- Split files using tar, gz, zip, or bzip2 [closed]
- 4 Answers 4
- How to Split Large Text File into Multiple *.txt Files
- Problem Statement
- Using the Linux split Command
- Splitting File by Specifying Number of Lines
- Splitting File by Specifying Resulting File Sizes
- Splitting File by Specifying a Prefix
- Splitting File by Using Numeric Prefix
- Как разделить большой файл на части
- Как разделить файл на части
- Как объединить файлы в один
- Как разбить текстовый файл по строкам
- Заключение
- How to split a large file?
Split files using tar, gz, zip, or bzip2 [closed]
I need to compress a large file of about 17-20 GB. I need to split it into several files of around 1GB per file. I searched for a solution via Google and found ways using split and cat commands. But they did not work for large files at all. Also, they won’t work in Windows; I need to extract it on a Windows machine.
Many compression programs (e.g. like 7-Zip) is able to split the compressed file into volumes of a specified size for easier distribution.
If one of the two viable solutions posted here doesn’t pan out, he’ll be needing a programming solution.
4 Answers 4
You can use the split command with the -b option:
It can be reassembled on a Windows machine using @Joshua’s answer.
copy /b file1 + file2 + file3 + file4 filetogether Edit: As @Charlie stated in the comment below, you might want to set a prefix explicitly because it will use x otherwise, which can be confusing.
split -b 1024m "file.tar.gz" "file.tar.gz.part-" // Creates files: file.tar.gz.part-aa, file.tar.gz.part-ab, file.tar.gz.part-ac, . Edit: Editing the post because question is closed and the most effective solution is very close to the content of this answer:
# create archives $ tar cz my_large_file_1 my_large_file_2 | split -b 1024MiB - myfiles_split.tgz_ # uncompress $ cat myfiles_split.tgz_* | tar xz This solution avoids the need to use an intermediate large file when (de)compressing. Use the tar -C option to use a different directory for the resulting files. btw if the archive consists from only a single file, tar could be avoided and only gzip used:
# create archives $ gzip -c my_large_file | split -b 1024MiB - myfile_split.gz_ # uncompress $ cat myfile_split.gz_* | gunzip -c > my_large_file For windows you can download ported versions of the same commands or use cygwin.
How to Split Large Text File into Multiple *.txt Files
As we have mentioned numerous times in the earlier article covered; whether directly or indirectly, it remains a valid statement that the computing depth of a Linux operating system cannot be matched with the strides of other operating systems.
Its open-source nature creates an unseen level of transparency for the end-users. While other operating systems provide the start button for baking a cake, Linux allows us to play with the cake ingredients as we move towards the final product.
This article will seek to explore the visible Linux-oriented steps for splitting a large text file into multiple smaller text files. This tutorial falls under the Linux file management segment.
One of the reasons why you might need to break a large text file into a smaller file is to meet set memory requirements. The large file might not fully fit in a removable media but splitting it makes it easy to transfer in bits.
Problem Statement
We will create a sample text file called large_file.txt to reference throughout this tutorial.
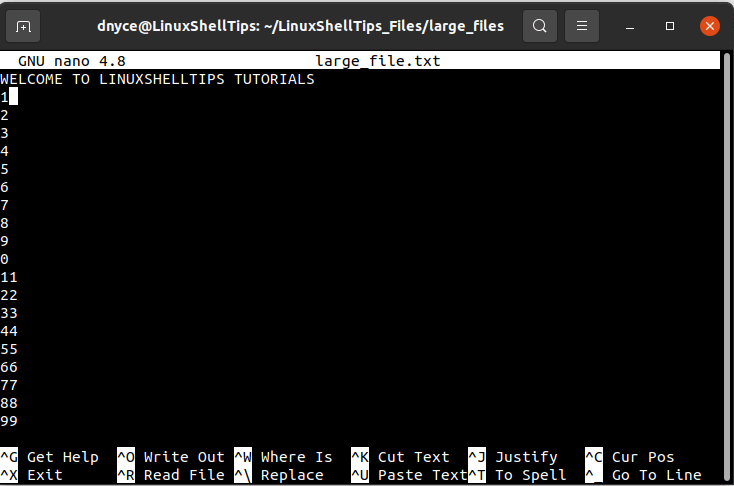
We are going to look at several useful Linux-based methodologies that will help us break the above large text file into multiple small text files. Smaller file transfers over a network are usually faster hence speeding up the network performance due to parallel transfers.
Using the Linux split Command
The split command is part of the GNU Coreutils package and primarily splits an input file into multiple smaller files.
The syntax for the usage of the split command is as follows:
The split utility is associated with several useful command options as per its man page ($ man split) . The default size of the file to split is 1000 lines. The split file takes a default suffix (x) and a default prefix (aa).
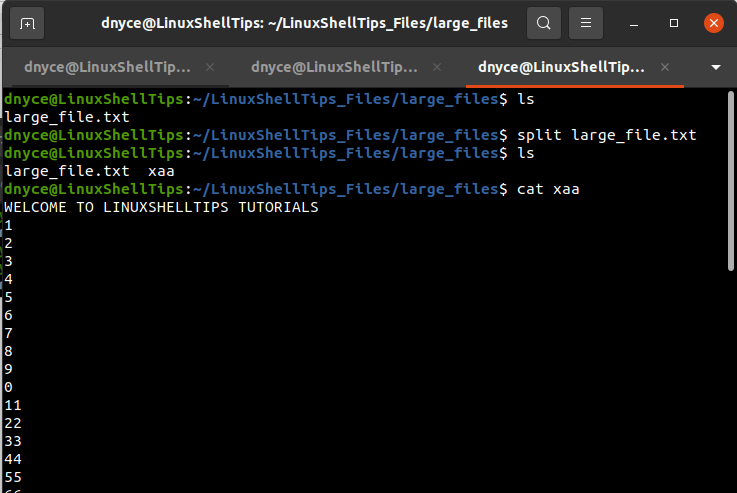
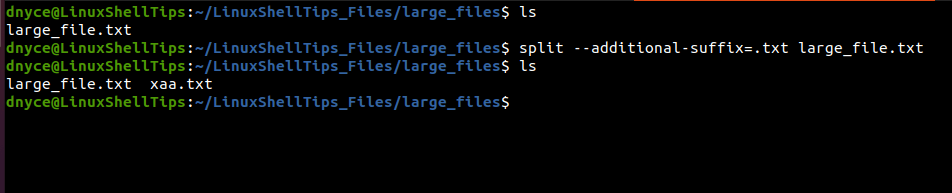
We only see one file split because the original text file has less than 1000 lines i.e. 49 lines, hence we logically created its duplicate.
To retain the .txt file extension after file splitting, we will use the command option —additional-suffix .
$ split --additional-suffix=.txt large_file.txt
Splitting File by Specifying Number of Lines
Let’s say we want to split this large text file into smaller ones with 12 lines each, we will use the -l command option to specify the line number split we want.
$ split -l 12 --additional-suffix=.txt large_file.txt
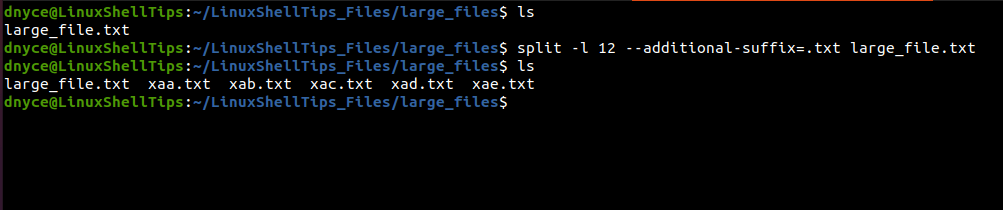
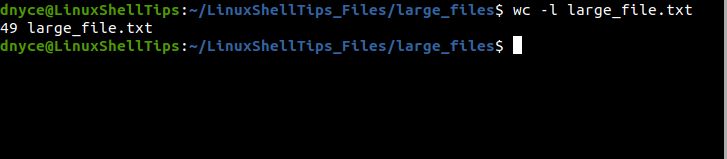
The 49 lined large_file.txt has been split into 5 smaller files each with a maximum of 12 lines.
$ cat xaa.txt | wc -l; cat xab.txt | wc -l; cat xac.txt | wc -l; cat xad.txt | wc -l; cat xae.txt | wc -l

Splitting File by Specifying Resulting File Sizes
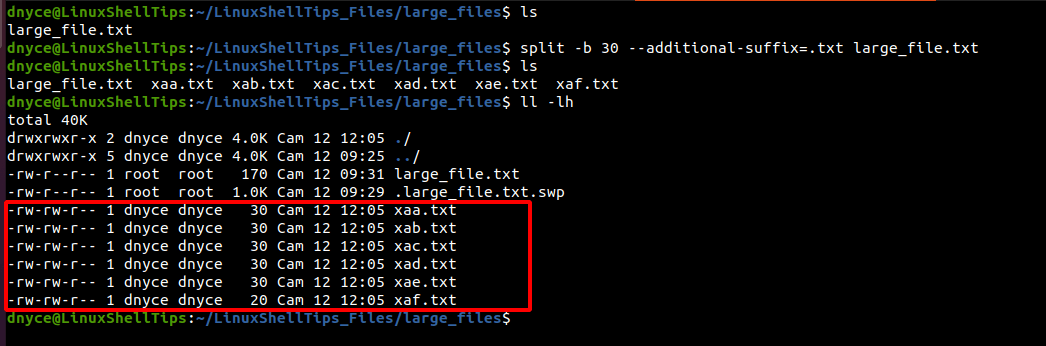
Our file has a file size of 170 bytes.

To split it into 30 bytes smaller files, we will use the -b command option.
$ split -b 30 --additional-suffix=.txt large_file.txt
The command has generated 6 smaller files with a maximum file size of 30 bytes each.
Splitting File by Specifying a Prefix
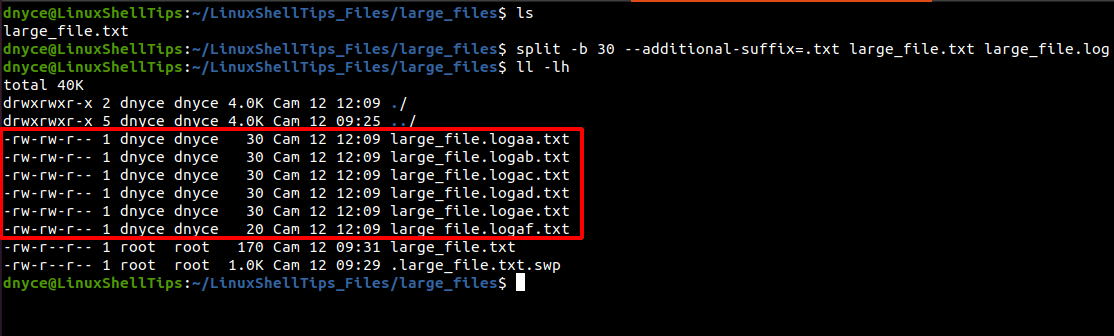
Let us for instance assume we need the 30 bytes split files above to have the prefix large_file.log, we would implement the following command.
$ split -b 30 --additional-suffix=.txt large_file.txt large_file.log
Splitting File by Using Numeric Prefix
If you want the split files prefixes to be associated with numeric numbers like 00, 01, or 02 and not letters like aa, ab, or ac, implement the command with the -d command option.
$ split -d -b 30 --additional-suffix=.txt large_file.txt large_file_log
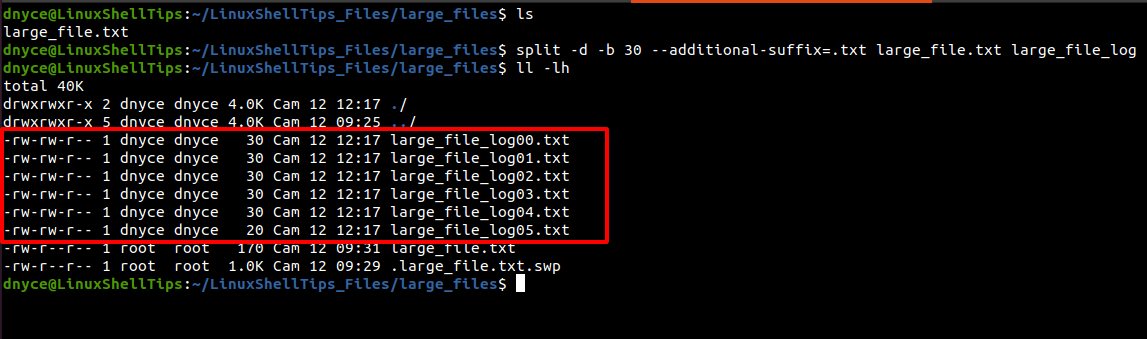
We can now comfortably split a large text file into multiple smaller files while retaining the .txt file extension in Linux.
Как разделить большой файл на части
Иногда может потребоваться разделить большой файл на несколько маленьких частей. Например, если файл настолько большой, что не может быть записан на внешний диск или флешку, так как файловая система не поддерживает файлы такого размера.
Для того, чтобы разделить большой файл на несколько частей можно воспользоваться командой split .
После выполнения команды split , мы получим несколько файлов меньшего размера. Если их объединить, то снова получим исходный большой файл. Объединение файлов выполняется командой cat .
Рассмотрим, как разбить файл на несколько частей и как потом объединить файлы, чтобы получить исходный файл.
Как разделить файл на части
Используем команду split , чтобы разделить файл на несколько более маленьких:
split --bytes=1024M file.mkv file.part.- file.mkv — имя исходного большого файла, который необходимо разбить на части.
- file.part. — префикс (название) имен файлов, на которые будет разбит исходный файл. То есть в нашем случае мы разобьём исходный файл на файлы file.part.aa , file.part.ab , file.part.ac , .
- —bytes=1024M — задает размер файлов, на которые разбивается исходный файл. В данном случае мы разбиваем исходный большой файл на файлы размером 1024 мегабайта. Для задания размера можно использовать символы:
- K или k — килобайты
- M или m — мегабайты
- G или g — гигабайты
Как объединить файлы в один

После того, как мы разбили файл на части, их можно объединить, чтобы получить исходный файл. Для этого используем команду:
- file.part.* — маска имени файлов кусочков, которые мы объединяем.
- file.mkv — название (путь) до файла, в который мы объединяем наши файлы-кусочки.
Как разбить текстовый файл по строкам
Если вам нужно разделить текстовый файл, на несколько файлов по количеству строк, то мы можем использовать команду split с опцией -l , которая задает количество строк в каждом файле, на которые мы разбиваем исходный файл.
split -l 1000 textfile.txt textfile.part.Мы разделили исходный текстовый файл, на файлы по 1000 строк в каждом. Объединение файлов выполняется также, как описано в предыдущем параграфе.
Заключение
Мы рассмотрели простейшие способы разделения файла на несколько частей с использованием командной строки.
Для разделения файлов используется команда split . Для объединения файлов мы использовали команду cat .
Чтобы получить более подробную информацию по команде split , выполните в терминале:
Описанный выше способ можно использовать как в Linux, так и в MacOS.
How to split a large file?
In order to be sure no line break you can use other option than c .
split a file by #number chunks so you can thus be sure they are equal and more no break in lines.Example
This will split the file.txt into 4 chunks.
OR you can split by number of lines
This will split the file.txt into files each is 200 lines. But this is not accurate that all are of same length since the last file maybe less than that number chosen.
Now with respect to the naming. The default of the command split is to use a default suffix «x» and default prefixes «aa» «ab» «ac» .
So in order to change those default you have to state a suffix to use.
split -n #number file1_1.txt file1_1.The output would be like file1_1.aa file1_1.ab file1_1.ac
Else you can change the default prefix to be numberic using -d
split -n #number -d file1_1.txt file1_1.The output would be like file1_1.00 file1_1.01 file1_1.02
So you can’t get the naming you want with default split unless you use some awk or sed with REGEX.
Now to read the set of files from a file lets called files.list
while IFS= read -r file do split -n #number -d "$file" "$file" done < files.listAccording to second answer
recent versions (≥ 8.16) of gnu split one can use the --additional-suffix switch to have control over the resulting extension. From man split:
--additional-suffix=SUFFIX append an additional SUFFIX to file names. so when using that option:
split -dl 10000 --additional-suffix=.txt words wrd the resulting pieces will automatically end in .txt:
wrd00.txt wrd01.txt
So in your case if your split version is >8.16 then you can do your need like this
split -n #number -d --additional-suffix=.txt file1_1.txt file1_1-file1_1-00.txt file1_1-01.txt file1_1-02.txt .