- How to extract text with OCR from a PDF on Linux?
- 11 Answers 11
- How To Convert PDF To Text On Linux (GUI And Command Line)
- Convert PDF to text with pdftotext (command line)
- Pdftotext, convert a PDF to text from the terminal
- Install pdftotext on Ubuntu
- How to use pdftotext
- Convert a PDF file to text
- Convert only a range of PDF pages to text
- Use end-of-line characters
- Help
- Convert PDF files from a folder using a Bash FOR loop
- A comment, leave yours
- Leave a Comment Cancel reply
- How to extract text from pdf in script on Linux?
- 3 Answers 3
How to extract text with OCR from a PDF on Linux?
How do I extract text from a PDF that wasn’t built with an index? It’s all text, but I can’t search or select anything. I’m running Kubuntu, and Okular doesn’t have this feature.
11 Answers 11
I have had success with the BSD-licensed Linux port of Cuneiform OCR system.
No binary packages seem to be available, so you need to build it from source. Be sure to have the ImageMagick C++ libraries installed to have support for essentially any input image format (otherwise it will only accept BMP).
While it appears to be essentially undocumented apart from a brief README file, I’ve found the OCR results quite good. The nice thing about it is that it can output position information for the OCR text in hOCR format, so that it becomes possible to put the text back in in the correct position in a hidden layer of a PDF file. This way you can create «searchable» PDFs from which you can copy text.
I have used hocr2pdf to recreate PDFs out of the original image-only PDFs and OCR results. Sadly, the program does not appear to support creating multi-page PDFs, so you might have to create a script to handle them:
#!/bin/bash # Run OCR on a multi-page PDF file and create a new pdf with the # extracted text in hidden layer. Requires cuneiform, hocr2pdf, gs. # Usage: ./dwim.sh input.pdf output.pdf set -e input="$1" output="$2" tmpdir="$(mktemp -d)" # extract images of the pages (note: resolution hard-coded) gs -SDEVICE=tiffg4 -r300x300 -sOutputFile="$tmpdir/page-%04d.tiff" -dNOPAUSE -dBATCH -- "$input" # OCR each page individually and convert into PDF for page in "$tmpdir"/page-*.tiff do base="$" cuneiform -f hocr -o "$base.html" "$page" hocr2pdf -i "$page" -o "$base.pdf" < "$base.html" done # combine the pages into one PDF gs -q -dNOPAUSE -dBATCH -sDEVICE=pdfwrite -sOutputFile="$output" "$tmpdir"/page-*.pdf rm -rf -- "$tmpdir" Please note that the above script is very rudimentary. For example, it does not retain any PDF metadata.
How To Convert PDF To Text On Linux (GUI And Command Line)

Calibre is a free and open source e-book software suite. It supports organizing, displaying, editing, and converting e-books, supporting a wide range of formats. The application runs on Linux, macOS, and Microsoft Windows.
Calibre should be available in your Linux distribution's repositories, and you should be able to install it using whatever software store you have on your system. For example, to install it on Debian, Ubuntu, Linux Mint, Fedora, openSUSE, or Arch Linux, use:
sudo zypper install calibreCalibre may also be installed on Linux by using the Flathub package (requires setting up Flathub / Flatpak on some Linux distributions).
There's yet another way to install Calibre on Linux explained on the application's downloads page, where you'll also find macOS and Windows binaries.
Now that Calibre is installed on your system, launch it and click Add books to add the PDF (or multiple PDFs - Calibre supports batch converting multiple PDF files to text) you want to convert to text.
From the list of books, select the PDF (or multiple PDFs for batch conversion to .txt) you want to convert to text, and click the Convert books button. In the upper right-hand side of the conversion window, choose TXT as the Output format :
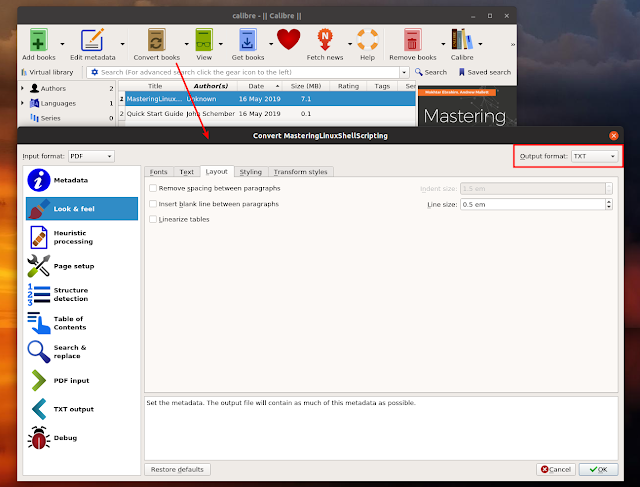
There are many options you can tweak in this conversion dialog. For example, you can choose to automatically remove spacing between paragraphs, or insert a blank line between paragraphs ( Look & Feel -> Layout ). You can also set the character encoding and line ending style (system, unix, windows, old_mac), and even format it to markdown.
After you're done with the configuration, click the OK button to start converting the PDF to text. The converted .txt file can be found in the directory where you've set the Calibre library location (and then in AuthorName/BookName subfolders; if the author or book name can't be determined, the subfolder is called "Unknown").
What Calibre lacks in this case is a way to only convert a page or a page range - it can currently only convert entire PDF files to text.
Convert PDF to text with pdftotext (command line)
pdftotext is a command line utility that converts PDF files to plain text. It has many options, including the ability to specify the page range to convert, maintain the original physical layout of the text as best as possible, set line endings (unix, dos or mac), and even work with password-protected PDF files.
pdftotextis part of the poppler / poppler-utils / poppler-tools package (depending on the Linux distribution you're using). Install this package as follows:
sudo apt install poppler-utilssudo dnf install poppler-utilssudo zypper install poppler-toolsIn other Linux distributions use your package manager to install the poppler / poppler-utils package.
Now that the package is installed, you can convert a PDF file to plain text and preserve its layout (I recommend using this -layout option for maintaining the original physical layout, but you can try it without it too) with:
pdftotext -layout input.pdf output.txtYou'll need to replace input.pdf with the name of the PDF file, and output.txt with the name you want the generated TXT file to be called. Also add the paths before filenames if needed (e.g. ~/Documents/mypdf.pdf ). If no output text file is specified, pdftotext will name the file with the same file name as the original PDF file.
The layout option preserves the PDF layout when converting it to text, even if multi-column PDF cases.
What if you want to only convert a page range of the PDF to text, instead of the whole PDF file? Use -f (first page to convert) and -l (last page to convert) followed by the page number, like this:
pdftotext -layout -f M -l N input.pdfReplace M and N with the first and last page number to extract, and input.pdf with the PDF filename.
Want to use mac, dos or unix end-of-line characters? You can specify that too, using -eol followed by mac , dos or unix . E.g. for unix line endings:
pdftotext -layout -eol unix input.pdfIf you don't want to insert page breaks between pages, append -nopgbrk :
pdftotext -layout nopgbrk input.pdfWant to batch convert all PDF files from a folder to text files? pdftotext doesn't support batch PDF to text conversion (and pdftotext *.pdf doesn't work), but you can convert all the PDF files in a folder to text files by using a Bash FOR loop:
for file in *.pdf; do pdftotext -layout "$file"; doneFor more options, run man pdftotext and pdftotext --help .
Pdftotext, convert a PDF to text from the terminal

In the next article we are going to take a look at pdftotext. This is an open source command line utility that will allow us to convert PDF files to plain text files. Basically what it does is extract the text data from the PDF files. This software is free and is included by default in many Gnu / Linux distributions.
In the following lines we are going to see a tool for the terminal, but for the same purpose of extracting text from PDF files you can also use a graphical tool like Caliber. It is worth noting that both the graphical tool and the one that we can use in the terminal, they cannot extract the text if the PDF is made of images (photographs, scanned book images, etc.).
On most Gnu / Linux distributions, pdftotext is included as part of the poppler-utils package. This tool is a command line utility that convert PDF files to plain text. In it we will find many options available, including the ability to specify the range of pages to convert, the ability to keep the original physical layout of the text as well as possible, set line endings, and even work with password-protected PDF files.
Install pdftotext on Ubuntu
To install this tool on our Ubuntu system, in case you don't already have it installed, you just have to open a terminal (Ctrl + Alt + T) and write the following command in it to install poppler-utils:

sudo apt install poppler-utils
How to use pdftotext
Convert a PDF file to text
Once we have the package installed on our operating system, we can convert a PDF file to plain text. Can try to keep the original design using the option -layout with the command, but we can also try without it. In a terminal (Ctrl + Alt + T) the command to use would be the following:

pdftotext -layout pdf-entrada.pdf pdf-salida.txt
In the previous command we would have to replace pdf-input.pdf with the name of the PDF file that we are interested in converting, and pdf-output.txt by the name of the TXT file in which we want to save the text of the input PDF file. If we don't specify any output text file, pdftotext will automatically name the file with the same name as the original PDF file but with a txt extension. Another thing that can be interesting to add to the command will be the paths before the file names if necessary (~ / Documents / pdf-input.pdf).
Convert only a range of PDF pages to text
If we are not interested in converting the entire PDF file, and we want narrow down a range of PDF pages to convert to text there will be use -f option (first page to convert) Y -l (last page to convert) followed by each option with the page number. The command to use would be something like the following:
pdftotext -layout -f P -l U pdf-entrada.pdf

In the previous command you will have to replace the letters P and U with the first and last page numbers to extract. The name of pdf-input.pdf We will also have to change it and give it the name of the PDF file with which we want to work.
Use end-of-line characters
This we will be able to specify using -eol followed by mac, dos or unix. The following command will add unix line endings:
pdftotext -layout -eol unix pdf-entrada.pdf
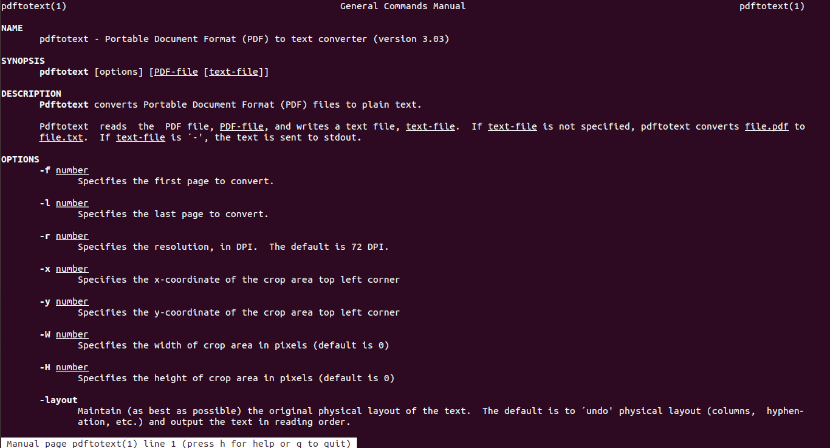
Help
To withdraw from your check available options, run the man page:
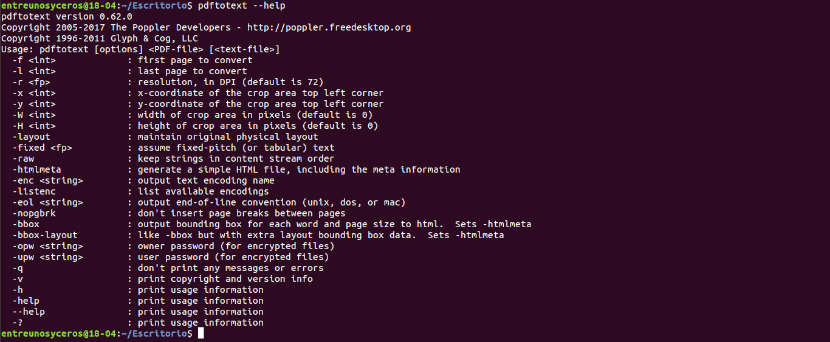
It also can consult the help option with the command:
Convert PDF files from a folder using a Bash FOR loop
In case we want to convert all PDF files in a folder to text files, pdftotext does not support batch conversion from PDF to text. Esto we will be able to do it using a Bash FOR loop in terminal (Ctrl + Alt + T):
for file in *.pdf; do pdftotext -layout "$file"; done
To withdraw from your more information about pdftotext, you can consult the project website. In case you prefer not to have to type commands in the terminal, you can also use a online service to get the same result.
The content of the article adheres to our principles of editorial ethics. To report an error click here.
Full path to article: ubunlog » Ubuntu » Pdftotext, convert a PDF to text from the terminal
A comment, leave yours
Leave a Comment Cancel reply

Moypher Nightkrelin said
yes, well it works, but sometimes I have to do OCR or use Libre Office Draw. In addition there are many pdf editors. and apparently this does not happen to text the images, so I do not see it practical. And Libre Office Draw is intuitive and practical.
How to extract text from pdf in script on Linux?
On Linux - How to extract text from a .pdf in which text really is text, not a scanned image? I want something I can use on the command line / in a script, not interactively. (I don't want to convert to .tif and use OCR - text is already available in the .pdf file, so why introduce inaccuracies from imperfect OCR?)
3 Answers 3
pdftotext that comes with poppler will try to extract any text found in the PDF.
Thanks for your quick response, Ignacio! I was already checking out pdftotext that comes w xpdf (from foolabs.com) - your answer prompted me to take another look, and I got it working. Poppler appears to have evolved from xpdf, so I will take a look at that too. Thanks again!
Ignacio's answer is just fine. In fact, it'd be the first thing on my list. Well, that and perhaps to suggest the pdftohtml tool that also comes with poppler, combined with pdfreflow if you want to try to reassemble the text into paragraphs, etc. (Of course, this will give you HTML output, but converting HTML to plain text can be done in many ways.)
Here are some other options too.
The ebook-convert command line tool from Calibre, which can convert .PDFs to plain text (or RTF or a number of ebook formats, like ePub, etc.)
Abiword can be called from the commandline to convert between any formats it can input from/export to, and with the appropriate import plugin, this includes PDFs:
(In fairness, I think AbiWord and calibre both use the poppler libraries, but I'm not positive.)