- unixforum.org
- sed — как убрать пробелы, табы, переносы строк и слеши
- sed — как убрать пробелы, табы, переносы строк и слеши
- Re: sed — как убрать пробелы, табы, переносы строк и слеши
- Re: sed — как убрать пробелы, табы, переносы строк и слеши
- Re: sed — как убрать пробелы, табы, переносы строк и слеши
- Re: sed — как убрать пробелы, табы, переносы строк и слеши
- Команда sed в Linux
- Синтаксис
- Особенности адресов, предающихся утилите «sed»
- Регулярные выражения
- Команды
- Примеры
unixforum.org
sed — как убрать пробелы, табы, переносы строк и слеши
sed — как убрать пробелы, табы, переносы строк и слеши
Сообщение hikkispb » 25.05.2022 20:09
Имеются куча таких примеров с ненужными переводами строк, лишними пробелами, обратными слешами маркерами переноса строки.
convert present.gif -bordercolor white -border 1x1 \ -fill red -draw 'color 0,0 floodfill' \ -shave 1x1 present_bgnd.gif https://legacy.imagemagick.org/Usage/color_basics/#replace Нужно средствами sed превратить это в одну строку без лишних пробелов, переносов строк, и маркеров \ в конце (!) строки.
И завернуть это в xclip, чтобы брать исходный вариант из буфера иксов.
Почти всё я умею под отдельности, но не настолько хорошо знаю sed, чтобы уместить в один скрипт. ХЕЛП.
вставить буфер обмена X
echo $(xclip -o)
Удалить двойные пробелы:
printf «one two three» | sed ‘s/ \/ /g’
Удалить переносы строк:
printf «line1 \nline2\n» | sed ‘:a; /$/N; s/\n//; ta’
Да, я знаю, что можно и так, но я не хочу конвеерный зверинец с разными утилитами.
printf «line1 \nline2\n» | tr -d ‘\n’
Bizdelnick Модератор Сообщения: 20387 Статус: nulla salus bello ОС: Debian GNU/Linux
Re: sed — как убрать пробелы, табы, переносы строк и слеши
Сообщение Bizdelnick » 26.05.2022 00:42
Как-то так sed -E ‘:getline s/\\$//; T endline; N; b getline; :endline s/\s+/ /g’ (проверял только в GNU sed).
| в консоли вку́пе (с чем-либо) в общем вообще | в течение (часа) новичок нюанс по умолчанию | приемлемо проблема пробовать трафик |
Re: sed — как убрать пробелы, табы, переносы строк и слеши
Сообщение hikkispb » 26.05.2022 04:18
printf "line1 \ \nline2\n" | sed -E ':getline s/\\$//; T endline; N; b getline; :endline s/\s+/ /g' line1 \ line2 Bizdelnick Модератор Сообщения: 20387 Статус: nulla salus bello ОС: Debian GNU/Linux
Re: sed — как убрать пробелы, табы, переносы строк и слеши
Сообщение Bizdelnick » 26.05.2022 13:07
Так а зачем там пробел после ‘\’? Расчёт был на синтаксически корректный скрипт, если на входе что-то другое — адаптируйте.
% printf ‘line1 \\\nline2\n’ | sed -E ‘:getline s/\\$//; T endline; N; b getline; :endline s/\s+/ /g’
line1 line2
% sed —version
sed (GNU sed) 4.7
Упакован Debian
Copyright © 2018 Free Software Foundation, Inc.
Лицензия GPLv3+: GNU GPL версии 3 или новее
Это свободное ПО: вы можете изменять и распространять его.
Нет НИКАКИХ ГАРАНТИЙ до степени, разрешённой законом.
Авторы программы — Джей Фенласон (Jay Fenlason), Том Лорд (Tom Lord), Кен Пиццини (Ken Pizzini),
Паоло Бонзини (Paolo Bonzini), Jim Meyering и Assaf Gordon.
Домашняя страница GNU sed: .
Справка по работе с программами GNU: .
Сообщения об ошибках отправляйте на .
%
| в консоли вку́пе (с чем-либо) в общем вообще | в течение (часа) новичок нюанс по умолчанию | приемлемо проблема пробовать трафик |
Re: sed — как убрать пробелы, табы, переносы строк и слеши
Сообщение hikkispb » 26.05.2022 20:39
Поясните пожалуйста значения ключей. Что такое двоеточие, я знаю только точку с запятой — для многострочных скриптов в одной строке, и что за команды *line, я думал в sed только однобуквенные команды.
:getline s/\\$//; T endline; N; b getline; :endline s/\s+/ /g Пока оставил так. Но хотелось бы на самом деле не вывода в консоль, а ввода в активную строку и ожидания Enter для исполнения. А то всё равно лишняя работа остаётся.
xclip -o | sed -E ':getline s/\\$//; T endline; N; b getline; :endline s/\s+/ /g' #i.m.examplКоманда sed в Linux
Операционная система Linux для упрощения ее эксплуатации поддерживает множество специализированных команд. Утилита «sed» — это специфический редактор, позволяющий работать с текстом путем его замены. С помощью данной команды можно редактировать различные файлы без их открытия. Специальный редактор дает возможность найти, вставить, заменить или удалить определенные фрагменты в файле. Чтобы команда «sed» работала значительно быстрее, потребуется предварительно прописать данные и опции.
Синтаксис
- «-n» — дает возможность не выводить содержимое, присутствующее в буфере шаблона после каждой итерации.
- «-e» — позволяет выполнить команды, которые необходимы для редактирования текста.
- «-f» — дает возможность прочесть команды, которые были использованы при изменении файла.
- «-l». Опция позволяет указать требуемую длину строки.
- «-r». Опция применяется для включения поддержки синтаксиса расширенного типа, распространяющегося на активно используемые выражения.
- «-i». Функция предназначена для создания копии файла (в резерве) перед тем, как он будет отредактирован.
- «-s». Опция позволяет изучить несколько файлов единовременно. Они будут просмотрены не как длинные потоки, а как отдельные.
Чтобы выполнить несколько действий, используется аргумент «-e».
Первоначально кажется, что данная утилита очень сложная. На самом деле это не так, ей сможет пользоваться даже новичок в сфере программирования.
Стоит отметить, что данная утилита имеет два отдельно обособленных буфера – это основной и вспомогательный буфер (активного и пассивного плана). Первоначально они абсолютно пусты. Специальная программа передает предварительно определенные условия для всех строк передаваемого файла.
Первоначально программа «sed» изучает одну строку. Из нее удаляются все завершающие данные, а также символы, присутствующие в новой строке. Обрабатываемая стока помещается в главный буфер.
Далее выполняются команды, которые были переданы пользователем в параметрах. За каждой определенной командой закрепляется адрес. Он используется в качестве своеобразного условия. Команда пройдет лишь в том случае, если данное условие будет соблюдено.
После выполнения всех предписанных команд, содержимое буфера шаблона попадает в классический поток вывода. Это происходит в том случае, если предварительно не была указана функция «-n», которая ограничивает вывод содержимого.
Когда символ перевода изначально был удален, он добавляется обратно. Только после этого запускается следующая интерпретация, подразумевающая обработку новой строки.
Когда пользователь не планирует использование специальных команд, после завершения первой интерпретации все содержимое основного буфера будет удалено. Стоит отметить, что содержимое, которое относится к первоначально обработанной строке, сохраняется во вспомогательном буфере. Его применяют в дальнейшем при осуществлении задач.
Особенности адресов, предающихся утилите «sed»
Все команды получают свой адрес. Именно он указывает на строки, для которых выполняется команда:
- «номер». В данном случае прописывается номер определенной строки, где в последующем будет выполняться команда.
- «первая~шаг». Здесь команда выполняется для изначальной части строки, а далее – для всех остальных. В обязательном порядке указывается шаг.
- «$». Обрабатывается последняя строка, которая относится к выбранному вами файлу.
- «/часто используемое_выражение/». Здесь используется любая строка, подходящая по регулярному выражению. Оно не должно зависеть от особенностей регистра.
- «номер, номер». Обработка начинается с начала первой строки, а заканчивается концом второй строки.
- «номер,/регулярное_выражение/». Обработка начинается с первоначальной строки, заканчивается в той, которая соответствует информации в часто используемых фразах.
- «номер+количество». Обработка начинается с верхней строки, длится до той поры, пока не будет исчерпано предварительно указанное число строк.
- «номер~число». Обработка начинается со строки с определенным номеров. Она заканчивается той строкой, которая кратна определенному числовому обозначению.
Когда пользователь не желает задавать определенный адрес для программы «sed», она распространяется на все строки в файле. Если передается один адрес, команда выполняется до той строки, которая расположена по указанному адресу.
Есть возможность передавать диапазон адресов. Информация разделяется запятыми, а команда осуществляется для тех адресов, которые находятся в требуемом диапазоне.
Регулярные выражения
У пользователя есть возможность применить такие же часто используемые выражения, как и в иных наиболее распространенных языках программирования. Стоит рассмотреть ключевой список операторов, поддерживаемых программой «sed»:
- Различные символы и их количество (*).
- Более одного символа (\+).
- Один символ или его отсутствие (\?).
- Любые символы, их количество должно быть равно i (\).
- Любые символы, их количество должно находиться в пределах от I до j (\).
- Любые символы, их количество должно быть больше i (\).
Команды
Если пользователь планирует часто эксплуатировать «sed», он должен знать основной перечень команд, применяемых при редактировании. Стоит рассмотреть основные, которые применяются чаще всего:
- «q». Завершается действие сценария.
- «d». Удаляется первоначальный основной буфер шаблона, запускается следующая интерпретация цикла.
- «p». Выводится содержимое основного буфера.
- «n». Выводится состав основного буфера шаблона. Есть возможность переместить в него последующую строку.
- «s/что_прописать/на_что_поменять/опция». Заменяются символы, имеется возможность ограничить вывод с учетом часто используемых фраз.
- «y/символ/символ». Заменяются символы, присутствующие спереди строки, на те данные, которые имеются во 2 части.
- «w». Записывается содержимое основного буфера шаблона непосредственно в обрабатываемый файл.
- «N». Добавляется перевод строк в основной буфер.
- «D». Удаление основного буфера шаблона, начало интерации следующего цикла, когда в шаблоне не содержится новая строка.
- «g». Замена содержимого основного буфера на состав вспомогательного .
- «G». Добавление новых строчек в состав основного буфера. Сюда же добавляется состав вспомогательного буфера.
Стоит отметить, что утилите «sed» можно придать одновременно определенное количество команд. Для осуществления такой задачи потребуется разделить их точкой с запятой.
Примеры
Для первого примера, заменим каждое вхождение «пример» на «тест» в файле «dokument».
sed ‘s/пример/тест/g’ dokument
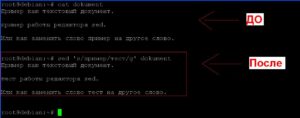
ВАЖНО! В операционной системе Линукс очень важен регистр имен. Как видно из скриншота «Пример» и «пример» — это разные слова.
Дополним команду таким образом, чтобы менялось не только слово «пример», но и это же слово написанное с большой буквы. Для этого будем использовать специальные символы «\|».
sed ‘s/пример\|Пример/тест/g’ dokument
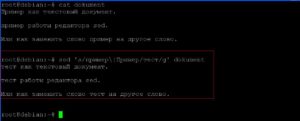
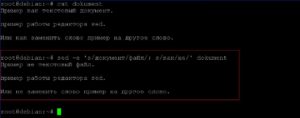
Заменим два фрагмента текста: «документ» на «файл»; «как» на «не». Так как у нас несколько фрагментов текстов, будем использовать ключ «-е».
sed -e ‘s/документ/файл/; s/как/не/’ dokument
Теперь сохраним все изменения в файл. Для это будем использовать ключ «-i» редактирования файла на месте.
sed -ie ‘s/документ/файл/; s/как/не/’ dokument
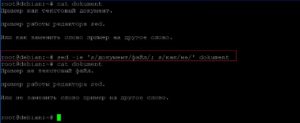
Удалим все пробелы в начале каждой строки слева.
sed ‘s/^[ \t]*//’ file
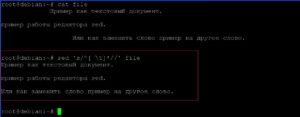
Теперь удалим все пропуски в конце строки.
sed ‘s/[ \t]*$//’ file
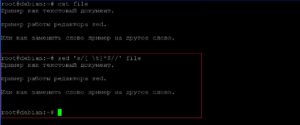
Удаление последней строки.
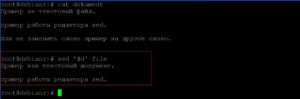
Добавление восьми пробелов в новый файл слева от текстовой информации. Будем использовать перенаправление вывода «>»
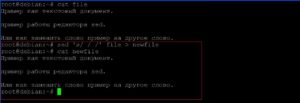
Выведение строк c 3 по 5 файла «newfile».
Выведение всего файла «newfile», кроме строк 3-5.
Удалим все пустые строки и сохраним эти изменения в файле.
Утилита «sed» является весьма гибким и максимально удобным инструментом, позволяющим сделать с текстом многие вещи. Такая команда отличается сложностью в усвоении, но дает решить множество задач.