- replace substring in lines using sed or grep
- 2 Answers 2
- SED search and replace substring in a database file
- 2 Answers 2
- Edit, per your comments
- Another edit!
- Replacing a Substring With Another String in Bash
- Replace substring natively in bash (good for a single line)
- Replacing all occurrences of a substring
- Replace string using sed command (can work on files as well)
- Sed for replace a substring inside a string with a pattern
- 1 Answer 1
- Explanation
replace substring in lines using sed or grep
Right. You’re using a / as a delimiter for your substitution. The command is s/pattern/replacement/ and you’re missing the final delimiter. That’s what «unterminated» means.
2 Answers 2
The grep command won’t «replace» text, it is for «global regular expression print». But sed will.
sed -i'' '/^videoId: /s/: .*/: '"$id"'/;/^var vid_seq=/s/=.*/='"$id_seq"';/' I’m not a big fan of inserting variables into sed scripts this way, but sed is simple, and provides no mechanism for actually using actual variables on its own. If you’re going to do this, include some format checking for the two variables to make sure they contain the data you want them to contain, before you run this sed script. An accidental / in a variable would cause the sed script to fail.
UPDATE per comments:
$ id_seq=80 $ cat inp686 videoId: 'S2Rgr6yuuXQ' var vid_seq=1; $ sed '/^videoId: /s/: .*/: '"$id"'/;/^var vid_seq=/s/=.*/='"$id_seq"';/' < inp686 videoId: fsafsferii2 var vid_seq=80; $ Of course, you'll need to do some quote magic to get the single quotes into your videoId, but I'm sure you can figure that out yourself.
According to sed's man page, the substitute command is in the form:
[2addr]s/regular expression/replacement/flags The [2addr] means you can specify up to two "addresses", which can be line numbers or regular expressions to match. So the s (substitute) command can take a line, a range, a match, or a span between matches. In our case, we're just using a single match to identify what lines we want to execute the substitution on.
The script above is made up of two sed commands, separated by a semicolon.
- /^videoId: / -- Match lines that start with the word videoId: .
- s/: .*/: '"$id"'/; -- Substitute all text from the colon to the end of the line with whatever is in the $id environment variable.
- s/=.*/='"$id_seq"';/ -- Substitute all text from the equals sign on with $id_seq .
Note that the '"$id"' construct means that we are exiting the single quotes, then immediately entering double quotes for the expansion of the variable . then exiting the double quotes and going back into a new set of single quotes. Sed scripts are safest inside single quotes because of the frequent use of characters that might be interpreted by a shell.
Note also that because sed's substitute command uses a forward slash as a delimiter, the $id and $id_seq variables may not contain a slash. If they might, you can switch to a different delimiter.
SED search and replace substring in a database file
To all, I have spent alot of time searching for a solution to this but cannot find it. Just for a background, I have a text database with thousands of records. Each record is delineated by : "0 @nnnnnn@ Xnnn" // no quotes The records have many fields on a line of their own, but the field I am interested in to search and replace a substring (notice spaces) : " 1 X94 User1.faculty.ventura.ca" // no quotes I want to use sed to change the substring ".faculty.ventura.ca" to ".students.moorpark.ut", changing nothing else on the line, globally for ALL records. I have tested many things with negative results. How can this be done ? Thank You for the assistance. Bob Perez (robertperez1957@gmail.com)
2 Answers 2
If I understand you correctly, you want this:
sed 's/1 X94 \(.*\).faculty.ventura.ca/1 X94 \1.students.moorpark.ut/' mydatabase.fileThis will replace all records of the form 1 X94 XXXXXX.faculty.ventura.ca with 1 X94 XXXXX.students.moorpark.ut .
Here's details on what it all does:
- The '' let you have spaces and other messes in your script.
- s/ means substitute
- 1 X94 \(.*\).faculty.ventura.ca is what you'll be substituting. The \(.*\) stores anything in that regular expression for use in the replacement
- 1 X94 \1.students.moorpark.ut is what to replace the thing you found with. \1 is filled in with the first thing that matched \(.*\) . (You can have multiple of those in one line, and the next one would then be \2.)
- The final / just tells sed that you're done. If your database doesn't have linefeeds to separate its records, you'll want to end with /g , to make this change multiple times per line.
- mydatabase.file should be the filename of your database.
Note that this will output to standard out. You'll probably want to add
to the end of your line, to save all the output in a file. (It won't do you much good on your terminal.)
Edit, per your comments
If you want to replace 1 F94 bperez.students.Napvil.NCC to 1 F94 bperez.JohnSmith.customer , you can use another set of \(.*\) , as:
sed 's/1 X94 \(.*\).\(.*\).Napvil.NCC/1 X94 \1.JohnSmith.customer/' 251-2.txtThis is similar to the above, except that it matches two stored parameters. In this example, \1 evaluates to bperez and \2 evaluates to students . We match \2 , but don't use it in the replace part of the expression. You can do this with any number of stored parameters. (Sed probably has some limit, but I've never hit a sufficiently complicated string to hit it.) For example, we could make the sed script be '\(.\) \(. \) \(.*\).\(.*\).\(.*\).\(.*\)/\1 \2 \3.JohnSmith.customer/' , and this would make \1 = 1, \2 = X94, \3 = bperez, \4 = Napvil and \5 = NCC, and we'd ignore \4 and \5. This is actually not the best answer though - just showing it can be done. It's not the best because it's uglier, and also because it's more accepting. It would then do a find and replace on a line like 2 Z12 bperez.a.b.c , which is presumably not what you want. The find query I put in the edit is as specific as possible while still being general enough to suit your tasks.
Another edit!
You know how I said "be as specific as possible"? Due to the . character being special, I wasn't. In fact, I was very generic. The . means "match any character at all," instead of "match a period". Regular expressions are "greedy", matching the most they could, so \(.*\).\(.*\) will always fill the first \(.*\) (which says, "take 0 to many of any character and save it as a match for later") as far as it can. Try using:
sed 's/1 X94 \(.*\)\.\(.*\).Napvil.NCC/1 X94 \1.JohnSmith.customer/' 251-2.txtThat extra \ acts as an escape sequence, and changes the . from "any character" to "just the period". FYI, since I don't (but should) escape the other periods, technically sed would consider 1 X94 XXXX.StdntZNapvilQNCC as a valid match. Since . means any character, a Z or a Q there would be considered a fit.
Replacing a Substring With Another String in Bash
Learn how to replace a single or multiple occurrences of a substring inside a string in Bash.
Here's the scenario. You have a big string and you want to replace part of it with another string.
For example, you want to change "I am writing a line today" to "I am writing a line now".
In this quick tutorial, I'll show you how to replace a substring natively in Bash. I'll also show the sed command example as an extension.
Replace substring natively in bash (good for a single line)
Bash has some built-in methods for string manipulation. If you want to replace part of a string with another, this is how you do it:
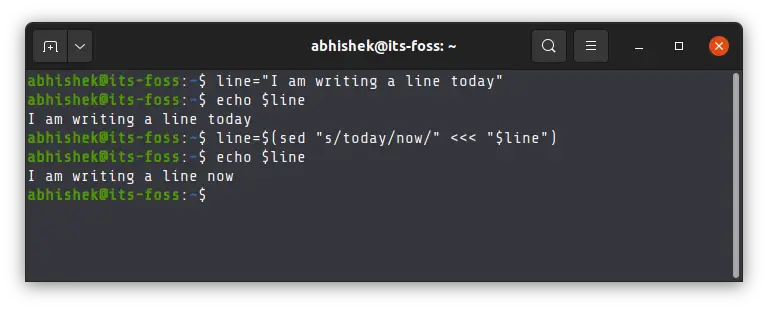
Create a string variable consisting of the line: “I am writing a line today” without the quotes and then replace today with now :
[email protected]:~$ line="I am writing a line today" [email protected]:~$ echo "$" I am writing a line nowDid you understand what just happened? In the syntax "$" , line is the name of the variable where I've just stored the entire sentence. Here, I'm instructing it to replace the first occurrence of the word today with now . So instead of displaying the contents of the original variable, it showed you the line with the changed word.
Hence, the line variable hasn't actually changed. It is still the same:
[email protected]:~$ echo $line I am writing a line todayBut you can definitely replace the word you want to and modify the same variable to make the changes permanent:
[email protected]:~$ line="$" [email protected]:~$ echo $line I am writing a line nowNow the changes have been made permanent and that's how you can permanently replace the first occurrence of a substring in a string.
You can also use other variables to store specific substrings that you wish to replace:
[email protected]:~$ replace="now" [email protected]:~$ replacewith="today" [email protected]:~$ line="$/$>" [email protected]ktop:~$ echo $line I am writing a line todayHere, I stored the word to be replaced in a variable called replace and the word that it would be replaced with inside replacewith . After that, I used the same method as discussed above to “revise” the line. Now, the changes I had made in the beginning of this tutorial have been reverted.
Let us look at another example:
[email protected]:~$ hbday="Happy Birthday! Many Many Happy Returns!" [email protected]:~$ hbday="$" [email protected]:~$ echo $hbday Happy Birthday! So Many Many Happy Returns!Replacing all occurrences of a substring
You can also replace multiple occurrences of substrings inside strings. Let's see it through another example:
[email protected]:~$ hbday="$" [email protected]:~$ echo $hbday Happy Birthday! So Many So Many Happy Returns!That extra / after hbday made it replace all occurrences of Many with So Many inside the sentence.

Replace string using sed command (can work on files as well)
Here's another way for replacing substrings in a string in bash. Use the sed command in this manner:
Replace the first occurrence:
line=$(sed "s/$replace/s//$replacewith/"If I take the first example, it can be played as:

You can also replace all occurrences by adding g at the end:
line=$(sed "s/$replace/$replacewith/g"Now, you may think this is more complicated than the native bash string method. Perhaps, but sed is very powerful and you can use it to replace all the occurrences of a string in a file.
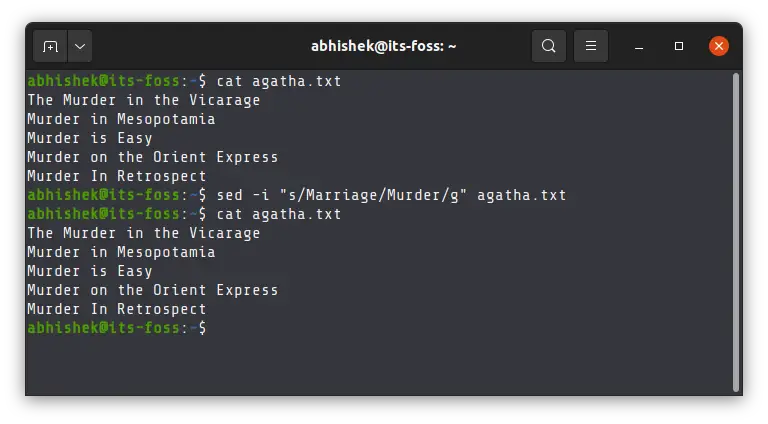
sed -i 's/$replace/$replacewith/' filenameHere's an example of some of Agatha Christie's books with 'Murder' in the title:
[email protected]:~$ cat agatha.txt The Murder in the Vicarage Murder in Mesopotamia Murder is Easy Murder on the Orient Express Murder In RetrospectI am going to replace Murder with Marriage because some people think both are the same:
sed -i "s/Murder/Marriage/g" agatha.txtAnd here's the changed file now:
The Marriage in the Vicarage Marriage in Mesopotamia Marriage is Easy Marriage on the Orient Express Marriage In RetrospectSed is a very powerful tool for editing text files in Linux. You should at least learn its basics.
Now that you know about replacing substrings, how about splitting strings into substrings in bash?
Did you enjoy reading this article? If you have anything to share about replacing strings or this article, please do so in the comments below.
Sed for replace a substring inside a string with a pattern
I am trying to replace a part of a pattern, such as, if I have col(3,B,14) , after applying the sed command, I would like to get col(3,B,t14) which adds the t character to the third parameter in the pattern. I am trying with :
s="col(3,B,14)" echo $s | sed 's/col(5,[A-Z],2)/col(5,[A-Z],t8)/g'Thank you FedonKadifeli, yes I follow you advice and I found the solution : echo $s | sed -E 's/col((.*),(.*),(.*))/col\1,\2,t\3)/g' using the back references as you suggest. Thank very much.
1 Answer 1
You seem a bit confused about how sed works, so I'll go step by step. My "answer" is this:
s="col(3,B,14)"; echo $s | sed 's/\(col(6,[A-Z],\)/\1t/g'Explanation
There are a couple of problems here.
- First, you need a semicolon ( ; ) after defining your variable s , before echo ing it.
echo hello world | sed 's/o/z/g'echo hello world | sed 's/o/z/'s="col(3,B,14)"; echo $s | sed 's/col(4,[A-Z],4)/replacement/g's="col(3,B,14)"; echo $s | sed 's/\(col(2,[A-Z],\)/\1replacement/g'This will match col(
,, , so up to and including the point where you want to add a t . All of this matched stuff will be put back in the replacement ( \1 ) followed by any text you add (in this case we're adding the literal text "replacement"). Any remaining text not matched in the input will be unaffected. The above will output: s="col(3,B,14)"; echo $s | sed 's/\(col(1,[A-Z],\)/\1t/g'