How to automatically restart Linux services with Systemd
Getting your Linux deployments working reliably is of paramount concern for production applications. One way to guarantee that a service is always available is to ensure that it is automatically restarted in the event of a crash, and Systemd provides the necessary tools to make it happen.
A useful feature that is often needed for long-running processes such as web servers is the ability to automatically restart the process in the event of a crash in order to minimise downtime. If your service is being managed by Systemd, you can use the /etc/systemd/system/daemon.service
[Unit] Description=Your Daemon Name [Service] ExecStart=/path/to/executable Restart=on-failure RestartSec=1s [Install] WantedBy=multi-user.targetIn the above service configuration file, Restart is set to on-failure so that the service is restarted if the service exits with a non-zero exit code, or if terminated using a signal (such as using the kill command for example). The RestartSec option configures the amount of time to wait before restarting the service. Here, it’s set to one second to override the default value of 100ms.
After updating your Systemd unit file, ensure to run the command below to ensure your changes take effect:
$ sudo systemctl daemon-reloadTwo other useful options that you should be aware of are StartLimitIntervalSec and StartLimitBurst . They are both useful for configuring when Systemd should stop trying to restart a service. The former specifies a time interval in seconds, while the latter specifies the maximum amount of times that is allowed for the service to be restarted within the specified interval.
[Unit] Description=Your Daemon Name StartLimitIntervalSec=300 StartLimitBurst=5 [Service] ExecStart=/path/to/executable Restart=on-failure RestartSec=1s [Install] WantedBy=multi-user.targetAccording to the configuration above, the service is not allowed to restart more than five times within a 300 second interval. If the service crashes more than five times, it will not be permitted to start anymore.
After reloading the systemd manager configuration ( sudo systemctl daemon-reload ), kill your running service and confirm that it is automatically restarted after the time specified by RestartSec has elapsed.
About the Author

Ayo is a Software Developer by trade. He enjoys writing about diverse technologies in web development, mainly in Go and JavaScript/TypeScript.
Learn more.
Автоматический перезапуск сервиса Linux
Иногда сервисы ни с того ни с сего падают и приходиться их вручную восстанавливать. Если для пользователя домашнего компьютера это не критично, потому что если сервис падает во время разработки, то это даже хорошо, можно сразу увидеть что есть проблема. Но на серверах и VPS сервисы должны работать постоянно для обеспечения доступа к веб-сайту или приложению.
В этой инструкции я покажу как настроить автоматический перезапуск сервиса Linux несколькими способами: с помощью скрипта мониторинга периодически запускаемого через cron и в systemd.
Автоматический перезапуск сервиса в systemd
По умолчанию, если ваш сервис будет убит или завершится некорректно, systemd не будет с ним ничего делать. Но можно настроить сервис так, чтобы при падении или даже остановке он автоматически перезапускался. Для этого используется директива Restart, которую надо добавить в секцию Service. Этот параметр может иметь такие значения:
- on-failure — только если произошла ошибка;
- on-success — только если процесс сервиса завершился без ошибок;
- on-abnormal — только если сервис не отвечает;
- always — перезапускать всегда, когда сервис был остановлен;
Например, рассмотрим настройку автоматического перезапуска сервиса Apache:
sudo systemctl edit apache2 [Service]
Restart=on-failure
RestartSec=5s
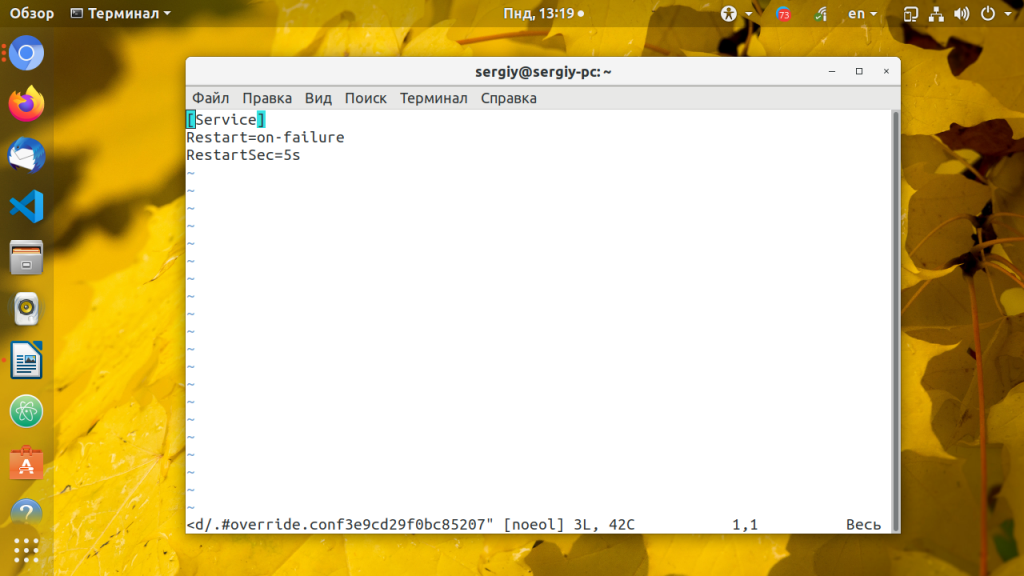
Директива RestartSec указывает сколько ждать перед перезапуском сервиса. Когда завершите сохраните изменения и выполните команду daemon-reload, чтобы перечитать конфигурацию:
sudo systemctl daemon-reload
Затем чтобы проверить что всё работает посмотрите состояние процесса, завершите процесс сигналом kill:
sudo systemctl status apache2 kill -KILL 32091
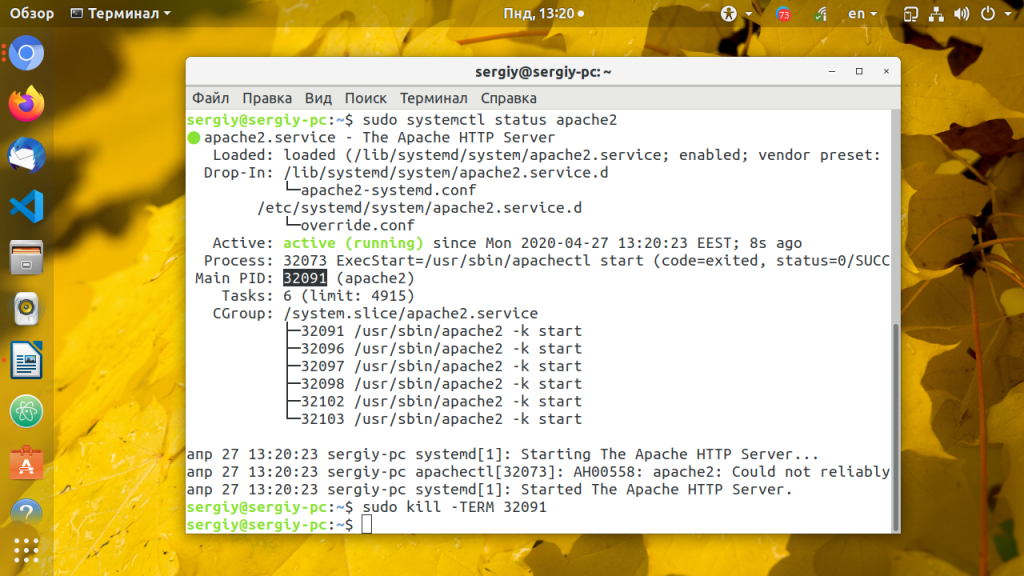
И снова посмотрите состояние. Процесс будет запущен. Система инициализации автоматически перезапустит его как только он завершится с кодом возврата ошибки. Если вы хотите чтобы процесс перезапускался всегда, необходимо использовать директиву Restart: always. Однако с ней надо быть осторожным, она вовсе не даст вам завершить процесс, даже если будет необходимо. Для того, чтобы процесс, который постоянно падает не перезапускался, можно добавить лимит на количество перезапусков в секцию Service:
sudo systemctl edit apache2 [Service]
StartLimitIntervalSec=500
StartLimitBurst=5
Restart=on-failure
RestartSec=5s
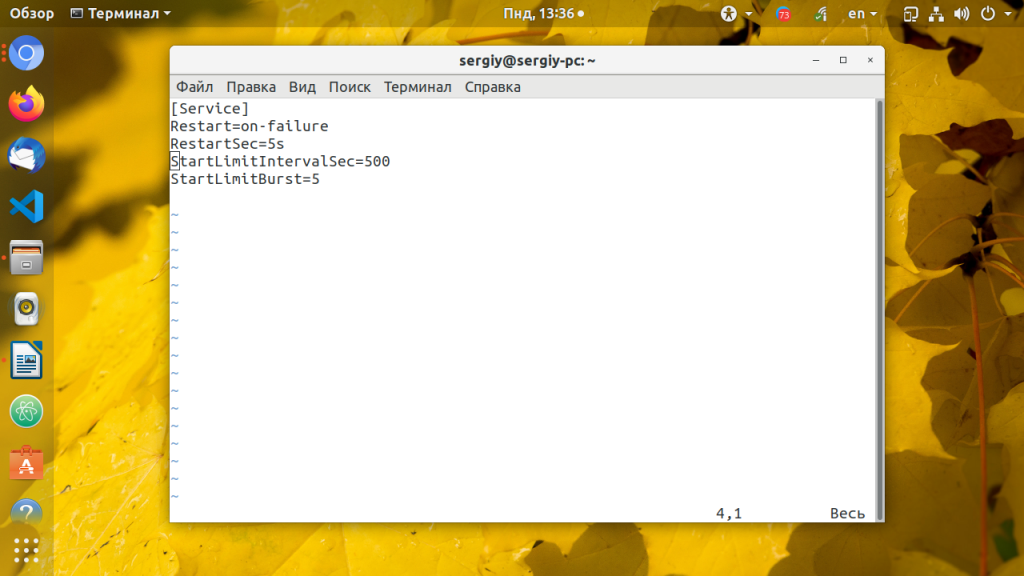
Директивы StartLimitBurst и StartLimitIntervalSec указывают, что надо попытаться перезапустить сервис пять раз, и если он все эти пять раз упадёт, то больше его не трогать. Вторая директива ограничивает время перезапусков сервиса до 500 секунд.
Автоматический перезапуск сервиса с помощью скрипта
Это самый простой и самый надежный способ работающий абсолютно во всех дистрибутивах Linux и не требующий установки дополнительных утилит. Для того же Apache скрипт выглядит следующим образом:
sudo vi /usr/local/bin/apache-monitor.sh #!/bin/bash
ps -A | grep apache2 || systemctl start apache2
Сохраните файл, сделайте его исполняемым:
chmod ugo+x /usr/local/bin/apache-monitor.sh
Теперь добавьте запись в cron для периодического запуска скрипта:
На этом все, автоматический перезапуск сервисов штука может и немного сложная, но необходимая в серьезных системах.
Обнаружили ошибку в тексте? Сообщите мне об этом. Выделите текст с ошибкой и нажмите Ctrl+Enter.
How to automatically restart a service on failure in Linux
On Windows, you can set what should happen if/when a service fails. Is there a standard way of achieving the same thing on Linux (CentOS in particular)? A bigger part of my question is: how do you handle sockets that have been left open — for example in TIME_WAIT, FIN_WAIT1, etc states. At the moment if the service I am developing crashes, I have to wait for the sockets to clear or change the listen port before I can then manually restart it. Thanks for your help.
4 Answers 4
monit is a great way to monitor and restart services when they fail—and you’ll probably end up using this for other essential services (such as Apache). There’s a nice article on nixCraft detailing how to use this for services specifically, although monit itself has many more functions beyond this.
As for the socket aspect, @galraen answered this spot on.
It’s a shame I have to decide which is the answer. I should have asked two seperate questions. @gelraen your answer just ended my weeks of searching for a solution. Thanks you so much! @Redmumba thanks, Monit does look good!
Whichever one you decide to mark correct, definitely upvote @gelraen’s answer. Its spot on correct, and very informative.
Only answering the service restart part. I came across Monit as well, but on CentOS 7 systemd takes care of all that for you. You just need to add these two lines to the .service file (if they’re not there already):
Restart=always RestartSec=3 Run man systemd.service for reference.
If you want to create a custom systemd service, it’s pretty straightforward to write your own service file. See the example below, for a custom http server.
Start the editor with a new service file:
vim /etc/systemd/system/httpd.service And add the following content, which you can edit as required:
[Unit] Description=My httpd Service After=network.target [Service] Type=simple User=root Environment=PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin Environment=PERLLIB=/perl ExecStart=/bin/httpd /etc/httpd.conf Restart=always RestartSec=3 [Install] WantedBy=multi-user.target I want it to start automatically on boot:
Tell systemd about the changes and start the service:
systemctl daemon-reload systemctl start httpd And now you can see the status:
There are many options for Restart . The following is an excerpt from the man page:
Restart=
Configures whether the service shall be restarted when the service process exits, is killed, or a timeout is reached.
Takes one of no, on-success, on-failure, on-abnormal, on-watchdog, on-abort, or always. If set to no (the default), the service will not be restarted. If set to on-success, it will be restarted only when the service process exits cleanly. In this context, a clean exit means any of the following:
• exit code of 0;
• for types other than Type=oneshot, one of the signals SIGHUP, SIGINT, SIGTERM, or SIGPIPE;
• exit statuses and signals specified in SuccessExitStatus=.
If set to on-failure, the service will be restarted when the process exits with a non-zero exit code, is terminated by a signal (including on core dump, but excluding the aforementioned four signals), when an operation (such as service reload) times out, and when the configured watchdog timeout is triggered.
The restart can be tested by sending an appropriate signal to the application. See the manual at man kill for details.