- Удаление знаков переноса с возвратом строки
- 4 ответа 4
- Как удалить newline (символ новой строки) из вывода команд и файлов в командной строке Linux
- Как удалить newline (перевод строки) из строки в Bash
- Как удалить символ newline из строки
- echo
- tr
- sed
- Perl
- awk
- Удаление newline из результатов выполнения команды
- printf
- xargs и echo
- Подстановка команды
- Как удалить только последний символ newline из многострочного вывода
- Perl
- printf
- Как удалить newline из файла в Bash
- Как удалить newline из переменной в Bash
- Как заменить newline («\n») на пробел (» «)
- tr
- sed
- Bash
- Perl
- paste
- awk
- xargs
- Как убрать перенос строк с помощью sed?
- Похожие темы
- Удаление знаков переноса строки в bash
- 3 ответа 3
Удаление знаков переноса с возвратом строки
при выгрузке случился баг и после data3 добавился знак переноса строки \n и все сьехало на две строки. data3 обрамлен » (двойные ковычки) файл очень большой 1 мил строк и в ручную не вариант переделывать подскажите как через sed убрать перенос строки для того чтобы сьехавший хвост вытянулся в одну строку сейчас файл имеет такой вид
data1,data2,"data3 ",data4 data1,data2,"data3 ",data4 data1,data2,"data3 ",data4 data1,data2,"data3",data4 data1,data2,"data3",data4 data1,data2,"data3",data4 4 ответа 4
[VladD@Kenga] [00:59:25] [~] $> cat xx.txt data1,data2,"data3 ",data4 data1,data2,"data3 ",data4 data1,data2,"data3 ",data4 [VladD@Kenga] [00:59:32] [~] $> sed 'N;s/\n"/"/' xx.txt data1,data2,"data3",data4 data1,data2,"data3",data4 data1,data2,"data3",data4 Для более сложных случаев (возможны «обыкновенные» строки) попробуйте так:
[VladD@Kenga] [01:35:47] [~] $> cat xx.txt header "data1",data2,"data3 ",data4 intermediate data data1,"data2 ","data3 ",data4 data1,data2,"data3 ",data4 [VladD@Kenga] [01:35:52] [~] $> sed '/^",/; x' xx.txt header "data1",data2,"data3",data4 intermediate data data1,"data2","data3",data4 data1,data2,"data3",data4 [VladD@Kenga] [01:35:57] [~] $> sed '/^",/; x' xx.txt | sed '1d' header "data1",data2,"data3",data4 intermediate data data1,"data2","data3",data4 data1,data2,"data3",data4 Внимение: последняя строка должна заканчиваться переводом строки, иначе она будет «проглочена»!
Объяснение: нам необходимо, когда мы видим строку, начинающуюся с кавычки, знать предыдущую строку, чтобы склеить их. Для этого мы «задерживаем» вывод строк, отправляя их в hold space вместо вывода, и выводя вместо этого предыдущую строку, лежащую там же ( x ).
Для случая, когда строка начинается с кавычки ( /^»/ ) начинаем действовать. В hold space лежит предыдущая строка, пристыковываем к ней текущую ( H ), и обмениваем hold space с pattern space ( x ), чтобы можно было обработать текст. Удаляем \n ( s/\n// ), и отправляем назад строку в hold space, чтобы проанализировать и вывести её на следующем цикле. Обрубок строки, который получился в pattern space, удаляем, и завершаем эту итерацию ( d ).
Как удалить newline (символ новой строки) из вывода команд и файлов в командной строке Linux
Как удалить newline (перевод строки) из строки в Bash
Для перевода строки в операционных системах используются символы:
Причём в Linux используется \n (также называется EOL, End of Line, newline, новая строка). В других операционных системах могут быть вариации.
По умолчанию многие программы, утилиты командной строки Linux автоматически добавляют символ newline — в целом это делает вывод более читаемым. Но иногда символ перевода строки не нужен. Эта заметка посвящена тому, как убрать из строки вывода или из строк файла символ новой строки (newline).
Как удалить символ newline из строки
echo
Если вы выводите строку или результат выполнения команды с помощью «echo», то вы можете использовать опцию -n, которая означает не выводить конечный символ newline.
Обратите внимание на различный результат команд:
echo -n 'HackWare.ru' | md5sum ce7d43633e2bfb3d283f2cfbdbeb0d2a - echo 'HackWare.ru' | md5sum 19acfcdef400742c5de064e0bf9e9a87 -
Первая команда считает контрольную сумму строки «HackWare.ru», а вторая команда считает контрольную сумму строки «HackWare.ru» к которой добавлен конечный символ newline.

tr
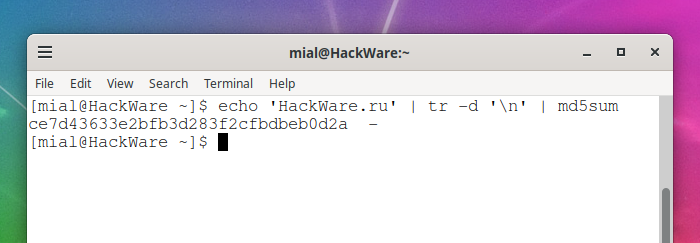
Вы можете удалить конечный символ новой строки с помощью tr в конструкции
echo 'HackWare.ru' | tr -d '\n' | md5sum ce7d43633e2bfb3d283f2cfbdbeb0d2a -
sed
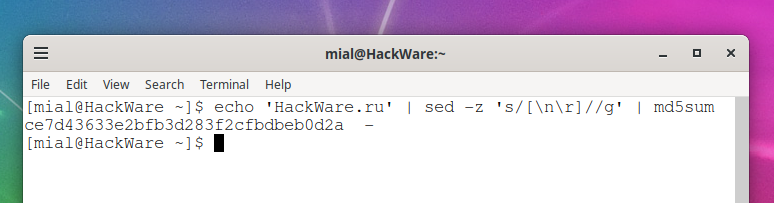
Вы можете удалить конечный символ новой строки с помощью sed в конструкции (данная команда удаляет символы «\n» и «\r»:
echo 'HackWare.ru' | sed -z 's/[\n\r]//g' | md5sum ce7d43633e2bfb3d283f2cfbdbeb0d2a -
Perl
Следующая конструкция на PERL также удаляет символ новой строки:
echo 'HackWare.ru' | perl -pe 'chomp' | md5sum ce7d43633e2bfb3d283f2cfbdbeb0d2a -
Ещё один пример использования:
awk
С помощью awk вы можете удалить символы newline (новой строки) используя следующую конструкцию:
echo 'HackWare.ru' | awk '< printf "%s", $0 >' | md5sum
Смотрите также: Уроки по Awk
echo 'HackWare.ru' | awk '' | md5sum
Удаление newline из результатов выполнения команды
Все предыдущие примеры можно использовать для удаления newline из вывода команд, передав вывод по конвейеру (трубе, «|»). Далее приведены ещё несколько конструкций, которые вы можете использовать для удаления newline из результатов выполнения команды.
printf
Поместите КОМАНДУ в конструкцию вида:
Будет выведен результат выполнения КОМАНДЫ без конечного символа newline.
printf '%s' $(echo 'HackWare.ru') | md5sum
xargs и echo
Для подавления вывода символа новой строки newline вы можете использовать конструкцию с xargs:
Будьте внимательны с предыдущей конструкцией, поскольку она также ещё и сжимает пробелы. Чтобы понять о чём идёт речь, изучите вывод следующей команды:
echo «a b» | xargs echo -n; echo -n $(echo «a b»)
Поскольку xargs может быть очень медленной, вы можете использовать следующую конструкцию:
Помните, что если вывод начинается с -e, то предыдущая конструкция будет истолковывать вывод как опцию echo.
Подстановка команды
В следующих примерах команда, заключённая в «$(КОМАНДА)» будет выведена без конечного newline:
Как удалить только последний символ newline из многострочного вывода
Все предыдущие примеры подразумевают, что удаление символа выполняется из однострочного вывода. Если вам нужно удалить последний символ из многострочного вывода, то далее показано, как это сделать.
Perl
Следующая команда выведет содержимое файла log.txt, при этом будет удалён только один символ newline в самом конце файла, все остальные newline будут сохранены. Особенностью команды является то, что даже если файл заканчивается на несколько символов newline, все они будут удалены.
perl -pe 'chomp if eof' log.txt
printf
Следующий пример также удалит символ newline в конце файла log.txt, но удалён будет строго ПОСЛЕДНИЙ символ newline:
Как удалить newline из файла в Bash
Вы можете использовать вывод содержимого файла в паре с любой из перечисленных выше конструкций для удаления newline. Например:
Аналог предыдущей команды:
Команды awk, sed, perl и другие могут как обрабатывать стандартный ввод, так и получать имена файла, который нужно обработать (удалить символы newline) в виде опции. Примеры:
awk '< printf "%s", $0 >' log.txt awk '' file sed ':a;N;$!ba;s/\n//g' file.txt perl -p -i -e 's/\R//g;' filename
Как удалить newline из переменной в Bash
Для удаления символа newline (или любых других символов) вы можете использовать Pattern substitution (разновидность Shell Parameter Expansion), формат следующий:
При этом символ newline (\n) нужно экранировать обратным слэшом.
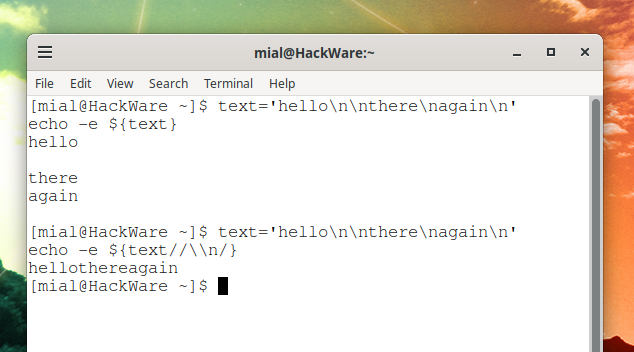
Вывод переменной без удаления newline:
text=’hello\n\nthere\nagain\n’ echo -e $
Вывод переменной с удалением всех newline:
text='hello\n\nthere\nagain\n' echo -e $
Вывод переменной с удалением только первого newline:
text='hello\n\nthere\nagain\n' echo -e $
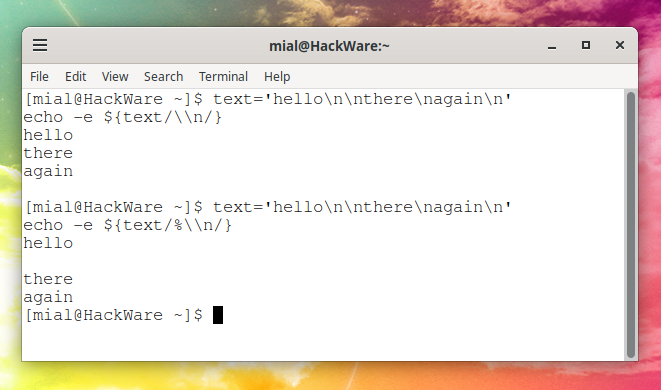
Вывод переменной с удалением последнего newline:
text='hello\n\nthere\nagain\n' echo -e $
Как заменить newline («\n») на пробел (» «)
tr
Чтобы заменить newline («\n«) на пробел вы можете использовать следующую конструкцию:
echo -e 'hello\n\nthere\nagain\n' | tr '\n' ' '
sed
Кросс-платформенный совместимый синтаксис, который работает с BSD и OS X sed:
sed -e ':a' -e 'N' -e '$!ba' -e 's/\n/ /g' FILE
В GNU sed есть опция -z для записей (строк), разделённых нулём. Вы можете просто вызвать:
Bash
while read line; do printf "%s" "$line "; done < FILE
cat FILE.txt | while read line; do echo -n "$line "; done
Ещё один вариант написания:
while read line; do echo -n "$line "; done < FILE.txt
Perl
Решение на perl, скорость примерно как с sed:
paste
Решение с paste, скорость примерно как с tr, может заменять только один символ:
awk
Решение с awk, скорость примерно как с tr:
Программа awk состоит из правил, состоящих из условных кодовых блоков, то есть:
Если кодовый блок опущен, используется значение по умолчанию: . Таким образом, 1 всегда интерпретируется как истинное условие, и для каждой строки выполняется print $0.
Когда awk читает ввод, он разбивает его на записи на основе значения RS (Record Separator, разделитель записей), который по умолчанию является newline (новой строкой), поэтому awk по умолчанию будет анализировать ввод построчно. Разделение также включает удаление RS из входной записи.
Теперь при печати записи к ней добавляется ORS (Output Record Separator, разделитель выходных записей), по умолчанию снова newline. Таким образом, поскольку мы заменили значение ORS на пробел, все символы новой строки заменяются пробелами.
Смотрите также: Уроки по Awk
Ещё один вариант, чтобы заменить все новые строки пробелами с помощью awk, не считывая весь файл в память:
Если вы хотите, чтобы присутствовал финальный newline:
Вы можете использовать не только символ пробела (в данном случае вместо пробела разделителем является символ «|»):
Ещё одно просто решение на awk:
xargs
Простое решение на xargs:
Как убрать перенос строк с помощью sed?
illifant и mm3 большое спасибо. Ваши ответы очень помогли.

если нужно удалить все \n, то проще использовать

А зачем там «/$/N» вместо просто «N»?
Тема обсосана на stackoverflow.
Мёсье не осилил увидеть команды : и t на видном месте в мане, и теперь со всех требует прув, не допуская существования более вдумчивых людей?
без понятия что означают все эти 20 символов (объяснил бы хоть кто), но они работают.
Здесь куча способов удалить '\n' на разных языках.
Эти? 1) метка 2) добавляем к текущей строке сдедующую (через \n) 3) удаляем разделитель 3) если команда s/// что-то сделала - переходим на метку.
Видно, что /$/ - лишний, но /../ может пригодиться, например: /\\$/.
Похожие темы
- Форум всемогущий sed (2017)
- Форум sed vs awk (2008)
- Форум Удалить последнее слово в строке awk, sed (2014)
- Форум sed диапазон строк (2013)
- Форум Как с помощью sed вставить в конец каждой строки файла апостроф? (2022)
- Форум Оптимизировать sed разбивку файла (2020)
- Форум Разделитель ascii для sed и awk (2015)
- Форум awk и sed (2011)
- Форум Sed (вырезать подстроки из строки) (2012)
- Форум Книги по AWK, SED (2013)
Удаление знаков переноса строки в bash
Регулярка извлекает с файла кусок многострочного текста. Следующая задача - получить из него одну строку. Попробовал sed "s/\r\n//" . Комбинации опробованы различные. Гуглю различные вариации обозначения знака переноса, не получается. За направление правильного гуления скажу большое спасибо ). текст - utf-8.
stroka3 stroka2 stroka1 stroka1 stroka2 stroka3 - результат \n разнообразно опробован и без результата. различные флаги sed и tr
Что-то вы делаете не так :) $ cat in.txt stroka3 stroka2 stroka1 stroka1 stroka2 stroka3 $ cat in.txt | tr -s '\r\n' ' ' stroka3 stroka2 stroka1 stroka1 stroka2 stroka3 $ cat in.txt | tr -d '\r\n' stroka3stroka2stroka1stroka1stroka2stroka3
3 ответа 3
cat in.txt | tr -s '\r\n' ' ' > out.txt Или, если склеить строки (в примере выше \r\n меняется на пробел):
cat in.txt | tr -d '\r\n' > out.txt P.S. '\r\n' меняем на '\n' для unix-переводов строк.
смотрим содержимое файла in.txt ~ $ cat in.txt stroka3
stroka2 stroka1 stroka1 stroka2 stroka3 загоняем всё что в файле в переменную
с помощью echo выводим содержимое переменной
~ $ echo "$string" # переменная в кавычках выдаст с переносами строк stroka3 stroka2 stroka1 stroka1 stroka2 stroka3 ~ $ echo $string # переменная БЕЗ кавычкех выдаст БЕЗ переносов строк stroka3 stroka2 stroka1 stroka1 stroka2 stroka3