- What return/exit values can I use in bash functions/scripts?
- Bash Exit Code of Last Command
- Bash Exit Code
- Checking Bash Exit Code
- Incorporating Exit Code in Scripts
- Exit Code Value Explanation
- Defining Exit Status in Script
- Final Thoughts
- About the author
- Sidratul Muntaha
- Как использовать коды завершения в Bash-скриптах
- Что такое коды завершения
- Что происходит, когда коды завершения не определены
- Как использовать коды завершения в Bash-скриптах
- Проверяем коды завершения
- Создаём собственный код завершения
- Как использовать коды завершения в командной строке
- Дополнительные коды завершения
What return/exit values can I use in bash functions/scripts?
The exit status of a process is encoded as a value between 0 and 255, so that’s all you can use as an exit code. If you pass a value outside that range, most shells use the remainder modulo 256. Some shells allow a wider range of integer values for functions.
The only rule for exit codes is that 0 means success and any other value means failure. This rule goes beyond unix: it’s also a common convention on other operating systems (including DOS, Windows, and many embedded systems that have a notion of exit code, but VMS does things differently). In unix systems, it’s baked into the shell’s boolean constructs ( if , while , && , || , ! , set -e , …), into make , and followed by all the standard utilities. In POSIX C programs, EXIT_SUCCESS is 0 and EXIT_FAILURE is some non-zero value (usually 1).
There is no rule (de facto or de jure) regarding the choice of exit codes for failure. Only a few POSIX utilities mandate specific failure status codes:
- The ! shell operator returns 1 if its operand returns 0. The && and || operator pass the status from the last command.
- cmp and diff return 1 for different files and ≥2 for error conditions.
- expr returns 1 if the expression evaluates to zero or null, 2 for an invalid expression, and ≥3 for other errors.
- grep returns 1 for “not found” and ≥2 for error conditions. Many search commands follow this (but not find , which returns 0 if no file matches).
- mesg returns 0 for yes, 1 for no, and ≥2 for error.
- patch returns 1 if a hunk was rejected and ≥2 for other errors.
- sort -c returns 1 if the file data isn’t sorted and ≥2 for errors.
- compress and localedef define some small values for specific errors.
There is a common, but not universal idea that larger values mean worse failures. For commands that test a boolean condition such as grep (is this pattern present?) and diff (are these files identical?), 1 means “no” and higher values indicate an error. In addition, values from 126 up are rarely used, as they are baked into the shell (and POSIX commands command , env , nice , nohup and time ):
- 126 and 127 indicate a failure to invoke an external command;
- values above 128 in $? indicate a command that was terminated by a signal.
/usr/include/sysexits.h lists some values with their meanings, but it’s from sendmail and I’ve never seen it outside programs that are unrelated to email delivery.
In summary, return 0 for success, and either 1 or 2 for failure. If you need to distinguish between failure cases, start at 1 and increase the value for worse failures.
Bash Exit Code of Last Command
![]()
When a bash command is executed, it leaves behind the exit code, irrespective of successful or unsuccessful execution. Examining the exit code can offer useful insight into the behavior of the last-run command.
In this guide, check out how to check bash exit code of the last command and some possible usages of it.
Bash Exit Code
Every UNIX/Linux command executed by the shell script or user leaves an exit status. It’s an integer number that remains unchanged unless the next command is run. If the exit code is 0, then the command was successful. If the exit code is non-zero (1-255), then it signifies an error.
There are many potential usages of the bash exit code. The most obvious one is, of course, to verify whether the last command is executed properly, especially if the command doesn’t generate any output.
In the case of bash, the exit code of the previous command is accessible using the shell variable “$?”.
Checking Bash Exit Code
Launch a terminal, and run any command.
Check the value of the shell variable “$?” for the exit code.

As the “date” command ran successfully, the exit code is 0. What would happen if there was an error?
Let’s try running a command that doesn’t exist.
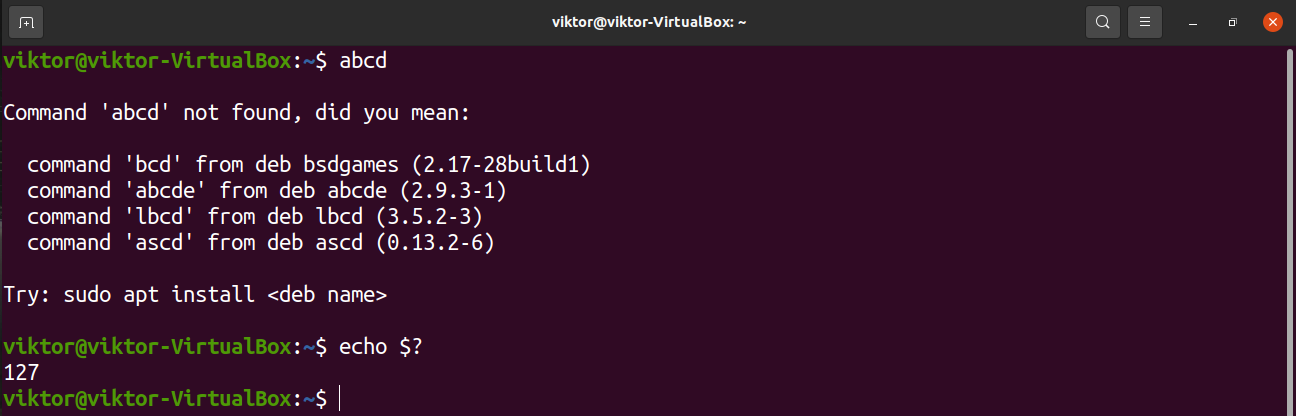
It’s a non-zero value, indicating that the previous command didn’t execute properly.
Now, have a look at the following command:

When working with a command that has one or more pipes, the exit code will be of the last code executed in the pipe. In this case, it’s the grep command.
As the grep command was successful, it will be 0.

In this example, if the grep command fails, then the exit code will be non-zero.

Incorporating Exit Code in Scripts
The exit code can also be used for scripting. One simple way to use it is by assigning it to a shell variable and working with it. Here’s a sample shell script that uses the exit code as a condition to print specific output.
$ #!/bin/bash
$ echo «hello world»
$ status = $?
$ [ $status -eq 0 ] && echo «command successful» || echo «command unsuccessful»

When being run, the script will generate the following output.

Now, let’s see what happens when there’s an invalid command to run.
$ #!/bin/bash
$ random-command
$ status = $?
$ [ $status -eq 0 ] && echo «command successful» || echo «command unsuccessful»
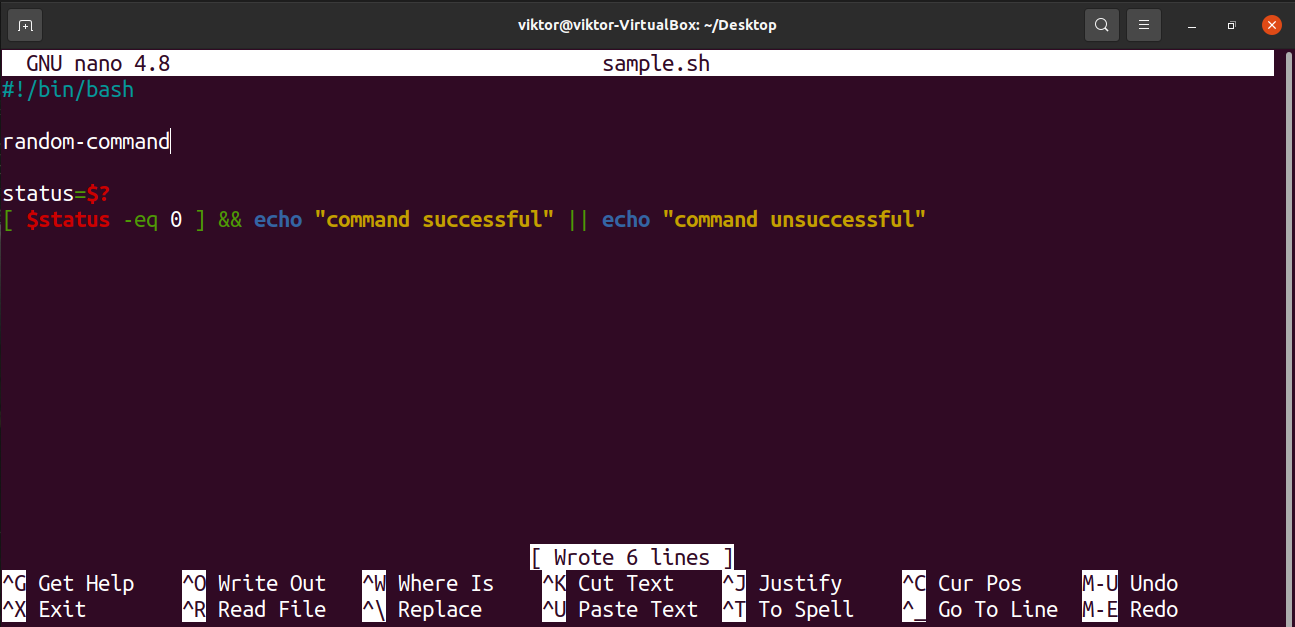
When being run, the output will be different.

Exit Code Value Explanation
When the exit code is non-zero, the value ranges from 1 to 255. Now, what does this value mean?
While the value is limited, the explanation of each value is unique to the program/script. For example, “ls” and “grep” has different explanations for error code 1 and 2.


Defining Exit Status in Script
When writing a script, we can define custom exit code values. It’s a useful method for easier debugging. In bash scripts, it’s the “exit” command followed by the exit code value.
Per the convention, it’s recommended to assign exit code 0 for successful execution and use the rest (1-255) for possible errors. When reaching the exit command, the shell script execution will be terminated, so be careful of its placement.
Have a look at the following shell script. Here, if the condition is met, the script will terminate with the exit code 0. If the condition isn’t met, then the exit code will be 1.
$ #!/bin/bash
$ if [ [ » $(whoami) » ! = root ] ] ; then
$ echo «Not root user.»
$ exit 1
$ fi
$ echo «root user»
$ exit 0
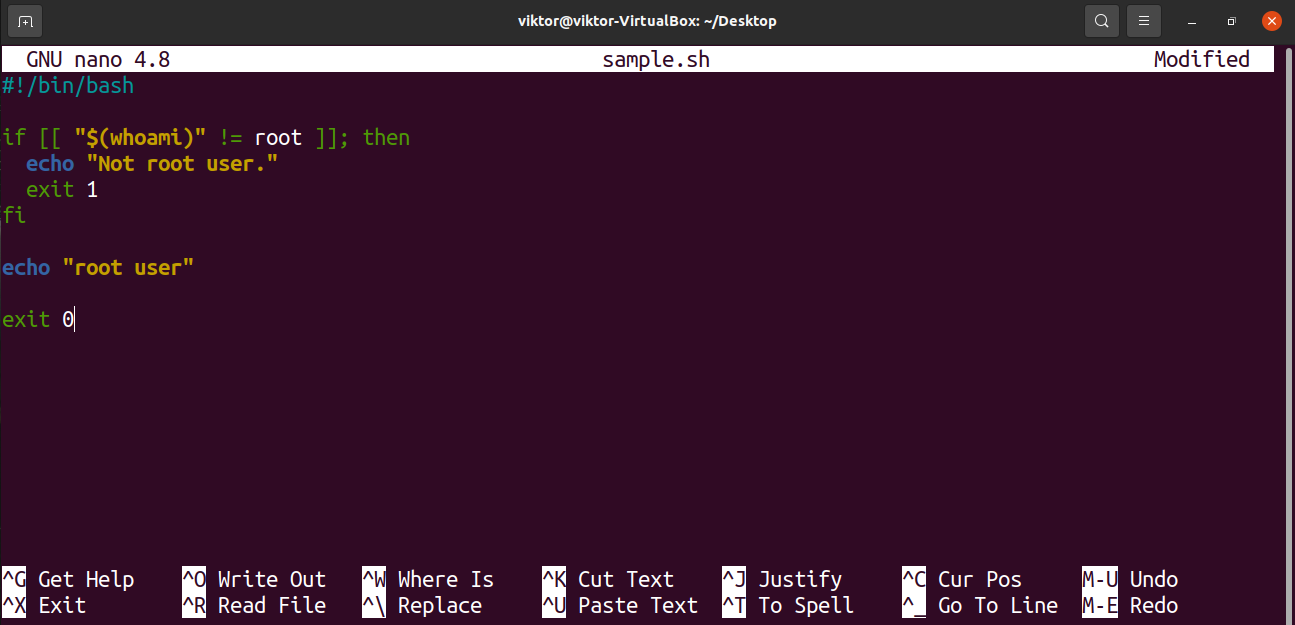
Verify the result of running this script without sudo privilege or “root” user.

Final Thoughts
This guide demonstrates what exit codes are and how you can use them. It also demonstrates how to assign appropriate exit codes in a bash script.
Interested in bash scripting? One of the easiest ways to get started is by writing your own scripts. Check out this simple guide on how to write a simple bash script.
About the author
Sidratul Muntaha
Student of CSE. I love Linux and playing with tech and gadgets. I use both Ubuntu and Linux Mint.
Как использовать коды завершения в Bash-скриптах

Инструменты автоматизации и мониторинга удобны тем, что разработчик может взять готовые скрипты, при необходимости адаптировать и использовать в своём проекте. Можно заметить, что в некоторых скриптах используются коды завершения (exit codes), а в других нет. О коде завершения легко забыть, но это очень полезный инструмент. Особенно важно использовать его в скриптах командной строки.
Что такое коды завершения
В Linux и других Unix-подобных операционных системах программы во время завершения могут передавать значение родительскому процессу. Это значение называется кодом завершения или состоянием завершения. В POSIX по соглашению действует стандарт: программа передаёт 0 при успешном исполнении и 1 или большее число при неудачном исполнении.
Почему это важно? Если смотреть на коды завершения в контексте скриптов для командной строки, ответ очевиден. Любой полезный Bash-скрипт неизбежно будет использоваться в других скриптах или его обернут в однострочник Bash. Это особенно актуально при использовании инструментов автоматизации типа SaltStack или инструментов мониторинга типа Nagios. Эти программы исполняют скрипт и проверяют статус завершения, чтобы определить, было ли исполнение успешным.
Кроме того, даже если вы не определяете коды завершения, они всё равно есть в ваших скриптах. Но без корректного определения кодов выхода можно столкнуться с проблемами: ложными сообщениями об успешном исполнении, которые могут повлиять на работу скрипта.
Что происходит, когда коды завершения не определены
В Linux любой код, запущенный в командной строке, имеет код завершения. Если код завершения не определён, Bash-скрипты используют код выхода последней запущенной команды. Чтобы лучше понять суть, обратите внимание на пример.
#!/bin/bash touch /root/test echo created file Этот скрипт запускает команды touch и echo . Если запустить этот скрипт без прав суперпользователя, команда touch не выполнится. В этот момент мы хотели бы получить информацию об ошибке с помощью соответствующего кода завершения. Чтобы проверить код выхода, достаточно ввести в командную строку специальную переменную $? . Она печатает код возврата последней запущенной команды.
Как видно, после запуска команды ./tmp.sh получаем код завершения 0 . Этот код говорит об успешном выполнении команды, хотя на самом деле команда не выполнилась. Скрипт из примера выше исполняет две команды: touch и echo . Поскольку код завершения не определён, получаем код выхода последней запущенной команды. Это команда echo , которая успешно выполнилась.
Если убрать из скрипта команду echo , можно получить код завершения команды touch .
Поскольку touch в данном случае — последняя запущенная команда, и она не выполнилась, получаем код возврата 1 .
Как использовать коды завершения в Bash-скриптах
Удаление из скрипта команды echo позволило нам получить код завершения. Что делать, если нужно сделать разные действия в случае успешного и неуспешного выполнения команды touch ? Речь идёт о печати stdout в случае успеха и stderr в случае неуспеха.
Проверяем коды завершения
Выше мы пользовались специальной переменной $? , чтобы получить код завершения скрипта. Также с помощью этой переменной можно проверить, выполнилась ли команда touch успешно.
#!/bin/bash touch /root/test 2> /dev/null if [ $? -eq 0 ] then echo "Successfully created file" else echo "Could not create file" >&2 fi После рефакторинга скрипта получаем такое поведение:
- Если команда touch выполняется с кодом 0 , скрипт с помощью echo сообщает об успешно созданном файле.
- Если команда touch выполняется с другим кодом, скрипт сообщает, что не смог создать файл.
Любой код завершения кроме 0 значит неудачную попытку создать файл. Скрипт с помощью echo отправляет сообщение о неудаче в stderr .
Создаём собственный код завершения
Наш скрипт уже сообщает об ошибке, если команда touch выполняется с ошибкой. Но в случае успешного выполнения команды мы всё также получаем код 0 .
Поскольку скрипт завершился с ошибкой, было бы не очень хорошей идеей передавать код успешного завершения в другую программу, которая использует этот скрипт. Чтобы добавить собственный код завершения, можно воспользоваться командой exit .
#!/bin/bash touch /root/test 2> /dev/null if [ $? -eq 0 ] then echo "Successfully created file" exit 0 else echo "Could not create file" >&2 exit 1 fi Теперь в случае успешного выполнения команды touch скрипт с помощью echo сообщает об успехе и завершается с кодом 0 . В противном случае скрипт печатает сообщение об ошибке при попытке создать файл и завершается с кодом 1 .
Как использовать коды завершения в командной строке
Скрипт уже умеет сообщать пользователям и программам об успешном или неуспешном выполнении. Теперь его можно использовать с другими инструментами администрирования или однострочниками командной строки.
В примере выше && используется для обозначения «и», а || для обозначения «или». В данном случае команда выполняет скрипт ./tmp.sh , а затем выполняет echo «bam» , если код завершения 0 . Если код завершения 1 , выполняется следующая команда в круглых скобках. Как видно, в скобках для группировки команд снова используются && и || .
Скрипт использует коды завершения, чтобы понять, была ли команда успешно выполнена. Если коды завершения используются некорректно, пользователь скрипта может получить неожиданные результаты при неудачном выполнении команды.
Дополнительные коды завершения
Команда exit принимает числа от 0 до 255 . В большинстве случаев можно обойтись кодами 0 и 1 . Однако есть зарезервированные коды, которые обозначают конкретные ошибки. Список зарезервированных кодов можно посмотреть в документации.
Адаптированный перевод статьи Understanding Exit Codes and how to use them in bash scripts by Benjamin Cane. Мнение администрации Хекслета может не совпадать с мнением автора оригинальной публикации.