- Split the content of a file in linux
- 5 Answers 5
- Linux split Command with Examples
- Linux split Command Syntax
- Linux split Command Options
- Linux split Command Examples
- Split Files
- Use the Verbose Option
- Set Number of Lines per File
- Choose File Size
- Specify Maximum Size
- Set Number of Output Files
- Split a File at the End of a Line
- Show Only a Specified Output File
- Set Suffix Length
- Change Suffix
- Change Prefix
- Omit Files with Zero Size
- Reconnect Split Files
- How can I split a text file into multiple text files?
Split the content of a file in linux
Say for example I have this content in a file named abc.txt and I want to split the content and write the first two entries into a new file. (e.g), the new file would look like this:
In such case my awk goes (I think): awk -F»\x00″ ‘
5 Answers 5
awk -F"@" '' abc.txt > newfile.txt Copying my own comment: In such case my awk goes (I think): awk -F»\x00″ ‘
What are you trying to match with (.*)(.*) ? Also why use cat ? You can do sed -r ‘pattern_here’ file directly. Finally, this code seems to assume that the input file only has 3 file names of which you extract the first one only.
.* should match on anything, the idea is to split the contents of the file using @ as a delimiter. And why not use cat —it’s just as viable a method as any other.
My point is, (.*)(.*) will not yield any different result from (.*) why did you repeat it? As for why not use cat , it’s not about functionality, it’s about tacking on unneeded complexity. This is not what cat was made for anyway.
I think that I may have forgotten to try the above without the extra (.*) and so that may be why there’s an extra one. If you wish, feel free to edit the above.
I’m guessing this question is related to that one, correct?
In that case, wouldn’t replacing the ‘^@’ with a newline be more worth your while? In the following, I’m guessing you mean ‘^@’, the ASCII NUL byte:
$ sed 's/\o000/\n/g' abc.txt | head -n 2 abc.tar xxx.tar sed 's/\o000/\n/g' abc.txt | head -n 2 > newfile.txt Explanation
This substitutes a newline ( \n ) for every NUL byte ( \o000 ) the \o part means that what follows is a byte in octal notation. The output is then piped to head -n 2 which extracts the first two lines; and the resulting lines are redirected ( > ) to the file newfile.txt .
If it’s important to you that the file names be separated by ‘^@’, however, you can use this:
perl -nl000 -e ' $num_lines =2 ; push @a,(split /\000/)[0..$num_lines-1]; print $_ for @a' abc.txt > newfile.txt Replace the value of $num_lines above as needed to grab the first $num_lines lines from the file.
Explanation
- The -n switch tells perl to run the code on each line of the input file
- The -l000 sequence tells perl to set the output record separator (the character printed after every string) to the NUL byte ( 000 ).
- The -e switch tells perl that the string that follows is a code to execute.
- The split function splits each input line with the NUL byte as delimiter,takes the first $num_lines ( [0..$num_lines-1] ) results and puts them into the array @a . Notice that the «current input line» part is nowhere specified in the function call. This makes use of the fact that the default scalar variable in Perl ( $_ ) is the default argument of the split function (among others) when no argument is supplied.
- The final foreach loop prints every element in @a (again note how $_ is the default iterator for the foreach loop). Since we have set the output record separator to octal 000 , we get the results separated by the NUL byte as before.
Linux split Command with Examples
The Linux split command breaks files into smaller parts and is used for analyzing large text files with many lines. While each split file counts 1000 lines by default, the size is changeable.
In this guide, learn how to use the Linux split command with examples.

- Access to the terminal line.
- A large text file (this tutorial uses large_text, small_text, and tiny_text files).
Linux split Command Syntax
The basic split syntax is:
split [options] [file] [prefix]The split command cannot be run without including the target file. Stating the prefix is optional. If no prefix is specified, split defaults to using x as the prefix, naming created files as follows: xaa, xab, xac, etc.
Linux split Command Options
The split command supports many options. The most common split command options are:
| Option | Description |
|---|---|
| -a | Set suffix length. |
| -b | Determines size per output file. |
| -C | Determines the maximum size per output file. |
| -d | Changes default suffixes to numeric values. |
| -e | Omits creating empty output files. |
| -l | Creates files with a specific number of output lines. |
| -n | Generates a specific number of output files. |
| —verbose | Displays a detailed output. |
Linux split Command Examples
The split command enables users to divide and work with large files in Linux. The command is often used in practice, and 13 common use cases are explained below.
Split Files
The basic usage of split is to divide big files into smaller 1000-line chunks. For instance, split the large_text file and verify the output with ls:

The ls command shows 13 new files, ranging from xaa to xam. Check the line count for each file using wc with the -l flag:
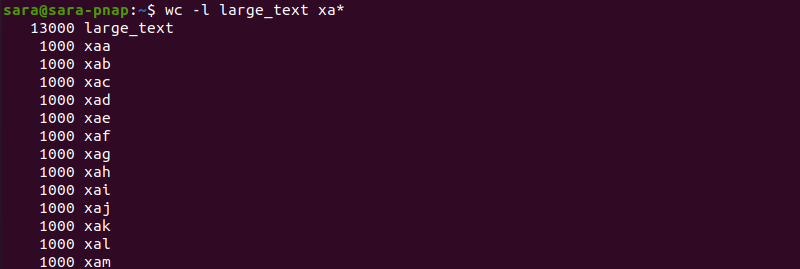
The target file, large_text, is 13000 lines long. The split command makes 13 files containing 1000 lines each. If the target file’s line count is not divisible by 1000, split counts 1000 lines per file except for the last one. The last file has fewer lines.
For instance, a file smaller_text in smaller_directory has 12934 lines:

Split smaller_text and use ls to confirm the outcome:

Once the target file is split, run wc -l again:
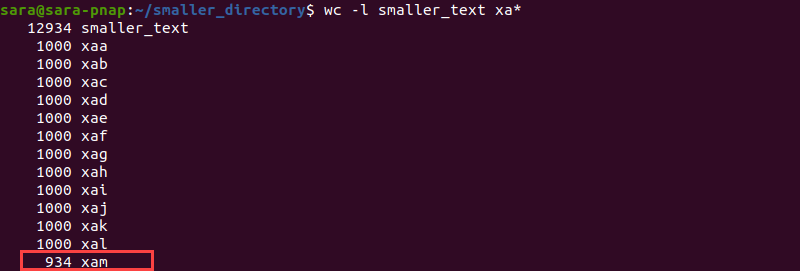
The output shows that the last file has 934 lines, as opposed to the other 12, which have 1000 lines each.
Use the Verbose Option
The split command does not print any output. Use —verbose to track how split works. Running split with —verbose shows more details:
split large_ text --verbose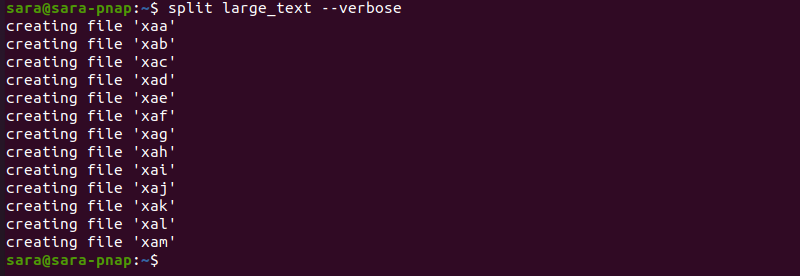
Set Number of Lines per File
To bypass the default 1000-line rule, use the -l flag with split . The split -l command enables users to set the number of lines per file.
For instance, run split -l2500 to create files containing 2500 lines each and check the line count with wc :
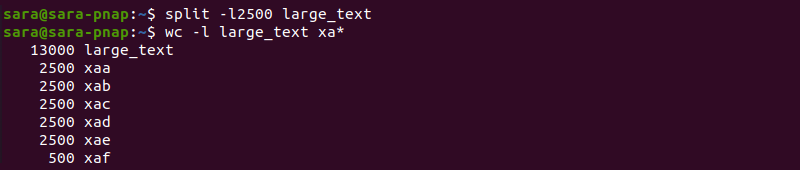
The command creates six new files. Files xaa to xae have 2500 lines each, while file xaf has 500 lines, totaling 13000.
The split -l command can also make files with fewer lines than 1000. For example, the tiny_text file has 2693 lines:

Split the text into 500-line files with:
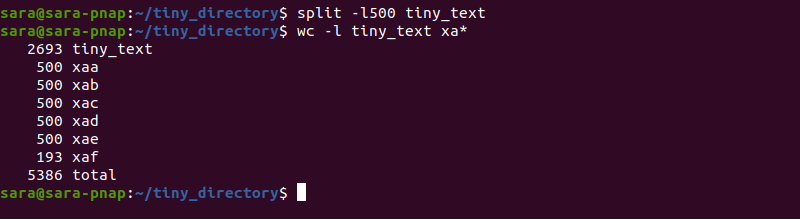
The command prints five 500-line files and one 193-line file.
Choose File Size
Split files based on their size with split -b . The command creates files based on the number ( n ) of:
For instance, create 1500Kb files from large_text with:
split -b1500K large_text --verbose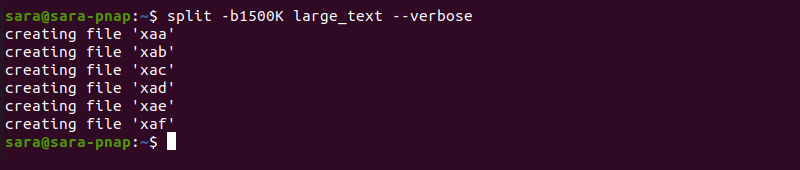
The —verbose option shows that split -bnK created six files. To check file size, use wc -c :
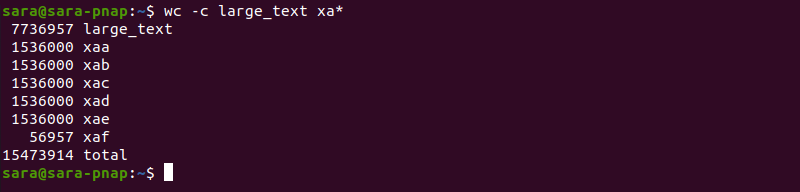
The output shows that five files are 1 536 000 bytes each, and the sixth is 56 957 bytes long.
Specify Maximum Size
Use -C to set a maximum size per output file. For instance, split large_text and set the output size to 2MB with:
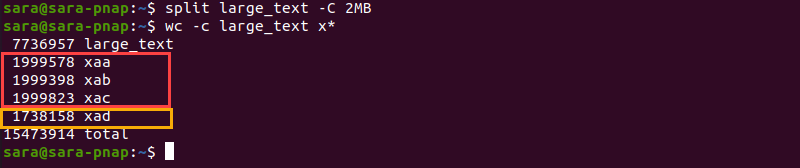
The wc -c command shows that split created four new files and that the first three are roughly 2 MB, while the fourth one is smaller.
Set Number of Output Files
Use -n with split to determine the number of output files. For example, split large_text into ten parts with:

Split a File at the End of a Line
Another -n usage is splitting a file at the end of a complete line. To do this, combine -n with l . For instance, split the file large_text into ten files while ending with a complete line with:

The ls command shows ten newly created files. Run cat on any file to verify the file ends on a complete line:

Show Only a Specified Output File
The split command, by default, creates as many files as necessary to cover the entire source file. However, using -n with split does split a file, but only displays the specified part(s). The flag also doesn’t create output files but prints the output to the terminal.
For instance, split tiny_text into 100 parts but only display the first one with:

The command prints the first split file to the standard output without creating any new files.
Set Suffix Length
The split command creates files with a default suffix of two letters. Change the length by adding the -a flag to split. For instance, to make the suffix 3-characters long, type:

Change Suffix
Use split to create files with different suffixes. For instance, split large_text into 2500-line files with numeric suffixes:

The output shows six files with numbered suffixes created with the -d flag. The -l2500 flag splits the large_text file into six 2500-line files.
Change Prefix
The split command also creates output files with customizable prefixes. The syntax for the command is:
For instance, split large_text into ten files called part00 to part09 with:
split -d large_text part -n 10
The prefix changes from x to part and ends with numbers due to the -d flag. The -n flag splits the file into ten parts.
Omit Files with Zero Size
When splitting files, some output will return zero-size files. To prevent zero-size output files, use split with the -e flag. For instance, split the xaa file from the tiny_directory into 15 files, with a numeric suffix, assuring zero-size files are omitted:

Check file size with wc -c :
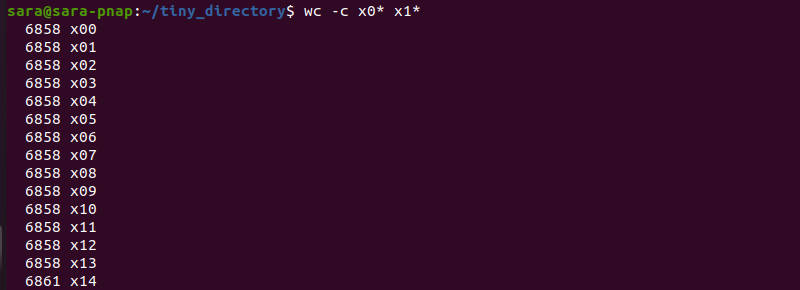
Using the x0* and x1* as search terms ensures wc -c prints the size of all files in the directory starting with numbers.
Reconnect Split Files
While split cannot rejoin files, there is an alternative option — the Linux cat command. Used to display the content of different files, cat also reconnects divided files into a new complete document.
For instance, large_text is split into ten files:

All the output files start with x. Apply cat to any items starting with x to merge them.
However, cat prints the result to the standard output. To merge the files into a new file, use > with the new file name:

Running wc -c shows that large_text and new_large_text are the same size.
After reading this article, you know how to use the Linux split command to work with large documents. Next, learn how to securely copy and transfer files using the SCP command.
How can I split a text file into multiple text files?
[ entry1 ] 1239 1240 1242 1391 1392 1394 1486 1487 1489 1600 1601 1603 1657 1658 1660 2075 2076 2078 2322 2323 2325 2740 2741 2743 3082 3083 3085 3291 3292 3294 3481 3482 3484 3633 3634 3636 3690 3691 3693 3766 3767 3769 4526 4527 4529 4583 4584 4586 4773 4774 4776 5153 5154 5156 5628 5629 5631 [ entry2 ] 1239 1240 1242 1391 1392 1394 1486 1487 1489 1600 1601 1603 1657 1658 1660 2075 2076 2078 2322 2323 2325 2740 2741 2743 3082 3083 3085 3291 3292 3294 3481 3482 3484 3690 3691 3693 3766 3767 3769 4526 4527 4529 4583 4584 4586 4773 4774 4776 5153 5154 5156 5628 5629 5631 [ entry3 ] 1239 1240 1242 1391 1392 1394 1486 1487 1489 1600 1601 1603 1657 1658 1660 2075 2076 2078 2322 2323 2325 2740 2741 2743 3082 3083 3085 3291 3292 3294 3481 3482 3484 3690 3691 3693 3766 3767 3769 4241 4242 4244 4526 4527 4529 4583 4584 4586 4773 4774 4776 5153 5154 5156 5495 5496 5498 5628 5629 5631 I would like to split it into three text files: entry1.txt , entry2.txt , entry3.txt . Their contents are as follows. entry1.txt:
[ entry1 ] 1239 1240 1242 1391 1392 1394 1486 1487 1489 1600 1601 1603 1657 1658 1660 2075 2076 2078 2322 2323 2325 2740 2741 2743 3082 3083 3085 3291 3292 3294 3481 3482 3484 3633 3634 3636 3690 3691 3693 3766 3767 3769 4526 4527 4529 4583 4584 4586 4773 4774 4776 5153 5154 5156 5628 5629 5631 [ entry2 ] 1239 1240 1242 1391 1392 1394 1486 1487 1489 1600 1601 1603 1657 1658 1660 2075 2076 2078 2322 2323 2325 2740 2741 2743 3082 3083 3085 3291 3292 3294 3481 3482 3484 3690 3691 3693 3766 3767 3769 4526 4527 4529 4583 4584 4586 4773 4774 4776 5153 5154 5156 5628 5629 5631 [ entry3 ] 1239 1240 1242 1391 1392 1394 1486 1487 1489 1600 1601 1603 1657 1658 1660 2075 2076 2078 2322 2323 2325 2740 2741 2743 3082 3083 3085 3291 3292 3294 3481 3482 3484 3690 3691 3693 3766 3767 3769 4241 4242 4244 4526 4527 4529 4583 4584 4586 4773 4774 4776 5153 5154 5156 5495 5496 5498 5628 5629 5631 In other words, the [ character indicates a new file should begin. The entries ( [ entry*] , where * is an integer) are always in numerical order and are consecutive integers starting from 1 to N (in my actual input file, N = 200001). Is there any way I can accomplish automatic text file splitting in bash? My actual input entry.txt actually contains 200,001 entries.