- How to make sure only one instance of a Bash script is running at a time?
- 7 Answers 7
- Linux: Run a Bash Script Only Once at Startup
- Ensuring that a shell script runs exactly once
- Enter locks!
- A better lock!
- Use case for me
- Further reading:
- Run shell script exactly once with cronjob
- 1 Answer 1
- Linux: запустить bash скрипт при загрузке только один раз
How to make sure only one instance of a Bash script is running at a time?
I want to make a sh script that will only run at most once at any point. Say, if I exec the script then I go to exec the script again, how do I make it so that if the first exec of the script is still working the second one will fail with an error. I.e. I need to check if the script is running elsewhere before doing anything. How would I go about doing this?? The script I have runs a long running process (i.e. runs forever). I wanted to use something like cron to call the script every 15mins so in case the process fails, it will be restarted by the next cron run script.
7 Answers 7
You want a pid file, maybe something like this:
pidfile=/path/to/pidfile if [ -f "$pidfile" ] && kill -0 `cat $pidfile` 2>/dev/null; then echo still running exit 1 fi echo $$ > $pidfile If you mean on the kill command, the -0 indicates that the process is still running but does not touch it if it is. The 2>/dev/null will discard any unwanted noise in case the process is in fact not running.
I have read that PID files are not a good way to solve this problem. Given that some process can take the same PID etc.
It is possible for a process ID to be reused, this is true. If you’re really worried about this, you might use the flock(1) program by Peter Anvin, which ships with the util-linux distribution.
The second article uses «hand-made lock file» and shows how to catch script termination & releasing the lock; although using lockfile -l will probably be a good enough alternative for most cases.
Example of usage without timeout:
lockfile script.lock rm -f script.lock Will ensure that any second script started during this one will wait indefinitely for the file to be removed before proceeding.
If we know that the script should not run more than X seconds, and the script.lock is still there, that probably means previous instance of the script was killed before it removed script.lock . In that case we can tell lockfile to force re-create the lock after a timeout (X = 10 below):
lockfile -l 10 /tmp/mylockfile rm -f /tmp/mylockfile Since lockfile can create multiple lock files, there is a parameter to guide it how long it should wait before retrying to acquire the next file it needs ( — and -r ). There is also a parameter -s for wait time when the lock has been removed by force (which kind of complements the timeout used to wait before force-breaking the lock).
Linux: Run a Bash Script Only Once at Startup
In this article, we will look at how to run a bash script only on the first user login to Linux (or only on the first boot).
On Linux, you can run scripts at user login via these files:
If you want to run the bash script for a specific user only, you need to specify the bash script files in their profile ( ~/.profile ). If you want to run the script for all users, you must place it in the /etc/profile.d directory.
Here is an example bash script that creates a .logon_script_done file in the user’s profile when executed. The next time the script is run, it checks if this file exists, and if it does, the bash script code stops running.
#!/bin/bash if [ -e $HOME/.logon_script_done ] then echo "No actions to do" else echo "First run of the script. Performing some actions" >> $HOME/run-once.txt touch $HOME/.logon_script_done fi Save the code to the file user_provision.sh and allow the file to be run:
Now you need to add a path to the script at the end of the .profile file:
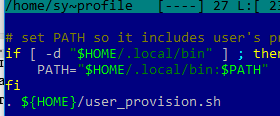
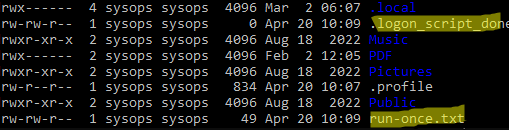
Log out (exit) and log in again. A run-once.txt file will be created in the user profile.
The code from the bash script will not run the next time the user logs in.
Ensuring that a shell script runs exactly once
Many times, we have shell scripts which perform some important stuff like inserting into database, mailing reports, etc which we want to run exactly one instance of.
Enter locks!
A simple solution is to create a «lock file» and check if the file exists when the script starts. If the file is already created, it means another instance of that program is running, so we can fail with message «Try again later!». Once the script completes running, it will clean-up and delete the lock file.
LOCK_FILE=a.lock if [ -f "$LOCK_FILE" ]; then # Lock file already exists, exit the script echo "An instance of this script is already running" exit 1 fi # Create the lock file echo "Locked" > "$LOCK_FILE" # Do the normal stuff # clean-up before exit rm "$LOCK_FILE" This looks promising but there are issues with this approach. What happens if the script does not end correctly i.e it exits because of some failure before it reaches the clean-up part of the code? Or if it gets forcibly terminated with Ctrl+C or kill command? In both these cases, the created lock file will not be deleted. So next time you run the script, you will always get an error and will have to manually delete the file. There is another, more subtle error with the above code. A race condition. If two instances of scripts are started around the same time, it is possible that both of them get past the if [ -f «$LOCK_FILE» ] because the second instance may reach that part of the code before the first instance is able to create the lock file. Thus, we have more than one instance running.
A better lock!
Is there a way to create a lock file which is more robust to race conditions and non-standard termination ( Ctrl+C , kill command, etc)? Linux offers flock a utility to manage locks from shell scripts. Using flock , we can rewrite the above snippet as follows:
LOCK_FILE=a.lock exec 99>"$LOCK_FILE" flock -n 99 || exit 1 # Do stuff and exit! The exec 99>»$LOCK_FILE» creates a file descriptor numbered 99 and assigns it to LOCK_FILE . File descriptors (fd) 0, 1, 2 are for stdin , stdout , stderr respectively. We are creating new fd with a high number to ensure that it does not clash with numbered fds opened later-on by script. flock -n 99 || exit 1 does 2 things. Firstly, it acquires an exclusive lock on the file descriptor 99 which refers to our LOCK_FILE . This operation is guaranteed by the linux kernel to be atomic. Secondly, if it fails to acquire the lock, it exits with return code 1. We do not need to worry about any clean up. flock will automatically release the lock when the script exits regardless of how it terminates. This solves our problem! What if I wanted to add a more informational message instead of exiting directly on failure to acquire lock? We can change the line flock -n 99 || exit 1 as follows:
flock -n 99 RC=$? if [ "$RC" != 0 ]; then # Send message and exit echo "Already running script. Try again after sometime" exit 1 fi The flock man page has an example which you can use to add an exclusive lock to start of any shell script:
[ "$FLOCKER>" != "$0" ] && exec env FLOCKER="$0" flock -en "$0" "$0" "$@" || : This boilerplate uses the script file itself as a lock. It works by setting an environment variable $FLOCKER to script file name and executing the script with its original parameters after acquiring the lock. On failure however, it does not print anything and silently exits. $0 here stands for name of the script. $@ stands for all arguments passed to the script when it was called.
Use case for me
My team uses a test machine where we deploy multiple branches of a code-base. We need to make sure that exactly one person is building the project at a particular time. The deploy script pulls the specified branch of code from git and builds the project, deploys the main service and starts ancillary services. The script takes sometime to execute. If someone tries to deploy another branch while a build is ongoing, both can fail. With the above snippet, calling the script more than once shows the current branch being built and exits with failure.
Further reading:
Run shell script exactly once with cronjob
I want ./commands.sh to run just once, because next hour, the cron will run again, pull from git, and run update.sh again. Is there some way for each unique ./commands.sh to run just once?
After writing that out, maybe the best way is just to only run update.sh if there was a change from the git repo?
This seems like overkill and hard to maintain. Is there a simpler way to write a bash script that only runs one time?
Is your problem that a former instance of commands.sh might still be running when the next update is due? Or who else is invoking the second instance?
Are you trying to use cron as if it were a process supervision system (responsible for keeping a daemon running, restarting it if it exits, but never starting more than one instance)? Because the best-practice answer there is «don’t» — there are real process supervision services built for the purpose, and they’ll do a better job.
. and similarly, if your goal is to run a command every time there’s content pushed to git . well, there are git -specific ways to do that that don’t have all the lag and general-purpose fail of relying on cron .
For a tiny embedded system, runit is your best bet; its authors make some effort to be sure that it works with tiny libc s (much smaller than glibc). See jtimberman.housepub.org/blog/2012/12/29/… (first Google link, but on browsing, I like what it has to say).
Why wouldn’t you just remove (delete) the ./commands.sh file from the system right after it’s done. it would never run again 🙂
1 Answer 1
At the start of the commands.sh script do this:
if [ -f stampfile ]; then exit if touch stampfile This checks for a file called stampfile (specify a path to anywhere convenient where this may be stored). If it’s there, just exit . If it’s not there create it with touch .
Then let the script do its thing.
A slight digression: This can also be used to avoid having two instances of a script running at the same time. The script would then rm -f stampfile at the end of its run.
In this case, if the script is killed, the stampfile will be «stale» (stamp present but script not alive). To detect a stale stampfile , put the PID of the script into it instead of touching it.
To check if there’s another instance running, and managing the stampfile:
if [ -f stampfile ]; then if kill -0 $(/dev/null; then exit else rm -f stampfile # stale fi fi echo $$ >stampfile # rest of script rm -f stampfile User @CharlesDuffy points out that this way of managing the stampfile may be prone to PID reuse issues, i.e. that the PID in a stale stampfile might be that of a running process that has nothing to do with any of this. There is apparently a Linux utility called flock that allows you to do this in a more robust way.
Linux: запустить bash скрипт при загрузке только один раз
В этой статье мы рассмотрим, как запустить bash скрипт только при первом входе пользователя в Linux (или только при первой загрузке).
В Linux вы можете запускать скрипты при входе пользователей через следующие файлы:
Если нужно выполнить скрипт только для одного определенного пользователя, нужно указать путь к файлу bash скрипта в его профиле (~/.profile). Если нужно запускать скрипт для всех пользователей, нужно поместить его в директорию /etc/profile.d.
В этом примере bash скрипт при первом запуске создает файл .logon_script_done в профиле пользователя. При следующем запуске скрипт проверяет наличие этого файла, и если он существует, код bash скрипта далее не выполняется.
#!/bin/bash
if [ -e $HOME/.logon_script_done ]
then
echo «No actions to do»
else
echo «First run of the script. Performing some actions» >> $HOME/run-once.txt
touch $HOME/.logon_script_done
fi
Сохраните код в файл user_provision.sh и разрешите запуск файла:
Теперь добавьте ссылку на скрипт в конец файла (.profile):
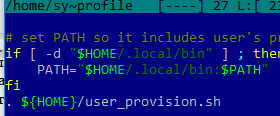

Завершите сеанс (exit) и войдите еще раз. В профиле будет создан файл run-once.txt
При следующем входе пользователя код из bash скрипта не будет выполняться.