- Тюнинг сетевого стека Linux (nic performance)
- Отключение контроля перегрузок «`
- Поделиться
- Оставить комментарий
- Вам также может понравиться
- openvswitch
- Lldp linux, в поисках линка
- подписание rpm пакетов с помощью rutoken
- Яндекс задачки
- Тонкая настройка сетевого стека Linux (размер буферов) для повышения производительности сети
- Как настроить эти значения
Тюнинг сетевого стека Linux (nic performance)
IntMode 2 — режим MSI-X , нужен для поддержки multiqueue
RSS — сколько использовать очередей
VMDQ — отключаем, так как ненужен.
InterruptThrottleRate — устанавливаем 1 , подбирает динамически кол. прерываний в сек.
DCA — defaylt 1 (enable)
MQ — default 1 (enable) нужно включить для поддержки RSS
max_vfs — default 0
через запятую указываем значение для каждого порта,если четыре то =1,1,1,1
параметр allow_unsupported_sfp выставляем только одно значение = 1 , а не 1,1 если даже два порта
Отключение контроля перегрузок «`
### Отключение системное управление прерываний и передаем контроль NAPI. ethtool -C eth0 adaptive-rx off
### Настройка размера очередей приёма rx-buffers-increase *Узнать размер буфера* ip link set eth0 txqueuelen 10000
### Так как мы настроили распределение очередей по прерываниям (msi-x , rss ), то теперь их можно распределить по ядрам smp_affinity, c драйверами идет скрипт set_irq_affinity. с привязкой к одному cpu , посмотреть номер ядра к какому cpu относится set_irq_affinity 1,2,4,6,8,10,12,14,16,18,20,22 -x eth0
p.s.остановить демон балансировки service irqbalance stop ### Для распределения программных прерываний(pppoe) нужно задействовать RPS(rps_cups) ,и задействуем механизм упрвления потоками RFS(rps_flow_cnt) echo “0” > /sys/class/net/ens2f0/queues/rx-0/rps_cpus echo “1” > /sys/class/net/ens2f0/queues/rx-0/rps_cpus echo “2” > /sys/class/net/ens2f0/queues/rx-1/rps_cpus echo “4” > /sys/class/net/ens2f0/queues/rx-2/rps_cpus echo “8” > /sys/class/net/ens2f0/queues/rx-3/rps_cpus echo “10” > /sys/class/net/ens2f0/queues/rx-4/rps_cpus echo “20” > /sys/class/net/ens2f0/queues/rx-5/rps_cpus echo “40” > /sys/class/net/ens2f0/queues/rx-6/rps_cpus echo “80” > /sys/class/net/ens2f0/queues/rx-7/rps_cpus sysctl -w net.core.rps_sock_flow_entries=32768 echo 2048 > /sys/class/net/ens2f0/queues/rx-0/rps_flow_cnt echo 2048 > /sys/class/net/ens2f0/queues/rx-1/rps_flow_cnt echo 2048 > /sys/class/net/ens2f0/queues/rx-2/rps_flow_cnt echo 2048 > /sys/class/net/ens2f0/queues/rx-3/rps_flow_cnt echo 2048 > /sys/class/net/ens2f0/queues/rx-4/rps_flow_cnt echo 2048 > /sys/class/net/ens2f0/queues/rx-5/rps_flow_cnt echo 2048 > /sys/class/net/ens2f0/queues/rx-6/rps_flow_cnt echo 2048 > /sys/class/net/ens2f0/queues/rx-7/rps_flow_cnt
## Soft irq budget — это весь доступный бюджет, который будет разделён на все доступные NAPI-структуры, зарегистрированные на этот CPU. по умолчанию в некоторых системах он равен 300 , рекомендуется установить 600 для сетей 10Gb/s и выше sysctl -w net.core.netdev_budget=600
## Kernel buffer. *CORE settings (mostly for socket and UDP effect) set maximum receive socket buffer size, default 131071 * *set maximum send socket buffer size, default 131071* *set default receive socket buffer size, default 65535* *set default send socket buffer size, default 65535* *set maximum amount of option memory buffers, default 10240* [recommendet for 10G](https://downloadmirror.intel.com/5874/eng/README.txt) ### Tcp Udp kernel tune *TCP buffer* IPV4 specific settings *turn TCP timestamp support off, default 1, reduces CPU use* *turn SACK support off, default on on systems with a VERY fast bus -> memory interface this is the big gainer* *set min/default/max TCP read buffer, default 4096 87380 174760* net.ipv4.tcp_rmem = 10000000 10000000 10000000
*set min/pressure/max TCP write buffer, default 4096 16384 131072* net.ipv4.tcp_wmem = 10000000 10000000 10000000
*set min/pressure/max TCP buffer space, default 31744 32256 32768* net.ipv4.tcp_mem = 10000000 10000000 10000000
[recommendet for 10G](https://downloadmirror.intel.com/5874/eng/README.txt) ### UDP buffer size *UDP generally doesn’t need tweaks to improve performance, but you can increase the UDP buffer size if UDP packet losses are happening.* ### Miscellaneous tweaks *IP ports: net.ipv4.ip_local_port_range shows all the ports available for a new connection. If no port is free, the connection gets cancelled. Increasing this value helps to prevent this problem. default net.ipv4.ip_local_port_range = 32768 60999* sysctl -w net.ipv4.ip_local_port_range=’20000 60000’
sysctl -w net.ipv4.tcp_sack=0
sysctl -w net.ipv4.tcp_fin_timeout = 20
sysctl -w net.ipv4.tcp_timestamps=0
*Как долго держать запись о поднятой сессии (def 4 days)* ### Добавляем количество полуоткрытых соединений $sysctl -w net.core.somaxconn=2048
watch -n 1 cat /proc/interrupts watch -n 1 cat /proc/softirqs ethtool -S eth0
Хорошая работа сделана ребятами по написанию готовых скриптов [Пост на Хабре](https://habr.com/ru/post/340296/) p.s. Увеличение размера arp cache , если в dmesg появилось «Neighbour table overflow» net.ipv4.neigh.default.gc_thresh1 = 2048 net.ipv4.neigh.default.gc_thresh2 = 4096 net.ipv4.neigh.default.gc_thresh3 = 8192 «`
Дата изменения: July 11, 2019
Поделиться
Оставить комментарий
Вам также может понравиться
openvswitch
Lldp linux, в поисках линка
При удаленной работе на сервере к примеру когда ты находишся в дороге или не за своим буком или что-то подобное. Понадобилось изменить параметры порта комму.
подписание rpm пакетов с помощью rutoken
1) config.vm.box = “generic/ubuntu1904”
Яндекс задачки
1.Напишите регулярное выражение, с помощью которого из URL можно извлечь его домен. Для проверки вашего регулярного выражения будет использован следующий фай.
Тонкая настройка сетевого стека Linux (размер буферов) для повышения производительности сети
У меня два сервера, расположенных в двух разных центрах обработки данных. Оба сервера имеют дело с множеством одновременных передач больших файлов. Но производительность сети очень низкая для больших файлов, и снижение производительности происходит с большими файлами. Как мне настроить TCP под Linux, чтобы решить эту проблему?
По умолчанию сетевой стек Linux не настроен для высокоскоростной передачи больших файлов по каналам WAN. Это сделано для экономии ресурсов памяти. Вы можете легко настроить сетевой стек Linux, увеличив размер сетевых буферов для высокоскоростных сетей, которые соединяют серверные системы для обработки большего количества сетевых пакетов.
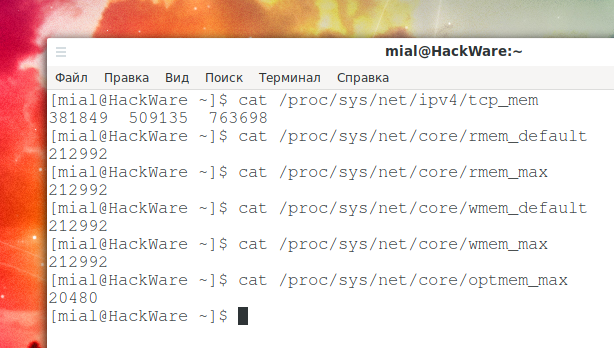
Максимальный размер буфера TCP в Linux по умолчанию слишком мал. Память TCP рассчитывается автоматически на основе системной памяти; вы можете найти фактические значения, введя следующие команды:
cat /proc/sys/net/ipv4/tcp_mem
Объём для принимающей памяти сокета по умолчанию и максимальный:
cat /proc/sys/net/core/rmem_default cat /proc/sys/net/core/rmem_max
По умолчанию и максимальный объём памяти для сокета отправки:
cat /proc/sys/net/core/wmem_default cat /proc/sys/net/core/wmem_max
Максимальный объём опциональных буферов памяти:
cat /proc/sys/net/core/optmem_max
Как настроить эти значения
Внимание: значение по умолчанию для rmem_max и wmem_max составляет около 208 КБ в большинстве дистрибутивов Linux, что может быть достаточно для сетевой среды общего назначения с низкой задержкой или для таких приложений, как DNS/веб-сервер. Однако, если задержка велика, размер по умолчанию может быть слишком маленьким. Обратите внимание, что следующие настройки увеличивают использование памяти на вашем сервере.
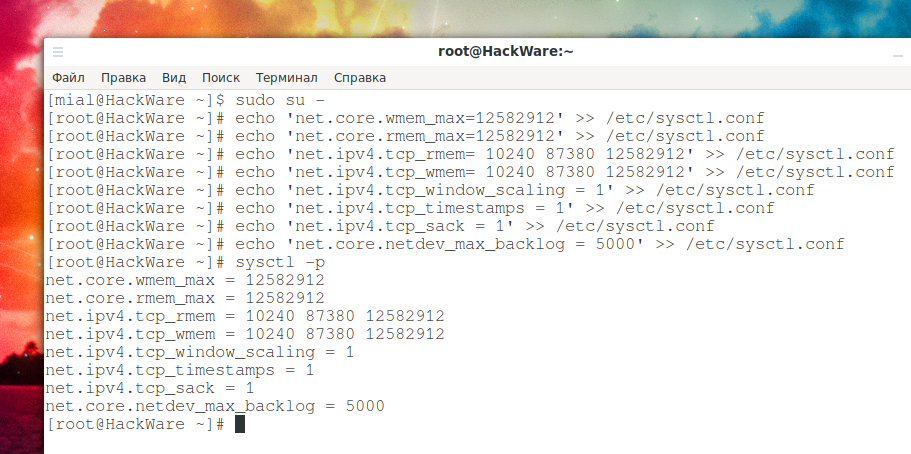
Установите максимальный размер буфера отправки (wmem) ОС и размер буфера приёма (rmem) равным 12 МБ для очередей по всем протоколам. Другими словами, установите объём памяти, который выделяется для каждого сокета TCP, когда он открывается или создаётся при передаче файлов:
sudo su - echo 'net.core.wmem_max=12582912' >> /etc/sysctl.conf echo 'net.core.rmem_max=12582912' >> /etc/sysctl.conf
Вам также необходимо установить минимальный размер, начальный размер и максимальный размер в байтах:
echo 'net.ipv4.tcp_rmem= 10240 87380 12582912' >> /etc/sysctl.conf echo 'net.ipv4.tcp_wmem= 10240 87380 12582912' >> /etc/sysctl.conf
Включите масштабирование окна, которое может быть опцией увеличения окна передачи:
echo 'net.ipv4.tcp_window_scaling = 1' >> /etc/sysctl.conf
Включите отметки времени, как определено в RFC1323:
echo 'net.ipv4.tcp_timestamps = 1' >> /etc/sysctl.conf
Включить выбор подтверждений:
echo 'net.ipv4.tcp_sack = 1' >> /etc/sysctl.conf
По умолчанию TCP сохраняет различные метрики соединения в кэше маршрута при закрытии соединения, так что соединения, установленные в ближайшем будущем, могут использовать их для установки начальных условий. Обычно это увеличивает общую производительность, но иногда может вызывать снижение производительности. Если установлено, TCP не будет кэшировать метрики при закрытии соединений.
echo 'net.ipv4.tcp_no_metrics_save = 1' >> /etc/sysctl.conf
Установите максимальное количество пакетов, помещаемых в очередь на стороне INPUT, когда интерфейс получает пакеты быстрее, чем ядро может их обработать.
echo 'net.core.netdev_max_backlog = 5000' >> /etc/sysctl.conf
Теперь перезагрузите изменения:
Используйте tcpdump для просмотра изменений для eth0: