- Команда wget Linux
- Синтаксис Wget
- Опции
- Использование wget Linux
- 1. Загрузка файла
- 2. Сохранить файл с другим именем
- 3. Скачать несколько файлов
- 4. Взять URL из файла
- 5. Продолжить загрузку
- 6. Загрузка файлов в фоне
- 7. Ограничение скорости загрузки
- 8. Подключение по логину и паролю
- 9. Загрузить и выполнить
- 10. Сохранить файл в папке
- 11. Передать информацию о браузере
- 12. Количество попыток загрузки
- 13. Квота загрузки
- 14. Скачать сайт
- Выводы
- How to specify the download location with wget?
- 5 Answers 5
Команда wget Linux
Работая в консоли, нам достаточно часто приходится взаимодействовать с сетью, например скачивать файлы или целые интернет страницы. Если интернет страницы мы скачиваем довольно редко, то с файлами дело обстоит совсем по другому. Это могут быть различные скрипты, установочные пакеты, программы, ключи, списки пакетов и многое другое. Скачать файл в консоли Linux можно с помощью утилиты wget. Ее мы и рассмотрим в этой статье.
Это очень мощная утилита, способная работать по протоколам HTTP, HTTPS и FTP. Кроме того поддерживается работа через прокси. Команда wget linux, может выполнять загрузку файлов даже в фоновом режиме — без участия пользователя, в отличии от большинства веб браузеров.
Кроме скачивания файлов, есть возможность сохранять веб страницы или даже целые веб-сайты, благодаря функции открытия ссылок на страницах. Такую возможность еще называют рекурсивной загрузкой. Это все мы и рассмотрим в сегодняшней статье, но начнем, как всегда, с синтаксиса и основных опций утилиты.
Синтаксис Wget
Команда wget linux имеет очень простой синтаксис:
$ wget опции аддресс_ссылки
Можно указать не один URL для загрузки, а сразу несколько. Опции указывать не обязательно, но в большинстве случаев они используются для настройки параметров загрузки.
Опции
Синтаксис опций очень свободный. У каждой опции, как правило есть как длинное, так и короткое имя. Их можно записывать как до URL, так и после. Между опцией и ее значением не обязательно ставить пробел, например вы можете написать -o log или -olog. Эти значения эквивалентны. Также если у опций нет параметров, не обязательно начинать каждую с дефиса, можно записать их все вместе: -drc и -d -r -c. Эти параметры wget тоже эквивалентны.
А теперь давайте перейдем к списку опций. У wget слишком много опций, мы разберем только основные.
- -V(—version) — вывести версию программы
- -h (—help) — вывести справку
- -b(—background) — работать в фоновом режиме
- -oфайл(—out-file) — указать лог файл
- -d(—debug) — включить режим отладки
- -v (—verbose) — выводить максимум информации о работе утилиты
- -q (—quiet) — выводить минимум информации о работе
- -iфайл (—input-file) — прочитать URL из файла
- —force-html — читать файл указанный в предыдущем параметре как html
- -t (—tries) — количество попыток подключения к серверу
- -O файл(—output-document) — файл в который будут сохранены полученные данные
- -с (—continue) — продолжить ранее прерванную загрузку
- -S (—server-response) — вывести ответ сервера
- —spider — проверить работоспособность URL
- -T время (—timeout) — таймаут подключения к серверу
- —limit-rate — ограничить скорость загрузки
- -w (—wait) — интервал между запросами
- -Q(—quota) — максимальный размер загрузки
- -4 (—inet4only) — использовать протокол ipv4
- -6 (—inet6only) — использовать протокол ipv6
- -U (—user-agent)— строка USER AGENT отправляемая серверу
- -r (—recursive)- рекурсивная работа утилиты
- -l (—level) — глубина при рекурсивном сканировании
- -k(—convert-links) — конвертировать ссылки в локальные при загрузке страниц
- -P (—directory-prefix) — каталог, в который будут загружаться файлы
- -m(—mirror) — скачать сайт на локальную машину
- -p(—page-requisites) — во время загрузки сайта скачивать все необходимые ресурсы
Кончено это не все ключи wget, но здесь и так слишком много теории, теперь давайте перейдем к практике. Примеры wget намного интереснее.
Использование wget Linux
Команда wget linux, обычно поставляется по умолчанию в большинстве дистрибутивов, но если нет, ее можно очень просто установить. Например установка с помощью yum будет выглядеть следующим образом:
А в дистрибутивах основанных на Debian:
Теперь перейдем непосредственно к примерам:
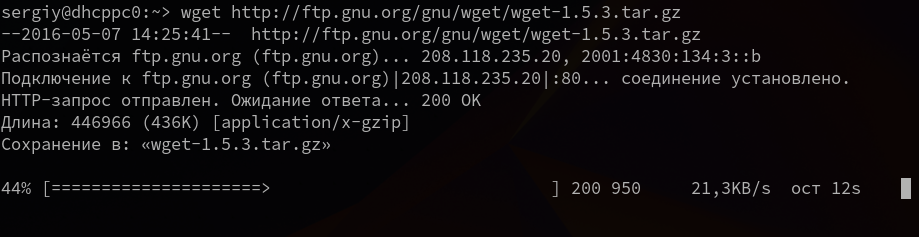
1. Загрузка файла
Команда wget linux скачает один файл и сохранит его в текущей директории. Во время загрузки мы увидим прогресс, размер файла, дату его последнего изменения, а также скорость загрузки:
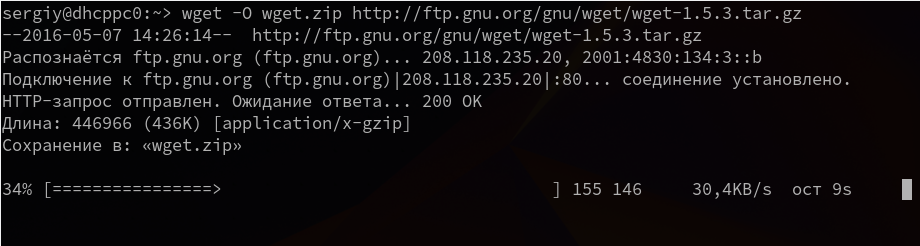
2. Сохранить файл с другим именем
Опция -О позволяет задать имя сохраняемому файлу, например, скачать файл wget с именем wget.zip:
wget -O wget.zip http://ftp.gnu.org/gnu/wget/wget-1.5.3.tar.gz
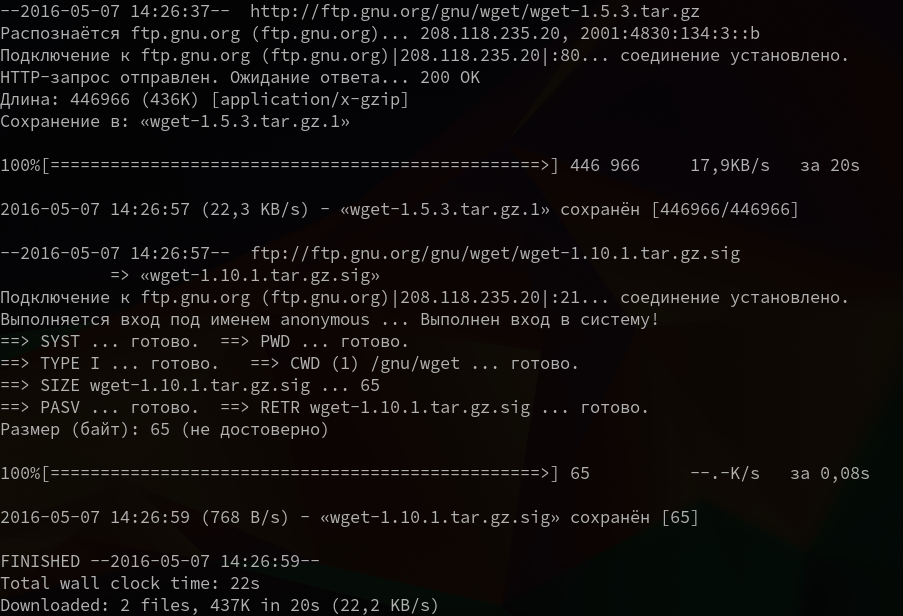
3. Скачать несколько файлов
Вы можете скачать несколько файлов одной командой даже по разным протоколам, просто указав их URL:
wget http://ftp.gnu.org/gnu/wget/wget-1.5.3.tar.gz ftp://ftp.gnu.org/gnu/wget/wget-1.10.1.tar.gz.sig
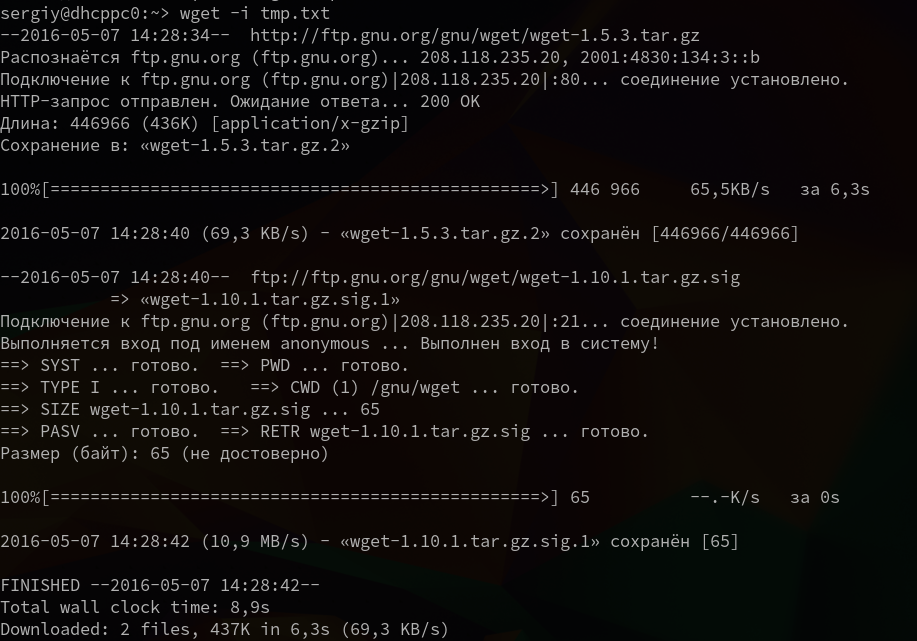
4. Взять URL из файла
Вы можете сохранить несколько URL в файл, а затем загрузить их все, передав файл опции -i. Например создадим файл tmp.txt, со ссылками для загрузки wget, а затем скачаем его:
5. Продолжить загрузку
Утилита wget linux рассчитана на работу в медленных и нестабильных сетях. Поэтому если вы загружали большой файл, и во время загрузки было потеряно соединение, то вы можете скачать файл wget с помощью опции -c.
wget -c http://ftp.gnu.org/gnu/wget/wget-1.5.3.tar.gz
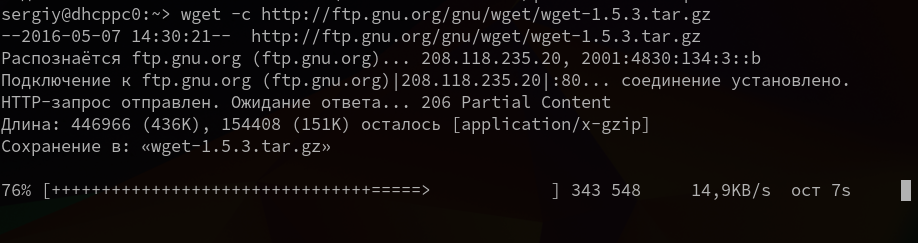
6. Загрузка файлов в фоне
Опция -b заставляет программу работать в фоновом режиме, весь вывод будет записан в лог файл, для настройки лог файла используются специальные ключи wget:
wget -b -o ~/wget.log http://ftp.gnu.org/gnu/wget/wget-1.5.3.tar.gz

7. Ограничение скорости загрузки
Команда wget linux позволяет не только продолжать загрузку файлов, но и ограничивать скорость загрузки. Для этого есть опция —limit-rate. Например ограничим скорость до 100 килобит:
wget —limit-rate=100k ftp://ftp.iinet.net.au/debian/debian-cd/8.4.0/amd64/iso-dvd/debian-8.4.0-amd64-DVD-1.iso
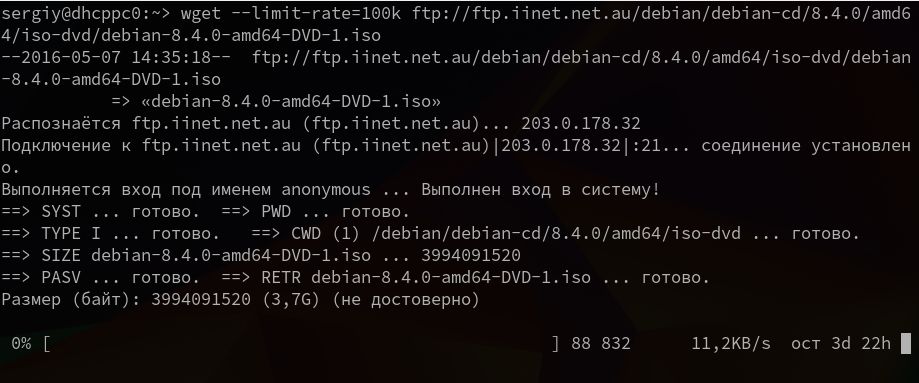
Здесь доступны, как и в других подобных командах индексы для указания скорости — k — килобит, m — мегабит, g — гигабит, и так далее.
8. Подключение по логину и паролю
Некоторые ресурсы требуют аутентификации, для загрузки их файлов. С помощью опций —http-user=username, –http-password=password и —ftp-user=username, —ftp-password=password вы можете задать имя пользователя и пароль для HTTP или FTP ресурсов.
wget —http-user=narad —http-password=password http://mirrors.hns.net.in/centos/6.3/isos/x86_64/CentOS-6.3-x86_64-LiveDVD.iso
wget —ftp-user=narad —ftp-password=password ftp://ftp.iinet.net.au/debian/debian-cd/6.0.5/i386/iso-dvd/debian-6.0.5-i386-DVD-1.iso
9. Загрузить и выполнить
Вы, наверное, уже видели такие команды. wget позволяет сразу же выполнять скачанные скрипты:
wget -O — http://сайт/скрипт.sh | bash
Если опции -O не передать аргументов, то скачанный файл будет выведен в стандартный вывод, затем мы его можем перенаправить с интерпретатор bash, как показано выше.
10. Сохранить файл в папке
По умолчанию wget сохраняет файл в текущую папку, но это поведение очень легко изменить с помощью опции -P:
wget -P ~/Downloads/ http://ftp.gnu.org/gnu/wget/wget-1.5.3.tar.gz
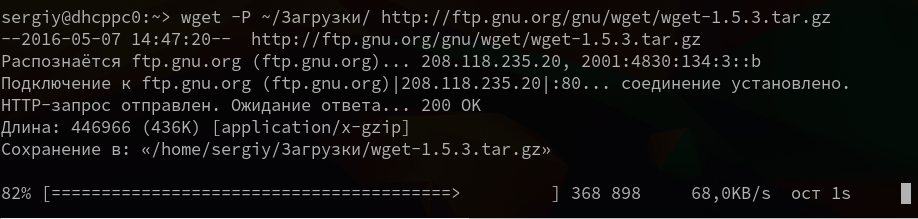
11. Передать информацию о браузере
Некоторые сайты фильтруют ботов, но мы можем передать фальшивую информацию о нашем браузере (user-agent) и страницу с которой мы пришли (http-referer).
wget ‐‐refer=http://google.com ‐‐user-agent=”Mozilla/5.0 Firefox/4.0.1″ //losst.pro
12. Количество попыток загрузки
По умолчанию wget пытается повторить загрузку 20 раз, перед тем как завершить работу с ошибкой. Количество раз можно изменить с помощью опции —tries:
wget —tries=75 http://mirror.nbrc.ac.in/centos/7.0.1406/isos/x86_64/CentOS-7.0-1406-x86_64-DVD.iso
13. Квота загрузки
Если вам доступно только ограниченное количество трафика, вы можете указать утилите, какое количество информации можно скачивать, например разрешим скачать файлов из списка только на десять мегабайт:
wget -Q10m -i download-list.txt
Здесь работают те же индексы для указания размера — k, m, g, и т д.
14. Скачать сайт
Wget позволяет не только скачивать одиночные файлы, но и целые сайты, чтобы вы могли их потом просматривать в офлайне. Использование wget, чтобы скачать сайт в linux выглядит вот так:
wget —mirror -p —convert-links -P ./ аддресс_сайт
Выводы
Вот и все, теперь использование wget не будет для вас таким непонятным. Если я упустил что-то важное о команде или у вас остались вопросы, спрашивайте в комментариях!
Обнаружили ошибку в тексте? Сообщите мне об этом. Выделите текст с ошибкой и нажмите Ctrl+Enter.
How to specify the download location with wget?
There’s a good chance people may want to use -x if they are using -i or —input-files , to force it to download to the corresponding local directory that matches each URL pattern.
5 Answers 5
-P prefix --directory-prefix=prefix Set directory prefix to prefix. The directory prefix is the directory where all other files and sub-directories will be saved to, i.e. the top of the retrieval tree. The default is . (the current directory). So you need to add -P /tmp/cron_test/ (short form) or —directory-prefix=/tmp/cron_test/ (long form) to your command. Also note that if the directory does not exist it will get created.
-P /tmp/cron_test/ doesnt work but removing / like -P tmp/cron_test/ works and even creates nonexisting directory.
The manual’s description makes this option hard to search for. I don’t think of the location where I want to save something as a ‘directory prefix’. Thanks for sharing!
Also, you can remove the root folder via —no-host-directories or -nH as per serverfault.com/questions/354792/…
Well, -P option isn’t working to me (on 18.04), at least not with -O option. Is there some other detail I need to pay attention?
-O is the option to specify the path of the file you want to download to:
-P is prefix where it will download the file in the directory:
Up voted for also specifying -O which I did not need, but made me feel more confident that -P was what I needed.
@louisMaddox per the man pages on my machine, the default prefix is «.» (i.e., the current directory) adding a trailing slash to «directory prefix» would cause a double slash error (i.e., my/favorite/dir/prefix//) furthermore, considering the semantics, «directory prefix» would not require a trailing slash.
NB: -O overrides -P , so you can’t specify just output directory (think dirname and just output filename (think basename ). For this use just -O specifying full file path.
Make sure you have the URL correct for whatever you are downloading. First of all, URLs with characters like ? and such cannot be parsed and resolved. This will confuse the cmd line and accept any characters that aren’t resolved into the source URL name as the file name you are downloading into.
wget "sourceforge.net/projects/ebosse/files/latest/download?source=typ_redirect" will download into a file named, ?source=typ_redirect .
As you can see, knowing a thing or two about URLs helps to understand wget .
I am booting from a hirens disk and only had Linux 2.6.1 as a resource (import os is unavailable). The correct syntax that solved my problem downloading an ISO onto the physical hard drive was:
wget "(source url)" -O (directory where HD was mounted)/isofile.iso" One could figure the correct URL by finding at what point wget downloads into a file named index.html (the default file), and has the correct size/other attributes of the file you need shown by the following command:
Once that URL and source file is correct and it is downloading into index.html , you can stop the download ( ctrl + z ) and change the output file by using:
In my case this results in downloading an ISO and storing it as a binary file under isofile.iso , which hopefully mounts.
«-P» is the right option, please read on for more related information:
wget -nd -np -P /dest/dir —recursive http://url/dir1/dir2
Relevant snippets from man pages for convenience:
-P prefix --directory-prefix=prefix Set directory prefix to prefix. The directory prefix is the directory where all other files and subdirectories will be saved to, i.e. the top of the retrieval tree. The default is . (the current directory). -nd --no-directories Do not create a hierarchy of directories when retrieving recursively. With this option turned on, all files will get saved to the current directory, without clobbering (if a name shows up more than once, the filenames will get extensions .n). -np --no-parent Do not ever ascend to the parent directory when retrieving recursively. This is a useful option, since it guarantees that only the files below a certain hierarchy will be downloaded.