Sed will match the line that contains “the” and delete the subsequent line as well.
Deleting line from the pattern match to the end
We can further extend the previous example to order sed to delete all the lines, starting from the first match of the pattern.

Here, sed will delete the line that matches the pattern “the” first and all lines afterward.
Final thought
Sed is a simple tool. However, it can do wonders, thanks to the support for regular expression. Sed also integrates seamlessly in various scripts.
This was just a short guide demonstrating one of the sed functions – deleting lines. There are tons of other things you can do with sed. For example, check out this mega guide on 50 sed examples. It’s a fantastic guide covering all the basics and many advanced sed implementations.
About the author
Sidratul Muntaha
Student of CSE. I love Linux and playing with tech and gadgets. I use both Ubuntu and Linux Mint.
Deleting Specific Lines from a File in Linux Command Line
Here are a few usecases of deleting specific lines from a text file using the sed command.
The task is simple. You have to delete specific lines from a text file in Linux terminal.
Using commands like rm deletes the entire file and you don’t want that here.
You can use a text editor like Vim or Nano, enter the file and delete the desired lines. However, this approach is not suitable for automation using bash scripts.
Instead, you can use the powerful sed command line editor and delete lines that match specific criteria. And of course, you can use sed in your shell scripts.
Let me show a few use cases.
The examples shown here will modify the original file instantly. It would be a good idea to make a backup of that file before you start experimenting with it.
Remove nth line from the file
Imagine you have to delete the 7th line number in a file. You can use the sed command like this:
Let me explain how it works:
- -i : This option enables the in-place editing. By default, sed will only display the output. With this -i option, it modifies the actual file without showing it on the display.
- 7d : Here 7 is the line number and d instructs the deletion of the line.
- filename : This is the file you want to modify. You may also provide absolute or relative path if the file is in some other directory.
Let me show with a real example. Take a look at the content of the file named agatha.txt:
The Mystery of the Blue Train The Seven Dials Mystery The Murder at the Vicarage Giant's Bread The Floating Admiral The Sittaford Mystery Peril at End House Lord Edgware DiesTo remove the 4th line from this file, I use:
This will result in the following display with the line ‘Giant’s Bread’ removed :
The Mystery of the Blue Train The Seven Dials Mystery The Murder at the Vicarage The Floating Admiral The Sittaford Mystery Peril at End House Lord Edgware DiesNow, let’s say you want to remove the first line of the file in Linux command line. Use sed like this:
If you want to see the result of manipulation without modifying the file itself, do not use the -i option of sed command.
Remove the last line using sed
You learned to delete a particular line but what if you need to remove the last line?
You may always get the total number of lines in a file using wc command and use this number with sed. However, sed has a dedicated way of deleting the last line of a file. You don’t need to worry about the number of files anymore now.
Delete a range of lines
Similar to what you saw earlier, you can also delete a range of lines from the file.
Suppose you have to delete the lines from 11 to 15, you can provide the range like this:
Note that it will also remove the lines 11 and 15, not just the lines that fall between them.
Remove lines containing a string
You can also use sed to delete all the lines that contain a given string or match a specific pattern.
The command below will delete all the lines that contain the word ‘string’:
Do note that this is a case-sensitive search. You may also use a regex pattern instead of a regular string.
Remove lines starting with a word
If you want to remove all the lines starting with a particular word or letter, you just have to provide the regex pattern like this:
Bonus Tip: Remove all empty lines
Before I end this article, let me quickly share how you can remove all empty lines using sed:
I hope you find this quick tip helpful in removing lines from text file in Linux command line.
If you are interested, learn more on sed command line editor: