- Команда Head в Linux
- Синтаксис команды Head
- Как использовать команду головы
- Как отобразить определенное количество строк
- Как отобразить определенное количество байтов
- Как отображать несколько файлов
- Как использовать голову с другими командами
- Выводы
- Linux вывод первой строки
- Примеры использования
- Вывод первых десяти строк текстового файла
- Вывод заданного количества строк текстового файла
- Вывод заданного количества байтов файла
- Обработка вывода других утилит
- Вывод первых строк нескольких файлов
- Команда head linux
- Команда head в Linux
- Примеры использования head
- Выводы
Команда Head в Linux
Команда head выводит первые строки (по умолчанию 10 строк) одного или нескольких файлов или передаваемых данных в стандартный вывод.
В этом руководстве мы объясним, как использовать утилиту head в Linux, на практических примерах и подробных объяснениях наиболее распространенных опций head.
Синтаксис команды Head
Синтаксис команды head следующий:
- OPTION — варианты головы . Мы рассмотрим наиболее распространенные варианты в следующих разделах.
- FILE — Ноль или более имен входных файлов. Если ФАЙЛ не указан или если ФАЙЛ — — , head будет читать стандартный ввод.
Как использовать команду головы
В простейшей форме при использовании без каких-либо параметров команда head отобразит первые 10 строк.
Как отобразить определенное количество строк
Используйте параметр -n ( —lines ), за которым следует целое число, указывающее количество отображаемых строк:
Вы можете опустить букву n и использовать только дефис ( — ) и цифру (без пробелов между ними).
Чтобы отобразить первые 30 строк файла с именем filename.txt , введите:
Следующее приведет к тому же результату, что и приведенные выше команды:
Как отобразить определенное количество байтов
Параметр -c ( —bytes ) позволяет распечатать определенное количество байтов:
Например, чтобы отобразить первые 100 байтов данных из файла с именем filename.txt , введите:
Вы также можете использовать суффикс множителя после числа, чтобы указать количество отображаемых байтов. b умножает его на 512, kB умножает на 1000, K умножает на 1024, MB умножает на 1000000, M умножает на 1048576 и так далее.
Следующая команда отобразит первые пять килобайт (2048) файла filename.txt :
Как отображать несколько файлов
Если в качестве входных данных для команды head указано несколько файлов, она отобразит первые десять строк из каждого предоставленного файла.
head filename1.txt filename2.txtВы можете использовать те же параметры, что и при отображении одного файла.
В этом примере показаны первые 20 строк файлов filename1.txt и filename2.txt :
head -n 20 filename1.txt filename2.txtЕсли используется более одного файла, каждому выходному файлу предшествует заголовок с именем файла.
Как использовать голову с другими командами
Команду head можно использовать в сочетании с другими командами, перенаправляя стандартный вывод из / в другие утилиты с помощью каналов.
Следующая команда будет хешировать переменную среды $RANDOM , отображать первые 32 байта и отображать случайную строку из 24 символов:
echo $RANDOM | sha512sum | head -c 24 ; echoВыводы
К настоящему времени вы должны хорошо понимать, как использовать команду Linux head. Это дополнение к команде tail, которая выводит последние строки файла на терминал.
Linux вывод первой строки
Команда head позволяет задействовать одноименную утилиту для вывода нескольких первых строк из текстового файла или вывода другой утилиты. Если вы исполняете команду, которая выводит большой объем данных и при этом заинтересованы лишь в нескольких первых строках вывода, эта команда — именно то, что вам нужно.
Базовый синтаксис команды выглядит следующим образом:
Утилита head может выводить как начальные строки вывода другой утилиты (в этом случае имен файлов не указывается), так и начальные строки одного или нескольких текстовых файлов с указанными именами. В том случае, если выводятся начальные строки нескольких файлов, их имена упоминаются в выводе. Утилита поддерживает ряд полезных параметров, а именно, параметр -n, позволяющий задать количество выводимых строк (по умолчанию выводится 10 строк), параметр -c, позволяющий задать количество выводимых байтов, параметр -q, позволяющий не добавлять информацию об именах файлов в вывод с их начальными строками, параметр -v, позволяющий всегда выводить информацию об именах файлов, а также параметр -z, позволяющий выводить символы завершения строк вместо символов перехода на новые строки (это полезно для использования утилиты со стороны других утилит).
Примеры использования
Вывод первых десяти строк текстового файла
Для вывода первых десяти строк текстового файла достаточно использовать утилиту head без каких-либо параметров:
$ head 1342.txt
PRIDE AND PREJUDICE
It is a truth universally acknowledged, that a single man in possession
Очевидно, что утилита вывела первые 10 строк файла.
Вывод заданного количества строк текстового файла
Для вывода заданного количества строк текстового файла следует использовать параметр -n:
$ head -n 3 1342.txt
PRIDE AND PREJUDICE
Теперь утилита вывела лишь необходимые три строки.
Вывод заданного количества байтов файла
Для того, чтобы вывести заданное количество байтов вместо заданного количества строк, достаточно использовать параметр -c таким же образом, как ранее использованный параметр -n:
$ head -c 23 1342.txt
PRIDE AND PREJUDICE
В первые 23 байта вошла первая строка текстового файла с символом перехода на новую строку.
Обработка вывода других утилит
Для того, чтобы вывести лишь первые строки вывода другой утилиты, достаточно использовать простой конвейер командной оболочки и не указывать имен файлов:
$ cat 1342.txt | head -n 3
PRIDE AND PREJUDICE
Утилита cat читает все содержимое текстового файла, а утилита head выполняет роль фильтра, выводя лишь три первые строки этого содержимого.
Вывод первых строк нескольких файлов
$ head -n 3 1342.txt 74.txt
==> 1342.txt PRIDE AND PREJUDICE
==> 74.txt THE ADVENTURES OF TOM SAWYER
Теперь утилита добавляет в вывод имена текстовых файлов для того, чтобы не возникало путаницы; в остальном она работает точно так же.
Команда head linux
Команда head выводит начальные строки (по умолчанию — 10) из одного или нескольких документов. Также она может показывать данные, которые передает на вывод другая утилита.
Сегодня мы расскажем как работает эта команда для Linux и покажем, как используются на практике наиболее популярные опции head.
Команда head в Linux
Синтаксис у команды head следующий:
$ head опции файл
- Опции — это параметр, который позволяет настраивать работу команды таким образом, чтобы результат соответствовал конкретным потребностям пользователя.
- Файл — это имя документа (или имена документов, если их несколько). Если это значение не задано либо вместо него стоит знак «-», команда будет брать данные из стандартного вывода.
Чаще всего к команде head применяются такие опции:
- -c (—bytes) — позволяет задавать количество текста не в строках, а в байтах. При записи в виде —bytes=[-]NUM выводит на экран все содержимое файла, кроме NUM байт, расположенных в конце документа.
- -n (—lines) — показывает заданное количество строк вместо 10, которые выводятся по умолчанию. Если записать эту опцию в виде —lines=[-]NUM, будет показан весь текст кроме последних NUM строк.
- -q (—quiet, —silent) — выводит только текст, не добавляя к нему название файла.
- -v (—verbose) — перед текстом выводит название файла.
- -z (—zero-terminated) — символы перехода на новую строку заменяет символами завершения строк.
Переменная NUM, упомянутая выше — это любое число от 0 до бесконечности, задаваемое пользователем. Оно может быть обычным либо содержать в себе множитель.
Примеры использования head
Самый простой способ использования команды head — с указанием имени файла, но без опций. В таком случае будут выведены на экран первые 10 строк.
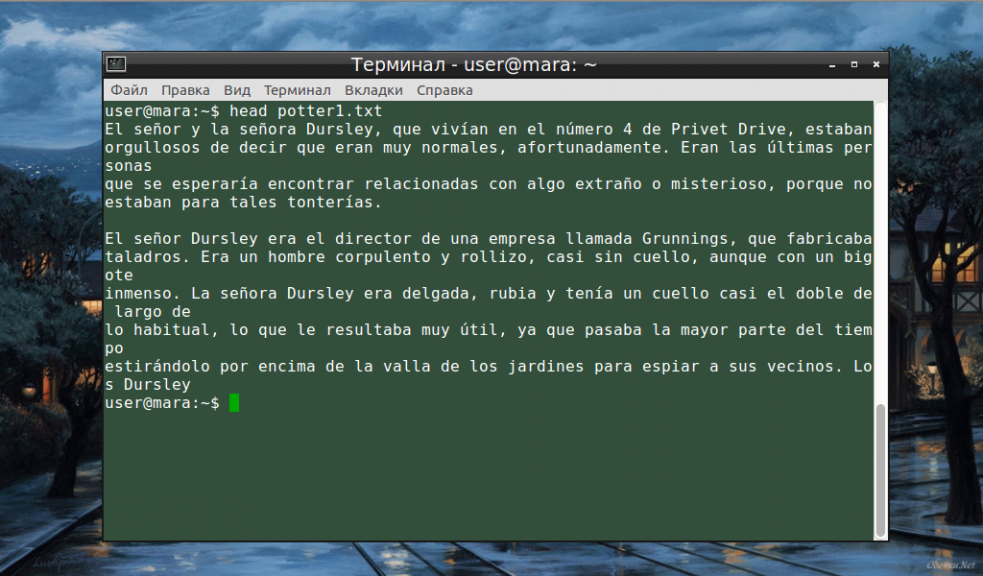
Если нужно единовременно получить вывод с нескольких файлов, с этим тоже не возникнет проблем. Достаточно перечислить названия, разделяя их пробелом:
head file-name1.txt file-name2.txt
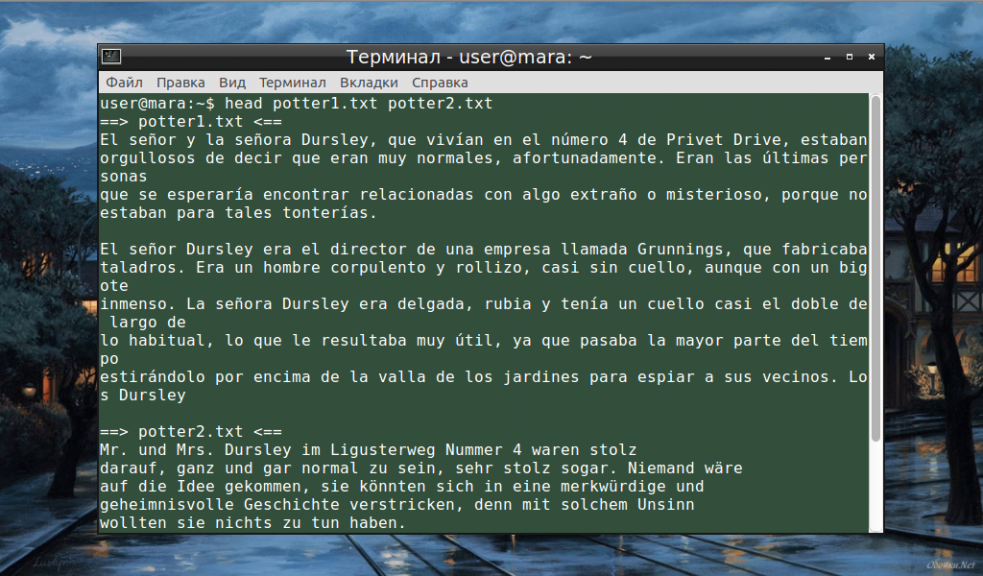
Разумеется, файлов может быть и три, и четыре, и больше. Чтобы не возникало путаницы, их содержимое автоматически разделяется пустой строкой, а перед текстом выводится название документа.
Чтобы название файла выводилось даже в том случае, когда команде задан только один документ, следует воспользоваться опцией -v:
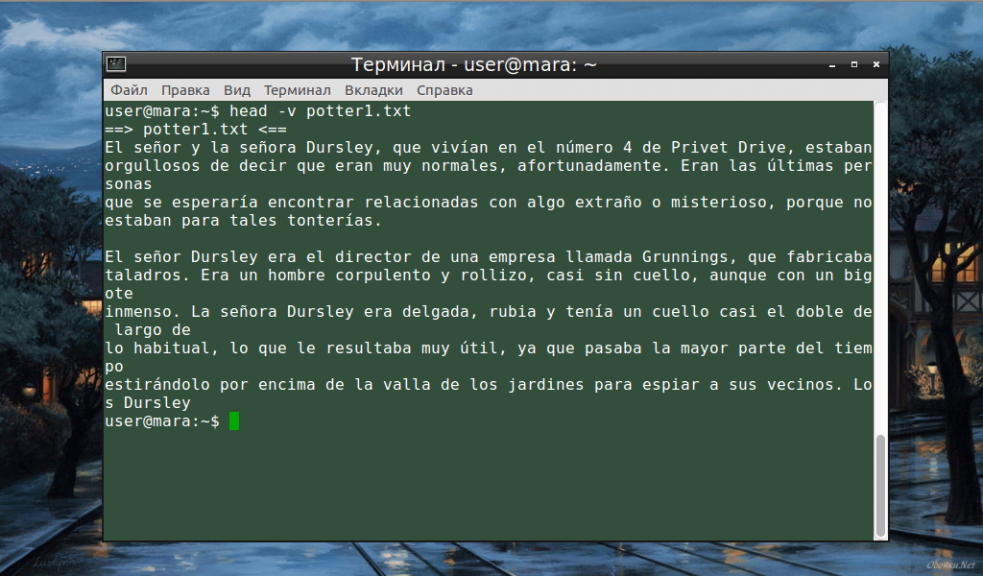
Если десяти строк, по умолчанию выводимых командой, окажется слишком мало или слишком много, ничто не мешает изменить их количество вручную. Для этой цели служит опция -n:
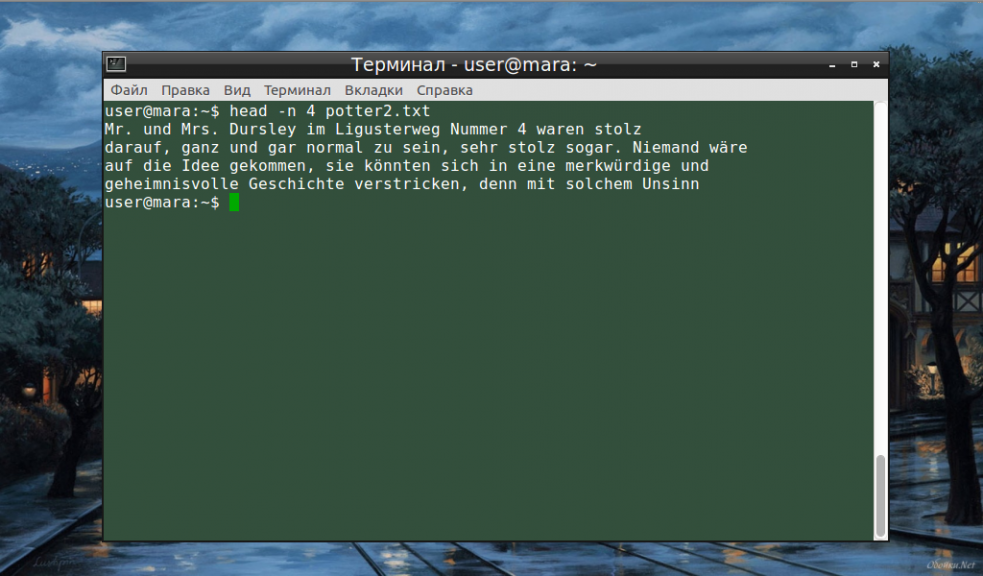
Не будем забывать об еще одном интересном свойстве этой опции. Она позволяет вывести то количество строк, которое останется после «отсечения» лишнего текста. Для этого нужно использовать не сокращенную (однобуквенную), а полную запись опции:
Во время работы в терминале квадратные скобки не используются, знак минуса идет сразу же после знака равно. Вместо NUM следует указать число. Вот как выглядит запись команды и ее результат на скриншоте.
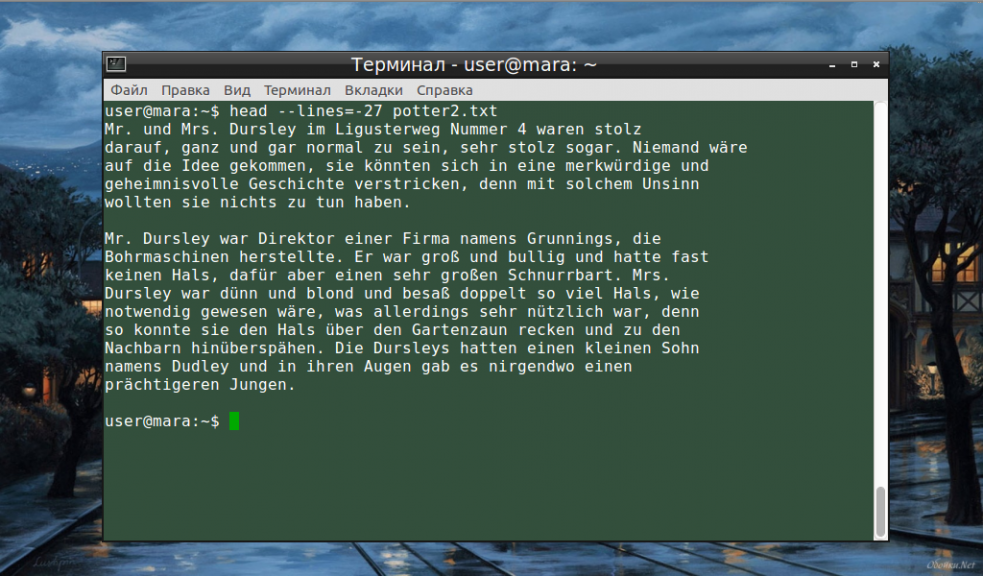
Следует заметить, что строки «отсекаются», начиная с последней.
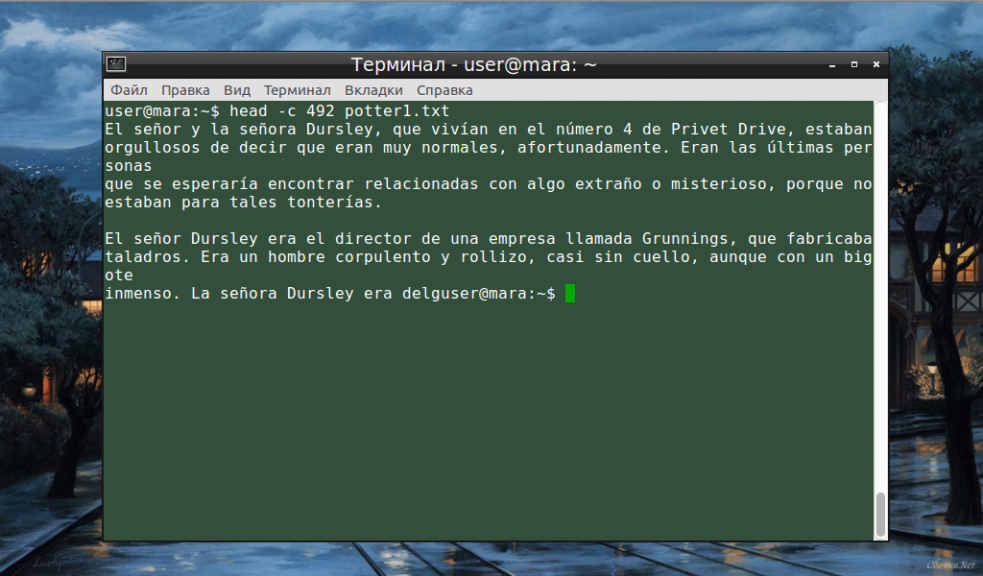
До этого момента мы (и команда head вместе с нами) считали количество текста построчно. Но это не обязательное условие — с таким же успехом единицей измерения может быть байт. Достаточно сообщить команде о новом правиле работы с помощью опции -с, заодно указав и количество байт, которое нужно вывести на экран (NUM):
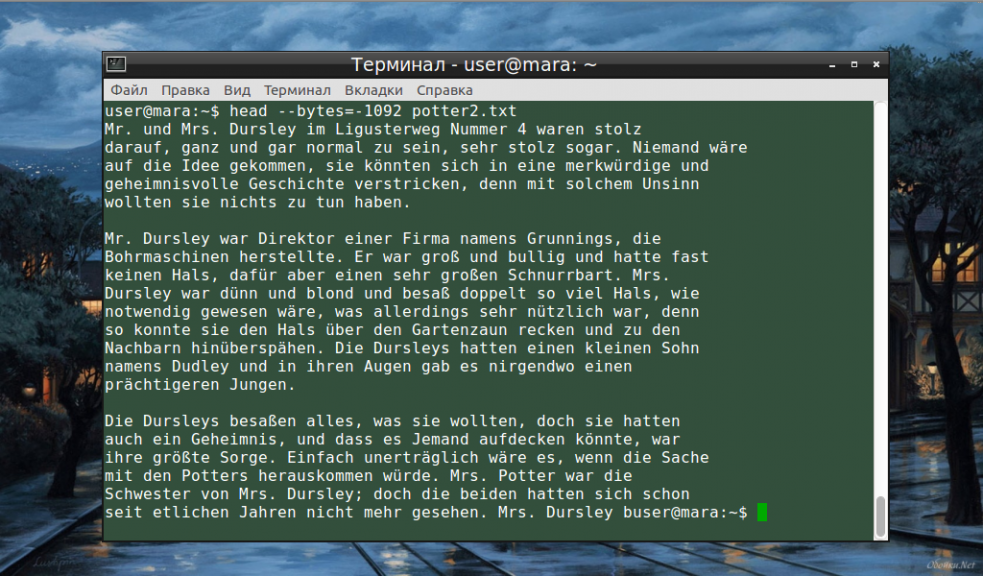
Как и в случае с опцией —lines, можно «отсечь» ненужный объем текста, используя полную форму опции -с — —bytes. Запись команды проводится по тому же принципу и лишние байты тоже отсчитываются, начиная с конца документа:
При записи байт можно использовать буквенные суффиксы:
Кстати, команду head можно использовать не только самостоятельно, но и в сочетании с другими командами. Например, такая запись хеширует рандомно выбранную переменную среды, выводит первые 32 байта из указанного файла и отображает случайную строку из 24 символов:
echo $RANDOM | sha512sum | head -c 24 file-name.txt; echo
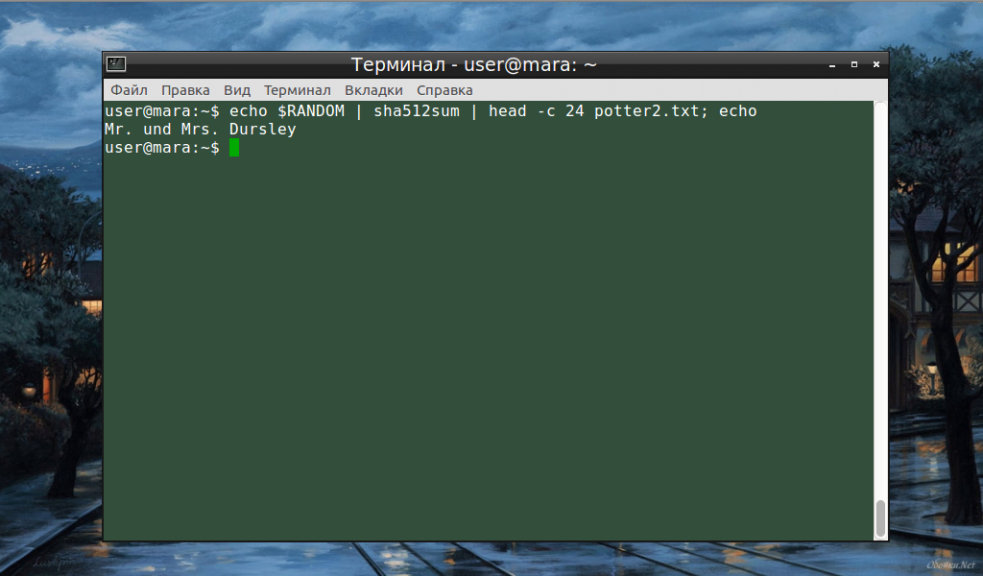
На этом наши примеры head linux подошли к завершению.
Выводы
Команда head linux, которая выводит начальные строки файла, — это в некотором роде антагонист команды tail (она печатает в терминале последние строки). Поскольку ее синтаксис довольно прост, у пользователей, как правило, не возникает проблем с использованием этой команды. Если у вас появились вопросы или замечания по части команды head и ее применения в Linux-системах, обязательно оставьте комментарий внизу.
Обнаружили ошибку в тексте? Сообщите мне об этом. Выделите текст с ошибкой и нажмите Ctrl+Enter.