- Replace whitespaces with tabs in linux
- How to Remove Spaces from Filenames in Linux
- Prerequisite
- 1. Removing Spaces from Filename with Specific File Extension
- 2. Replacing Filename Spaces Using rename Command
- 3. Replacing Filename Spaces Using For Loop and mv Command
- sed replace all tabs and spaces with a single space
- 4 Answers 4
- Replace all white spaces with commas in a text file
- 6 Answers 6
Replace whitespaces with tabs in linux
Woah, never knew expand/unexpand existed. I was trying to do the opposite and expand was perfect rather than having to mess around with tr or sed .
So cool that these are standard. I love the UNIX philosophy. Would be nice if it could do in place though.
I don’t think unexpand will work here.. it only convert the leading spaces and only with two or more spaces.. see here:lists.gnu.org/archive/html/bug-textutils/2001-01/msg00025.html
Just a caution — unexpand will not convert a single space into a tab. If you need to blindly convert all runs of 0x20 characters into a single tab, you need a different tool.
I think you can try with awk
sed 's/[:blank:]+/,/g' thefile.txt > the_modified_copy.txt tr -s '\t' < thefile.txt | tr '\t' ' ' >the_modified_copy.txt or a simplified version of the tr solution sugested by Sam Bisbee
In your sed example, best practices dictate that you use tr to replace single characters over sed for efficiency/speed reasons. Also, tr example is much easier this way: tr ‘ ‘ \\t < someFile >someFile
Of course, tr has better performance than sed, but the main reason I have for loving Unix is that there’re many ways to do something. If you plan to do this substitution many times you will search a solution with a good performance, but if you are going to do it only once, you will serach for a solution wich involves a command that make you feel confortable.
arg. I had to use trial and error to make the sed work. I have no idea why I had to escape the plus sign like this: ls -l | sed «s/ \+/ /g»
With awk -v OFS=»\t» ‘$1=$1’ file1 I noticed that if you have a line beginning with number 0 (e.g. 0 1 2 ), then the line will be ommitted from the result.
@Jess You found «correct default syntax» regex. By default sed treat single (unescaped) plus sign as simple character. The same is true for some other characters like ‘?’, . You can find more info here: gnu.org/software/sed/manual/html_node/… . Similar syntax details can be found here (note that this is man for grep, not sed): gnu.org/software/grep/manual/grep.html#Basic-vs-Extended .
Using Perl:
Had a similar problem with replace consecutive spaces with a single tab. Perl worked worked with only the addition of a ‘+’ to the regexp.
Though, of course, I wanted to do the opposite: convert tabs to two spaces: perl -p -i -e ‘s/\t/ /g’ *.java
better tr command:
This will clean up the output of say, unzip -l , for further processing with grep, cut, etc.
unzip -l some-jars-and-textfiles.zip | tr [:blank:] \\t | cut -f 5 | grep jar Example command for converting each .js file under the current dir to tabs (only leading spaces are converted):
find . -name "*.js" -exec bash -c 'unexpand -t 4 --first-only "$0" > /tmp/totabbuff && mv /tmp/totabbuff "$0"' <> \; Download and run the following script to recursively convert soft tabs to hard tabs in plain text files.
Place and execute the script from inside the folder which contains the plain text files.
#!/bin/bash find . -type f -and -not -path './.git/*' -exec grep -Iq . <> \; -and -print | while read -r file; do < echo "Converting. "$file""; data=$(unexpand --first-only -t 4 "$file"); rm "$file"; echo "$data" >"$file"; >; done; This will replace consecutive spaces with one space (but not tab).
This will replace consecutive spaces with a tab.
You can also use astyle . I found it quite useful and it has several options too:
Tab and Bracket Options: If no indentation option is set, the default option of 4 spaces will be used. Equivalent to -s4 --indent=spaces=4. If no brackets option is set, the brackets will not be changed. --indent=spaces, --indent=spaces=#, -s, -s# Indent using # spaces per indent. Between 1 to 20. Not specifying # will result in a default of 4 spaces per indent. --indent=tab, --indent=tab=#, -t, -t# Indent using tab characters, assuming that each tab is # spaces long. Between 1 and 20. Not specifying # will result in a default assumption of 4 spaces per tab.` If you are talking about replacing all consecutive spaces on a line with a tab then tr -s ‘[:blank:]’ ‘\t’ .
[root@sysresccd /run/archiso/img_dev]# sfdisk -l -q -o Device,Start /dev/sda Device Start /dev/sda1 2048 /dev/sda2 411648 /dev/sda3 2508800 /dev/sda4 10639360 /dev/sda5 75307008 /dev/sda6 96278528 /dev/sda7 115809778 [root@sysresccd /run/archiso/img_dev]# sfdisk -l -q -o Device,Start /dev/sda | tr -s '[:blank:]' '\t' Device Start /dev/sda1 2048 /dev/sda2 411648 /dev/sda3 2508800 /dev/sda4 10639360 /dev/sda5 75307008 /dev/sda6 96278528 /dev/sda7 115809778 If you are talking about replacing all whitespace (e.g. space, tab, newline, etc.) then tr -s ‘[:space:]’ .
[root@sysresccd /run/archiso/img_dev]# sfdisk -l -q -o Device,Start /dev/sda | tr -s '[:space:]' '\t' Device Start /dev/sda1 2048 /dev/sda2 411648 /dev/sda3 2508800 /dev/sda4 10639360 /dev/sda5 75307008 /dev/sda6 96278528 /dev/sda7 115809778 If you are talking about fixing a tab-damaged file then use expand and unexpand as mentioned in other answers.
How to Remove Spaces from Filenames in Linux
In other operating system environments, creating and using filenames with spaces is irrevocably permissible. However, when we enter the Linux operating system domain, the existence of such filenames becomes an inconvenience.
For instance, consider the existence of the following filenames inside a Linux operating system environment.

As per the command line view of these filenames, processing or moving them becomes an unwarranted inconvenience because of the white space in their naming convention.
Additionally, filename spaces in Linux are a disadvantage to users processing them via web-based applications as the string %20 tends to be included as part of the processed/final filename.
This article takes a look at valid approaches to help you get rid of spaces on filenames while working under a Linux operating system environment.
Prerequisite
Familiarize yourself with the usage of the Linux terminal or command-line interface. For practical reference purposes, we will be using the spaced filenames presented in the following screen capture.
1. Removing Spaces from Filename with Specific File Extension
The find command is combined with the mv command to effectively execute its functional objective to remove spaces on a filename with a specific file extension e.g .xml files.
$ find . -type f -name "* *.xml" -exec bash -c 'mv "$0" "$"' <> \;

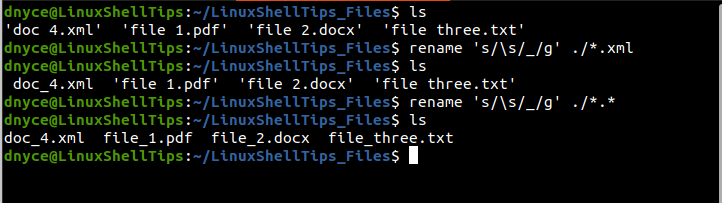
2. Replacing Filename Spaces Using rename Command
Alternatively, instead of using find with mv commands to trace and replace filename spaces, we could use a single rename command, which is a pearl extension and can be installed in the following Linux operating system distributions:
$ sudo apt install rename [On Debian, Ubuntu and Mint] $ sudo yum install rename [On RHEL/CentOS/Fedora and Rocky Linux/AlmaLinux] $ sudo emerge -a sys-apps/rename [On Gentoo Linux] $ sudo pacman -S rename [On Arch Linux] $ sudo zypper install rename [On OpenSUSE]
Once installed, the rename command can be used in the following manner:
The above command will replace the spaces in all .xml files with an underscore. To replace all the spaces in all the filenames regardless of the file extension, use:
3. Replacing Filename Spaces Using For Loop and mv Command
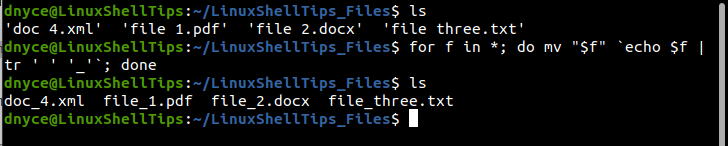
This approach is effective in getting rid of filename spaces on different file name formats existing on a specific/targeted folder/directory. The for loop function queries for filename spaces inside a targeted directory/folder and afterward replaces those filename spaces with an underscore notation.
Consider the following implementation of this approach:
$ for f in *; do mv "$f" `echo $f | tr ' ' '_'`; done
Before the start of this article, filename spaces were a nuisance especially when you need to copy and move files from the Linux terminal or process them via a web-based program. This tutorial has provided a viable solution that works against such inconveniences.
sed replace all tabs and spaces with a single space
now I want to replace all the tabs/spaces inbetween the records with just a single space so I can easily use it with cut -d » » I tried the following:
4 Answers 4
[ # start of character class [:space:] # The POSIX character class for whitespace characters. It's # functionally identical to [ \t\r\n\v\f] which matches a space, # tab, carriage return, newline, vertical tab, or form feed. See # https://en.wikipedia.org/wiki/Regular_expression#POSIX_character_classes ] # end of character class \+ # one or more of the previous item (anything matched in the brackets). For your replacement, you only want to insert a space. [:space:] won’t work there since that’s an abbreviation for a character class and the regex engine wouldn’t know what character to put there.
The + must be escaped in the regex because with sed’s regex engine + is a normal character whereas \+ is a metacharacter for ‘one or more’. On page 86 of Mastering Regular Expressions, Jeffrey Friedl mentions in a footnote that ed and grep used escaped parentheses because «Ken Thompson felt regular expressions would be used to work primarily with C code, where needing to match raw parentheses would be more common than backreferencing.» I assume that he felt the same way about the plus sign, hence the need to escape it to use it as a metacharacter. It’s easy to get tripped up by this.
In sed you’ll need to escape + , ? , | , ( , and ) . or use -r to use extended regex (then it looks like sed -r -e «s/[[:space:]]\+/ /g» or sed -re «s/[[:space:]]\+/ /g»
Replace all white spaces with commas in a text file
I need to replace all white spaces inside my text with commas. I’m currently using this line but it doesn’t work: I get as output a text file which is exactly the same of the original one:
sed 's/[:blank:]+/,/g' orig.txt > modified.txt 6 Answers 6
sed -e 's/\s\+/,/g' orig.txt > modified.txt Edit: To exclude newlines in Perl you could use a double negative ‘s/[^\S\n]+/,/g’ or match against just the white space characters of your choice ‘s/[ \t\r\f]+/,/g’ .
Thanks, however there is still an issue: I don’t want to replace «next lines \n» with a comma, and the command with perl is currently doing it. She sed command you wrote, it still doesn’t work.
Sorry you need to escape the + operator in sed, I just updated my answer. Newlines are whitepsace in perl, so you will have to do your whitepsace class manually if you don’t wnat to include it. I added two solutions for that as wel.
This will replace any horizontal whitespace with a comma. Any repeated whitespace will only be replaced with a single comma.
The issue with your command,
sed 's/[:blank:]+/,/g' orig.txt > modified.txt - The [:blank:] is a bracketed expression matching one of the characters : , a , b , k , l , or n . If you want to match one of the characters in the POSIX character class [:blank:] , use [[:blank:]] .
- The + is an extended regular expression modifier. The sed utility uses basic regular expressions, and the + would match a literal + character. To get the same effect in a basic regular expression, use \ , or, in this particular expression, use [[:blank:]][[:blank:]]* instead.
In short, your corrected sed expression would be
sed 's/[[:blank:]]\/,/g' orig.txt >modified.txt sed 's/[[:blank:]][[:blank:]]*/,/g' orig.txt >modified.txt As others have pointed out, and assuming single byte ASCII characters in the text, it may be more efficient to use tr in this case, as it’s a simple transliteration of one set of characters to another. Either one of the following two tr commands would solve the issue:
where [,*] means «as many commas as is needed for this set to match the number of characters in the first set», or
The -s option to tr causes multiple consecutive commas to be «squeezed» into single commas.
Note that some tr implementations including GNU tr only work correctly with single-byte characters, so they would fail to handle blank characters such as U+1680 OGHAM SPACE MARK, U+2000 EN QUAD, U+2001 EM QUAD, U+2002 EN SPACE, U+2003 EM SPACE, U+2004 THREE-PER-EM SPACE, U+2005 FOUR-PER-EM SPACE, U+2006 SIX-PER-EM SPACE, U+2008 PUNCTUATION SPACE, U+2009 THIN SPACE, U+200A HAIR SPACE, U+205F MEDIUM MATHEMATICAL SPACE, U+3000 IDEOGRAPHIC SPACE in those locales where those characters are encoded on more than one byte (like those using UTF-8 as their charmap).
@StéphaneChazelas Hair space? I lack a philosophical space. But much thanks, as usual. I keep on learning.