- 🐧 Удаление повторяющихся строк из текстового файла с помощью командной строки Linux
- Пример 1
- Пример 2
- Пример 3
- Пример 4
- How to delete duplicate lines in a file without sorting it in Unix
- 9 Answers 9
- The first solution is also from http://sed.sourceforge.net/sed1line.txt
- The second solution is easy to understand (from myself):
🐧 Удаление повторяющихся строк из текстового файла с помощью командной строки Linux

Удаление повторяющихся строк из текстового файла можно выполнить из командной строки Linux.
Такая задача может быть более распространенной и необходимой, чем вы думаете.
Чаще всего это может быть полезно при работе с файлами логов.
Зачастую файлы логов повторяют одну и ту же информацию снова и снова, что делает практически невозможным просмотр файлов.
В этом руководстве мы покажем различные примеры из командной строки, которые вы можете использовать для удаления повторяющихся строк из текстового файла.
Попробуйте некоторые команды в своей системе и используйте ту, которая наиболее удобна для вашего сценария.
Эти примеры будут работать в любом дистрибутиве Linux при условии, что вы используете оболочку Bash.
В нашем примере сценария мы будем работать с файлом, который просто содержит имена различных дистрибутивов Linux.
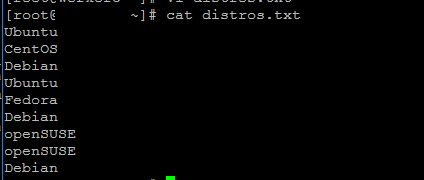
Это очень простой текстовый файл для примера, но на самом деле вы можете использовать эти методы для документов, содержащих даже тысячи повторяющихся строк.
Мы увидим, как удалить все дубликаты из этого файла, используя приведенные ниже примеры.
$ cat distros.txt Ubuntu CentOS Debian Ubuntu Fedora Debian openSUSE openSUSE Debian
Пример 1
Команда uniq может изолировать все уникальные строки из нашего файла, но это работает только в том случае, если повторяющиеся строки находятся рядом друг с другом.
$ sort distros.txt | uniq CentOS Debian Fedora openSUSE Ubuntu
Чтобы упростить задачу, мы можем просто использовать -u с sort, чтобы получить тот же точный результат, вместо перехода к uniq.
$ sort -u distros.txt CentOS Debian Fedora openSUSE Ubuntu
Пример 2
Чтобы увидеть, сколько повторений каждой строки находится в файле, мы можем использовать параметр -c (count) с uniq.
$ sort distros.txt | uniq -c 1 CentOS 3 Debian 1 Fedora 2 openSUSE 2 Ubuntu
Пример 3
Чтобы увидеть наиболее часто повторяющиеся строки, мы можем передать по пайпу еще одну команду sort с параметрами -n (числовая сортировка) и -r в обратном направлении.
Это позволяет нам быстро увидеть, какие строки в файле больше всего дублируются – еще один удобный вариант для просмотра логов.
$ sort distros.txt | uniq -c | sort -nr 3 Debian 2 Ubuntu 2 openSUSE 1 Fedora 1 CentOS
Пример 4
Одна из проблем с использованием предыдущих команд заключается в том, что мы полагаемся на сортировку.
Это означает, что наш окончательный результат отсортирован по алфавиту или по количеству повторов, как в предыдущем примере.
Иногда это может быть хорошо, но что, если нам нужно, чтобы текстовый файл сохранил свой предыдущий порядок?
Мы можем удалить повторяющиеся строки без сортировки файла, используя команду awk в следующем синтаксисе.
$ awk '!seen[__g5_token60a1f36c18105]++' distros.txt Ubuntu CentOS Debian Fedora openSUSE
С помощью этой команды сохраняется первое вхождение строки, а будущие повторяющиеся строки удаляются из вывода.
How to delete duplicate lines in a file without sorting it in Unix
Is there a way to delete duplicate lines in a file in Unix? I can do it with sort -u and uniq commands, but I want to use sed or awk . Is that possible?
and otherwise, I believe it’s possible with awk , but will be quite resource consuming on bigger files.
Duplicates stackoverflow.com/q/24324350 and stackoverflow.com/q/11532157 have interesting answers which should ideally be migrated here.
@tripleee especially the cat -n | sort -k2 -u | . one, which can cope with files that are too large to be processed in-memory
9 Answers 9
seen is an associative array that AWK will pass every line of the file to. If a line isn’t in the array then seen[$0] will evaluate to false. The ! is the logical NOT operator and will invert the false to true. AWK will print the lines where the expression evaluates to true.
The ++ increments seen so that seen[$0] == 1 after the first time a line is found and then seen[$0] == 2 , and so on. AWK evaluates everything but 0 and «» (empty string) to true. If a duplicate line is placed in seen then !seen[$0] will evaluate to false and the line will not be written to the output.
An important caveat here: if you need to do this for multiple files, and you tack more files on the end of the command, or use a wildcard… the ‘seen’ array will fill up with duplicate lines from ALL the files. If you instead want to treat each file independently, you’ll need to do something like for f in *.txt; do gawk -i inplace ‘!seen[$0]++’ «$f»; done
It also works thanks to the fact that the result of ‘++’ operator is not the value after increment, but the previous value.
# delete duplicate, consecutive lines from a file (emulates "uniq"). # First line in a set of duplicate lines is kept, rest are deleted. sed '$!N; /^\(.*\)\n\1$/!P; D' # delete duplicate, nonconsecutive lines from a file. Beware not to # overflow the buffer size of the hold space, or else use GNU sed. sed -n 'G; s/\n/&&/; /^\([ -~]*\n\).*\n\1/d; s/\n//; h; P' ‘$!N; /^(.*)\n\1$/!P; D’ means «If you’re not at the last line, read in another line. Now look at what you have and if it ISN’T stuff followed by a newline and then the same stuff again, print out the stuff. Now delete the stuff (up to the newline).»
‘G; s/\n/&&/; /^([ -~]*\n).*\n\1/d; s/\n//; h; P’ means, roughly, «Append the whole hold space this line, then if you see a duplicated line throw the whole thing out, otherwise copy the whole mess back into the hold space and print the first part (which is the line you just read.»
Is the $! part necessary? Doesn’t sed ‘N; /^\(.*\)\n\1$/!P; D’ do the same thing? I can’t come up with an example where the two are different on my machine (fwiw I did try an empty line at the end with both versions and they were both fine).
Almost 7 years later and no one answered @amichair .
This variation removes trailing white space before comparing:
perl -lne 's/\s*$//; print if ! $x++' file This variation edits the file in-place:
perl -i -ne 'print if ! $x++' file This variation edits the file in-place, and makes a backup file.bak :
perl -i.bak -ne 'print if ! $x++' file An alternative way using Vim (Vi compatible):
Delete duplicate, consecutive lines from a file:
Delete duplicate, nonconsecutive and nonempty lines from a file:
The one-liner that Andre Miller posted works except for recent versions of sed when the input file ends with a blank line and no characterss. On my Mac my CPU just spins.
This is an infinite loop if the last line is blank and doesn’t have any characterss:
It doesn’t hang, but you lose the last line:
The explanation is at the very end of the sed FAQ:
The GNU sed maintainer felt that despite the portability problems
this would cause, changing the N command to print (rather than
delete) the pattern space was more consistent with one’s intuitions
about how a command to «append the Next line» ought to behave.
Another fact favoring the change was that «» will
delete the last line if the file has an odd number of lines, but
print the last line if the file has an even number of lines.
To convert scripts which used the former behavior of N (deleting
the pattern space upon reaching the EOF) to scripts compatible with
all versions of sed, change a lone «N;» to «$d;N;».
The first solution is also from http://sed.sourceforge.net/sed1line.txt
$ echo -e '1\n2\n2\n3\n3\n3\n4\n4\n4\n4\n5' |sed -nr '$!N;/^(.*)\n\1$/!P;D' 1 2 3 4 5 Print only once of each duplicate consecutive lines at its last appearance and use the D command to implement the loop.
- $!N; : if the current line is not the last line, use the N command to read the next line into the pattern space.
- /^(.*)\n\1$/!P : if the contents of the current pattern space is two duplicate strings separated by \n , which means the next line is the same with current line, we can not print it according to our core idea; otherwise, which means the current line is the last appearance of all of its duplicate consecutive lines. We can now use the P command to print the characters in the current pattern space until \n ( \n also printed).
- D : we use the D command to delete the characters in the current pattern space until \n ( \n also deleted), and then the content of pattern space is the next line.
- and the D command will force sed to jump to its first command $!N , but not read the next line from a file or standard input stream.
The second solution is easy to understand (from myself):
$ echo -e '1\n2\n2\n3\n3\n3\n4\n4\n4\n4\n5' |sed -nr 'p;:loop;$!N;s/^(.*)\n\1$/\1/;tloop;D' 1 2 3 4 5 print only once of each duplicate consecutive lines at its first appearance and use the : command and t command to implement LOOP.
- read a new line from the input stream or file and print it once.
- use the :loop command to set a label named loop.
- use N to read the next line into the pattern space.
- use s/^(.*)\n\1$/\1/ to delete the current line if the next line is the same with the current line. We use the s command to do the delete action.
- if the s command is executed successfully, then use the tloop command to force sed to jump to the label named loop, which will do the same loop to the next lines until there are no duplicate consecutive lines of the line which is latest printed; otherwise, use the D command to delete the line which is the same with the latest-printed line, and force sed to jump to the first command, which is the p command. The content of the current pattern space is the next new line.
same command on Windows with busybox: busybox echo -e «1\n2\n2\n3\n3\n3\n4\n4\n4\n4\n5» | busybox sed -nr «$!N;/^(.*)\n\1$/!P;D»
uniq would be fooled by trailing spaces and tabs. In order to emulate how a human makes comparison, I am trimming all trailing spaces and tabs before comparison.
I think that the $!N; needs curly braces or else it continues, and that is the cause of the infinite loop.
I have Bash 5.0 and sed 4.7 in Ubuntu 20.10 (Groovy Gorilla). The second one-liner did not work, at the character set match.
The are three variations. The first is to eliminate adjacent repeat lines, the second to eliminate repeat lines wherever they occur, and the third to eliminate all but the last instance of lines in file.
# First line in a set of duplicate lines is kept, rest are deleted. # Emulate human eyes on trailing spaces and tabs by trimming those. # Use after norepeat() to dedupe blank lines. dedupe() < sed -E ' $!< N; s/[ \t]+$//; /^(.*)\n\1$/!P; D; >'; > # Delete duplicate, nonconsecutive lines from a file. Ignore blank # lines. Trailing spaces and tabs are trimmed to humanize comparisons # squeeze blank lines to one norepeat() < sed -n -E ' s/[ \t]+$//; G; /^(\n)/d; /^([^\n]+).*\n\1(\n|$)/d; h; P; '; > lastrepeat() < sed -n -E ' s/[ \t]+$//; /^$/< H; d; >; G; # delete previous repeated line if found s/^([^\n]+)(.*)(\n\1(\n.*|$))/\1\2\4/; # after searching for previous repeat, move tested last line to end s/^([^\n]+)(\n)(.*)/\3\2\1/; $!< h; d; >; # squeeze blank lines to one s/(\n)/\n\n/g; s/^\n//; p; '; >