- Не выключается Linux
- Почему не выключается компьютер Linux?
- Как исправить ошибку «не выключается Linux»
- 1. Лог выключения в реальном времени
- 2. Лог выключения в journalctl
- 3. Настройка таймаутов в systemd
- Выводы
- «A stop job is running. » on shutdown [duplicate]
- 1 Answer 1
- Linked
- Related
- Hot Network Questions
- A stop job is running for Advanced key-value store (X / no limit)
- 2 Answers 2
- Interactively terminate «A stop job is running» at shutdown
Не выключается Linux
Сразу после установки, как правило, любая операционная система будет работать очень хорошо и быстро. Но со временем ошибки могут накапливаться и вызывать различные проблемы с использованием ОС.
В сегодняшней статье мы рассмотрим такую ошибку, как «не выключается Linux». Разберём, почему может возникнуть такая проблема, методы её отладки и исправления.
Почему не выключается компьютер Linux?
Инициализацией и завершением работы сервисов в системе Linux занимается system, и если компьютер не может выключиться, это означает, что systemd не может справиться с каким-либо процессом и ждёт его завершения. По умолчанию система даёт каждому сервису одну минуту и тридцать секунд, а затем отправляет сигнал экстренного завершения. Но таких сервисов может быть несколько, и завершение работы Linux может затянуться.
Есть несколько путей решения этой проблемы:
- Во первых, нам необходимо понять в чём именно проблема, какой сервис её вызывает и попытаться её решить;
- Во вторых, мы можем уменьшить время ожидания от 90 до пяти секунд, для большинства сервисов этого будет вполне достаточно.
А теперь давайте рассмотрим пути решения проблемы.
Как исправить ошибку «не выключается Linux»
Чтобы понять, почему система не может выключиться, нам сначала необходимо посмотреть лог её выключения. И тут у нас тоже есть два пути: либо отключить заставку и выводить лог в реальном времени, либо записывать лог выключения с помощью journalctl.
1. Лог выключения в реальном времени
Первый способ не настолько информативный, но всё же может быть полезным. Для отключения заставки откройте /etc/default/grub и в строке GRUB_CMDLINE_LINUX_DEFAULT замените слова quiet splash на verbose:
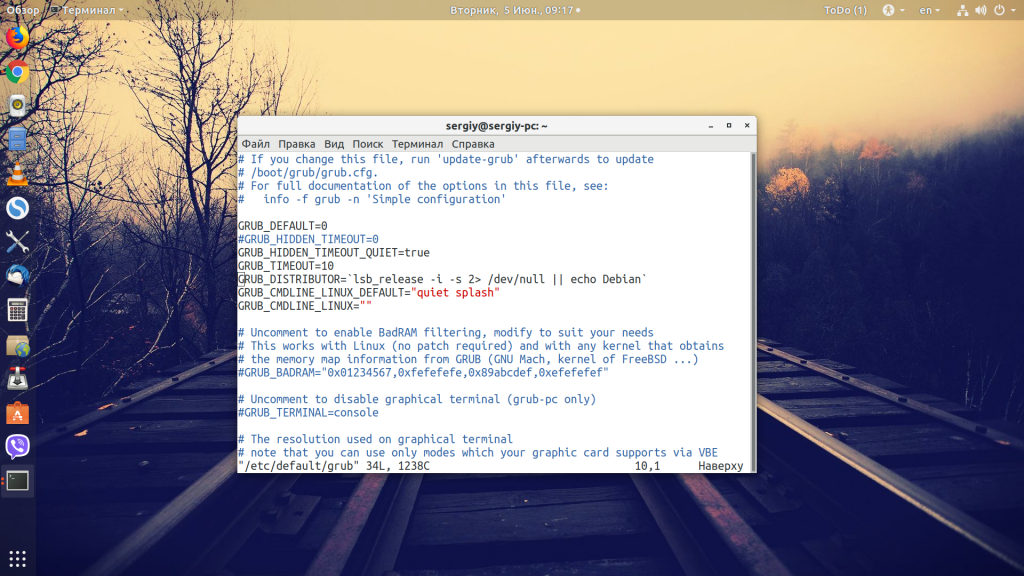
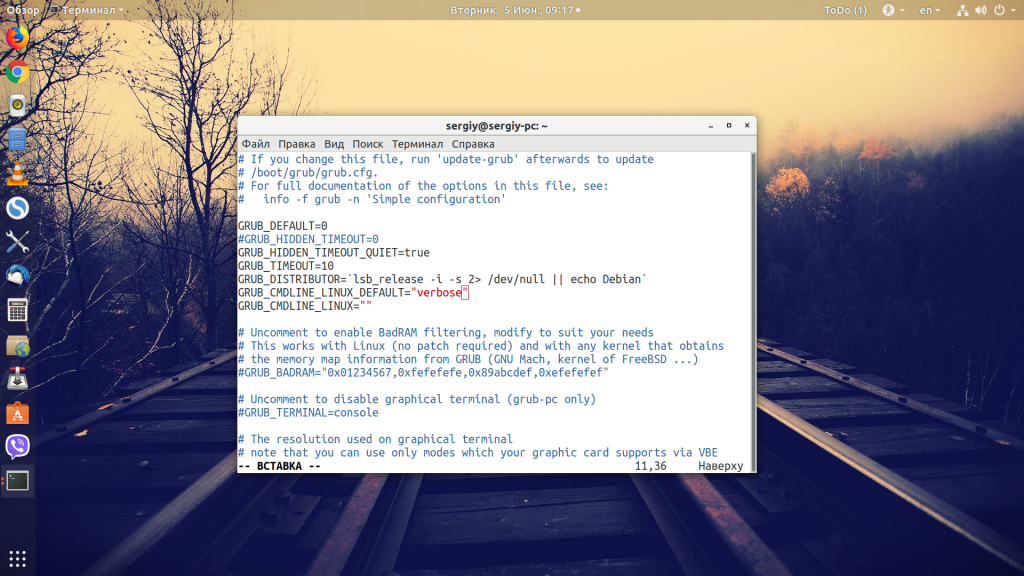
Затем перезагрузите компьютер. Сначала вы будете видеть полный лог загрузки, а при выключении вы увидите полный лог выключения. Преимущество этого пути в том, что вы увидите, на какой команде загрузка зависает, и сможете понять, куда копать дальше. Например, часто бывает, что Linux не может выключиться из-за ошибки «a stop job is running for Session c2 of user», т.е. мы не можем завершить сессию пользователя. Ещё выключению могут препятствовать примонтированные удалённые файловые системы.
2. Лог выключения в journalctl
Утилита journalctl занимается обработкой логов в Linux, но есть одна проблема: она записывает журналы только из текущей сессии, при перезагрузке всё стирается. Но это можно исправить. Для этого окройте конфигурационный файл /etc/systemd/journald.conf и замените в нём значение строки Storage=auto на Storage=persistent:
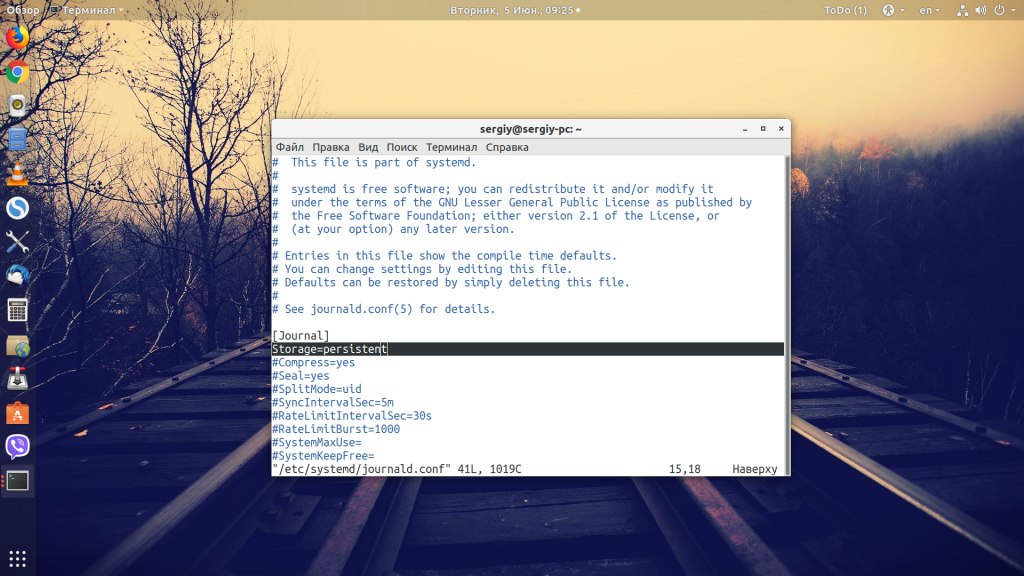
Затем два раза перезапустите компьютер. Первый раз мы перезапускаем, чтобы настройки логирования вступили в силу, а второй, чтобы собрать лог последнего выключения Linux. После того, как загрузка завершиться, вы можете посмотреть лог с помощью такой команды:
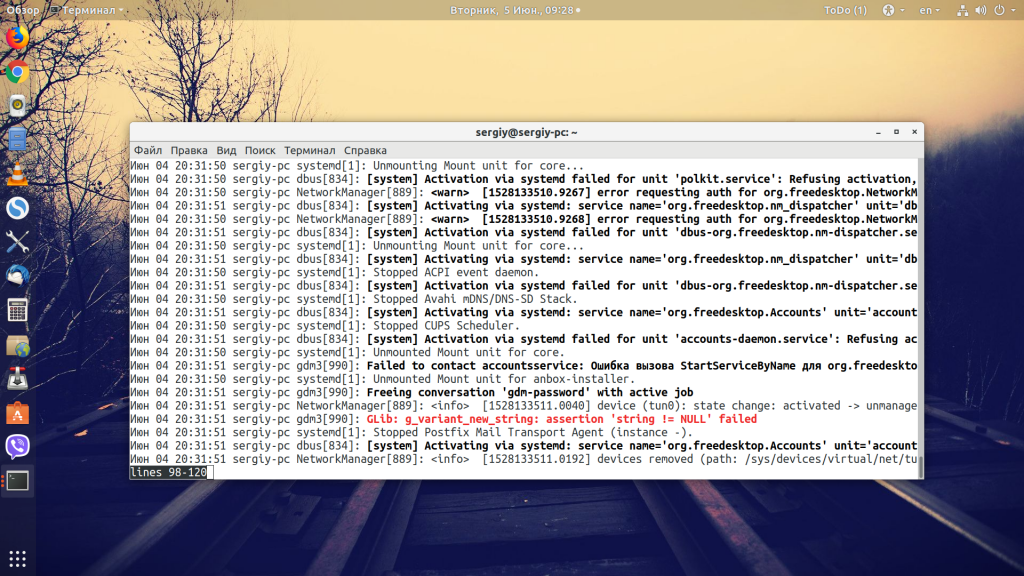
Опция —b позволяет вывести лог загрузки, -1 говорит, что нужно брать не текущую загрузку, а предыдущую, а —n300 отображает только последние 300 строк. Здесь вы можете видеть, что по таймауту была завершена именно сессия session-c1. Мы можем отфильтровать сообщения только по ней:
sudo journalctl -b -1 -u session-c1.scope
Если вы увидели ошибку и смогли её решить, то ваша система будет выключаться уже мгновенно, если же нет, то всё ещё есть несколько путей решения.
3. Настройка таймаутов в systemd
Если никакое из предыдущих решение не помогло, и в системе просто баг, который не позволяет ей адекватно выключиться, то вы всё ещё можете уменьшить время ожидания до того, как процессу будет отправлен сигнал экстренного завершения. Для этого откройте файл /etc/systemd/system.conf и добавьте туда такие строки:
sudo vi /etc/systemd/system.conf
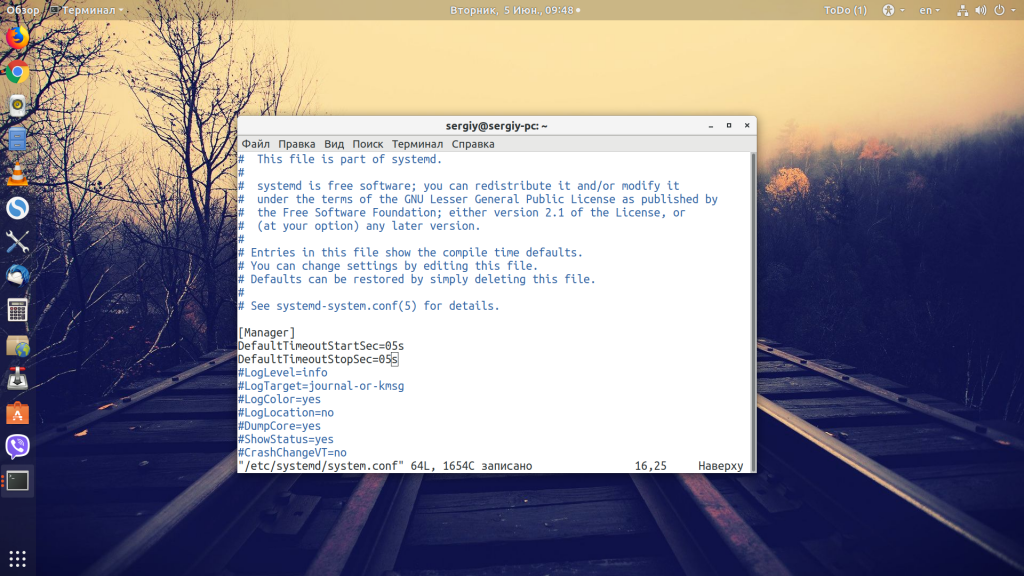
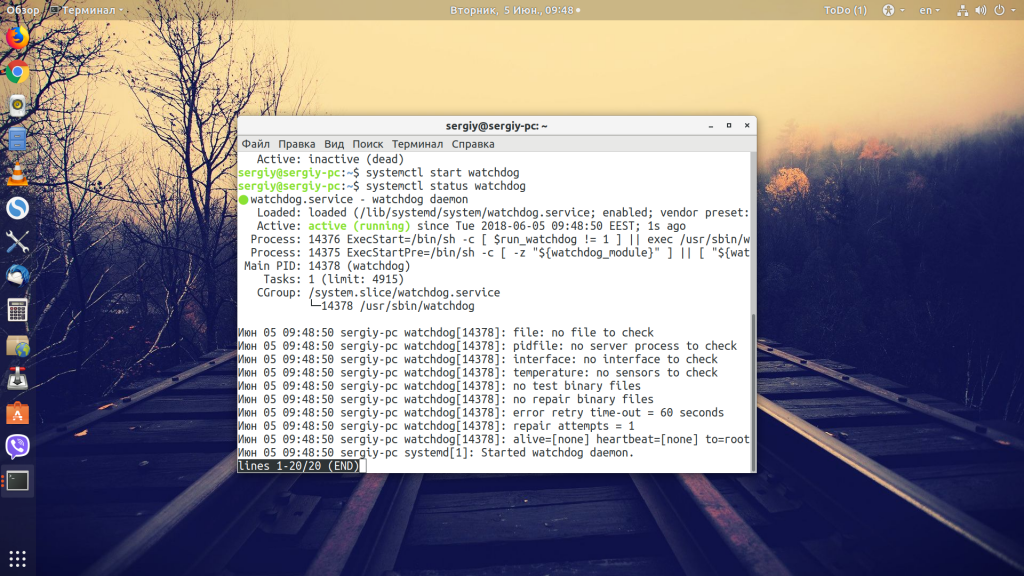
Теперь система будет ждать только 5 секунд перед тем, как завершить проблемный процесс. Также на некоторых форумах рекомендуют установить сервис watchdog, чтобы он следил за правильностью работы системного таймера. Это тоже делается очень просто:
sudo apt install watchdog
sudo systemctl enable watchdog
sudo systemctl start watchdog
Выводы
Может быть огромное количество причин, по которым ваша система не сможет включиться, и чтобы их найти и исправить, необходимо анализировать логи, искать по форумах и настраивать свою систему. Надеюсь, информация из этой статьи сделает вашу работу в Linux более комфортной.
Обнаружили ошибку в тексте? Сообщите мне об этом. Выделите текст с ошибкой и нажмите Ctrl+Enter.
«A stop job is running. » on shutdown [duplicate]
Almost every time when I’m shutting down or rebooting the system I get the following message before the system actually shuts down:
A stop job is running for Session 1 of user xy It waits for 1:30min and then continues with the shutdown. I’m using Debian stretch with Gnome 3. This message does not appear in the syslog. Any ideas?
The other question is more recent, but has more answers. It has the same answer below (literally copy-pasted) and another answer with more votes.
1 Answer 1
I had the same problem, searching I found a post in a reddit forum of Arch Linux.
Install watchdog
# pacman -S watchdog
And then start the service at boot:
# systemctl enable watchdog.service
Start the service to don’t see the message any more
# systemctl start watchdog.service
Linked
Related
Hot Network Questions
Site design / logo © 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA . rev 2023.7.13.43531
Linux is a registered trademark of Linus Torvalds. UNIX is a registered trademark of The Open Group.
This site is not affiliated with Linus Torvalds or The Open Group in any way.
By clicking “Accept all cookies”, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy.
A stop job is running for Advanced key-value store (X / no limit)
so after installing redis onto my ubuntu 20.04 server. Whenever I reboot. A stop job appears for Advanced key-value store. I believe this is part of redis but I don’t know why it keeps appearing and taking so long. How do I stop it
2 Answers 2
I had this issue too and the fix was pretty simple. You need to edit the redis service file defined by the command systemctl show -P FragmentPath redis.service :
$ systemctl show -P FragmentPath redis.service /lib/systemd/system/redis-server.service Look for the line that contains TimeoutStopSec and set it to the maximum value in seconds you want. I normally set it to 5 seconds.
After configuring the file, the line should look something like this
Now that’s it, you may want to run the command systemctl daemon-reload just to complement this.
You can then try rebooting or shutting down to confirm the change worked.
Bonus
If you want to set the maximum timeout for the entire system, you do so in the /etc/systemd/system.conf file.
Look for the line DefaultTimeoutStopSec and set it just as you did previously.
A couple of remarks: Systemd units normally reside inside /lib/systemd/system/ — I’m pretty sure any .service file inside /etc/systemd/system/ is a symlink that points to /lib/systemd/system/ . And another thing: It’s generally best to modify unit files by using drop-in configs. This means you should create the directory /etc/systemd/system/redis.service.d , and create a config file here (called redis.conf ). And inside this file you would add the line TimeoutStopSec=5s . This means your custom config will survive if the unit file gets updated.
redis.service links to redis-server.service in /lib/systemd/system/ . With /lib/ instead of /etc/ , folder should be /lib/systemd/system/redis-server.service.d/
check your /etc/redis/redis.log file for the reason why it cant restart.
For me, i had the following error:
1963:signal-handler (1670871763) Received SIGTERM scheduling shutdown. 1963:M 12 Dec 2022 14:02:43.145 # User requested shutdown. 1963:M 12 Dec 2022 14:02:43.145 * Saving the final RDB snapshot before exiting. 1963:M 12 Dec 2022 14:02:43.145 # Failed opening the temp RDB file temp- 1963.rdb (in server root dir /var/log) for saving: Read-only file system 1963:M 12 Dec 2022 14:02:43.145 # Error trying to save the DB, can't exit. 1963:M 12 Dec 2022 14:02:43.145 # Errors trying to shut down the server. Check the logs for more information.
To fix it i just ran the following to fix the problem.
sudo chown redis /var/log/redis/redis.log && sudo chmod u+x /var/log/redis/redis.log Interactively terminate «A stop job is running» at shutdown
Usually when I shut down my machine (with the shutdown command) it works pretty quickly, but every once in a while, usually after a borked update or when I break some service’s config file I end up with
A stop job is running for Some Broken Service (20min 58s / no limit)
parading across my screen until I give in and hold down the power button until the machine turns off. Sometimes there are multiple jobs, with one actually hung and the others waiting on the hung one, with a 1:30 timeout per job adding up to 20-30 minutes. Sometimes it will eventually turn off after a lot of waiting, sometimes it won’t (or I run out of patience). Is there anything I can do when I discover this to forcibly terminate whatever’s hung and allow it to continue shutting down (semi)-gracefully? Mainly, I want to make sure btrfs always has an opportunity to remount-ro and flush-to-disk because I’m running (semi-unstable) raid6. I’ve heard Ctrl+Alt+Delete should help, but all it seems to do is print ^[[3~ at the bottom of my screen — is there something I need to do to enable it? To be clear, I’m not trying to globally turn down or disable this timeout — my system is usually able to shut down without running in to it — I just want a way to bypass it interactively when I discover something’s wrong. Also, not interested in why this happens or how to solve it — diagnosing that has to wait until the machine finishes shutting down and starting back up. The most recent time I ran into this was by writing a udev rule that caused a kernel panic, causing systemd-udev to be permanently hung as far as I can tell. For some reason, that meant docker hung for 30 minutes until the shutdown itself timed out. It also seems to happen frequently when I have a systemd .mount unit pointing at a NFS share only accessibly over a VPN, when the VPN has died. Stopping the mount unit will then hang forever, causing for some reason my user session and 6-8 other units to hang for 1:30 each (in sequence) until they all time out. Also used to happen a while back every time I shut down for some inexplicable reason, then was fixed by a kernel upgrade (5.7.something fixed it, if I recall correctly).