- Как скачать МНОГО файлов с Google Drive через wget
- Скрипты
- dl.sh
- multiple-to-single.sh
- check.sh
- Файлы со ссылками
- cookie
- Запуск
- Проверка и докачка
- Как бэкапить из Linux на Яндекс.Диск
- Yegorov / ya.py
- Footer
- Установка и настройка программы
- Мастер начальной настройки
- Восстановить Диск
- Загрузить архив с Я.Диска на сервер
Как скачать МНОГО файлов с Google Drive через wget
При скачивании большого количества файлов обычным способом гугл блокирует примерно через 50 файлов, даже если скачивать по одному файлу в 10 секунд (начинает отдавать 403 — «вы робот»).
Чтобы «обмануть» его, нужно подсунуть свои куки из браузера для wget’а. Полагаю, что лимит в 50 файлов — это только для анонимусов, а для авторизованных пользователей он больше.
Итак, допустим, у нас есть набор ссылок:
И надо сказать, что далее предполагается, что все это — картинки jpeg, и скрипты рассчитаны именно на это.
Скрипты
Сначала создаём папку, в которую мы будем скачивать файлы, и кладем в неё скрипты:
dl.sh
#!/usr/bin/env bash tr "=" " " | while read link id ; do # trim $id" | sed 's/^\s*// ; s/\s*$//'`" [ -z "$id" ] && < echo " !! Empty line: $link $id" continue >echo "$id" | grep "[^a-zA-Z0-9_-]" && < echo " !! Wrong id: $id" continue >file="$id.jpg" echo $id [ -f $file ] && < echo " Already exists" continue >echo "Downloading" wget --load-cookies cookies.txt --no-check-certificate "https://docs.google.com/uc?export=download&id=$id" -O $id.jpg || < echo "ERROR" echo "Waiting for 10 minutes" date sleep 600 >echo "ok" sleep 10 done multiple-to-single.sh
#!/usr/bin/env bash # переводит строку с несколькими ссылками, разделенными точкой с запятой, вида: # https://. /1.jpg ; https://. /2.jpg ; https://. /3.jpg # в отдельные строки: # https://. /1.jpg # https://. /2.jpg # https://. /3.jpg # пустые строки и лишние пробелы отбрасываются tr ";" "\n" | while read link ; do # sed is for trim echo "$link" | sed 's/^\s*// ; s/\s*$//' done | grep -v "^$" check.sh
#!/usr/bin/env bash find ./ -size 0 for i in *.jpg ; do file "$i" done | grep -v 'JPEG image' Файлы со ссылками
Теперь готовим файл со списком ссылок.
- Либо каждая ссылка идет на одной строке.
- Либо в одной строке несколько ссылок, разделенных запятыми:
https://drive.google.com/open?id=1eoWI7aANlCcZaA4CBIkoCL2T9QdMYGRw ; https://drive.google.com/open?id=18UAqItpNmBQ1JqSSCC3TS7j6DVzSJ-mm ; https://drive.google.com/open?id=12K_Y-I9Z9pEsFyDrgJfG-H0zgDEmI-1W Размещаем этот файл рядом с dl.sh .
cookie
Нужно подготовить файл cookies.txt для wget, чтобы гугл не считал его анонимусом.
- Устанавливаем в chrome расширение cookies.txt
- Заходим на любую из ссылок, которую мы хотим скачать.
- С помощью расширения копируем все куки и сохраняем их в файл cookies.txt рядом со скриптом dl.sh .
Запуск
Для скачивания нужно запустить (допустим, ссылки у нас лежат в links.txt ):
cat links.txt | ./multiple-to-single.sh | ./dl.sh Запускаем в tmux, ждем пока все скачается.
Проверка и докачка
При скачивании некоторых ссылок может произойти ошибка и файл скачается не тот или битый.
После того как все файлы скачаются, запускаем проверку:
Если он что-то выведет, то это файлы, которые скачались криво. Их нужно удалить и повторно запустить скачивание.
Когда скачивание про все файлы будет говорить «Already exists», а проверка не выдает ничего, значит — готово.
Как бэкапить из Linux на Яндекс.Диск
У Яндекс.Диска существует полнофункциональный linux-клиент, который может работать без GUI. Соответственно, его можно подключить, например, к серверу на Ubuntu и бэкапить на него сайт или любые другие файлы. Единственный существенный минус — нет функционала разграничения доступа к директориям внутри Яндекс.Диска — при бэкапе с разных машин каждая из них будет видеть всё содержимое.
Авторизуемся в системе и создадим директорию, к которой подключим Я.Диск (в примере — /root/backup)
Скачиваем и устанавливаем deb-пакет:
wget https://repo.yandex.ru/yandex-disk/yandex-disk_latest_amd64.deb dpkg -i yandex-disk_latest_amd64.debПосле установки запускаем настройку:
root@ubuntu-test:~# yandex-disk setup Would you like to use a proxy server? [y/N]: n Log in If you don't have a Yandex account yet, get one at https://passport.yandex.com/passport?mode=register Go to the page https://ya.ru/device and enter the code ‘a01bcdef’ within 300 seconds. Make sure you're logged in to the browser with the right account.Token saved to /root/.config/yandex-disk/passwdУстановщик просит открыть браузер, авторизоваться под учетной записью, Я.Диск которой будет подключен и перейти по ссылке https://ya.ru/device.

Запрашиваемый код можно взять в консоли (в примере выше — a01bcdef). Ввести его нужно в течение 5 минут. Теперь подтвердждаем авторизацию устройства:
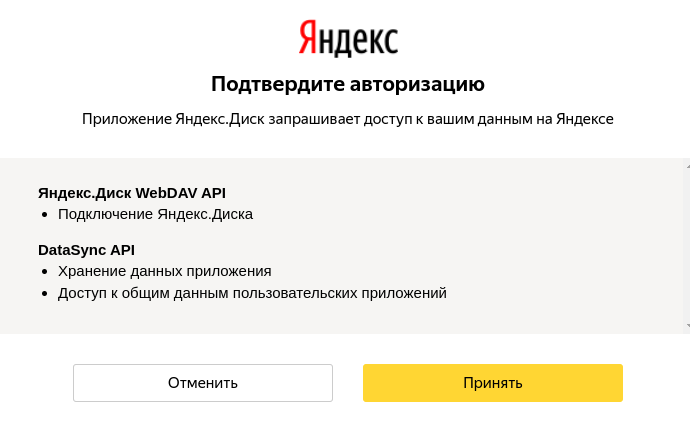
Если всё ок — появится сообщение:

После этого возвращаемся в консоль и вводим оставшиеся настройки — директорию, к которой будет подключен Яндекс.Диск и автозапуск:
Configure Yandex.Disk Enter path to Yandex.Disk folder (Leave empty to use default folder '/root/Yandex.Disk'): /root/backup Would you like Yandex.Disk to launch on startup? [Y/n]: y Starting daemon process. DoneНастройка завершена, диск подключен к серверу Linux.
Теперь можно настроить резервное копирование сайта на Яндекс.Диск.
Yegorov / ya.py
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
| #!/usr/bin/env python3 |
| # -*- coding: utf-8 -*- |
| # https://toster.ru/q/72866 |
| # How to |
| # wget http://gist.github.com/. |
| # chmod +x ya.py |
| # ./ya.py download_url path/to/directory |
| import os , sys , json |
| import urllib . parse as ul |
| sys . argv . append ( ‘.’ ) if len ( sys . argv ) == 2 else None |
| base_url = ‘https://cloud-api.yandex.net:443/v1/disk/public/resources/download?public_key=’ |
| url = ul . quote_plus ( sys . argv [ 1 ]) |
| folder = sys . argv [ 2 ] |
| res = os . popen ( ‘wget -qO — <><>‘ . format ( base_url , url )). read () |
| json_res = json . loads ( res ) |
| filename = ul . parse_qs ( ul . urlparse ( json_res [ ‘href’ ]). query )[ ‘filename’ ][ 0 ] |
| os . system ( «wget ‘<>‘ -P ‘<>‘ -O ‘<>‘» . format ( json_res [ ‘href’ ], folder , filename )) |
| # os.system(«wget ‘<>‘».format(json_res[‘href’])) |
wget https://gist.githubusercontent.com/Yegorov/dc61c42aa4e89e139cd8248f59af6b3e/raw/20ac954e202fe6a038c2b4bb476703c02fe0df87/ya.py chmod +x ya.py ./ya.py download_url path/to/directory # or python ya.py download_url path/to/directory is it possible to add recursive downloading?
im trying to download and get this:
HTTP request sent, awaiting response. 507 Insufficient Storage 2019-01-02 16:32:18 ERROR 507: Insufficient Storage. it looks like it asks to townload zip file.
Thanks for this script! It works for me while this one is not working https://github.com/Yegorov/yadisk
Footer
You can’t perform that action at this time.
Установка и настройка программы
Чтобы установить клиент автоматически, воспользуйтесь командой быстрой установки пакета.
Пример быстрой установки пакета
echo "deb http://repo.yandex.ru/yandex-disk/deb/ stable main" | sudo tee -a /etc/apt/sources.list.d/yandex-disk.list > /dev/null && wget http://repo.yandex.ru/yandex-disk/YANDEX-DISK-KEY.GPG -O- | sudo apt-key add - && sudo apt-get update && sudo apt-get install -y yandex-diskЧтобы установить клиент вручную, скачайте нужную версию пакета по соответствующей ссылке ниже.
# dpkg -i yandex-disk_0.1.0.103_i386.debПримечание. Репозиторий автоматически устанавливается по адресу /etc/apt/sources.list.d/yandex-disk.list
# rpm -ivh yandex-disk-0.1.0.103-1.fedora.i386.rpmВы также можете добавить репозиторий с пакетом yandex-disk в список доступных репозиториев менеджера пакетов и установить пакет с помощью утилиты apt-get или yum .
Установка с помощью apt-get
Внимание. Сохраните копию файла /etc/apt/sources.list.d/yandex-disk.list перед внесением в него изменений.
# wget -O YANDEX-DISK-KEY.GPG http://repo.yandex.ru/yandex-disk/YANDEX-DISK-KEY.GPG\n# apt-key add YANDEX-DISK-KEY.GPG\n# echo "deb http://repo.yandex.ru/yandex-disk/deb/ stable main" >> /etc/apt/sources.list.d/yandex-disk.list\n# apt-get update\n# apt-get install yandex-disk# nano /etc/yum.repos.d/yandex.repo\n# rpm --import http://repo.yandex.ru/yandex-disk/YANDEX-DISK-KEY.GPG\n# yum install yandex-diskСодержимое файла yandex.repo :
[yandex]\nname=Yandex\nfailovermethod=priority\nbaseurl=http://repo.yandex.ru/yandex-disk/rpm/stable/$basearch/\nenabled=1\nmetadata_expire=1d\ngpgcheck=1\ngpgkey=http://repo.yandex.ru/yandex-disk/YANDEX-DISK-KEY.GPGМастер начальной настройки
Вы можете выполнить начальную настройку клиента с помощью команды setup :
Введите название каталога для хранения локальной копии Диска. Если вы оставите название пустым, в домашнем каталоге будет создана папка Yandex.Disk .
После того как мастер завершит работу, в каталоге ~/.config/yandex-disk будет создан файл конфигурации config.cfg.
# Путь к файлу с данными авторизации\nauth="/home/user/.config/yandex-disk/passwd"\n\n# Каталог для хранения локальной копии Диска.\ndir="/home/user/myDisk"\n\n# Не синхронизировать указанные каталоги.\n#exclude-dirs="exclude/dir1,exclude/dir2,path/to/another/exclude/dir"\n\n# Указать прокси-сервер. Примеры:\n#proxy=https,127.0.0.1,80\n#proxy=https,127.0.0.1,80,login,password\n#proxy=https,127.0.0.1,443\n#proxy=socks4,my.proxy.local,1080,login,password\n#proxy=socks5,my.another.proxy.local,1081\n#proxy=auto\n#proxy=noВосстановить Диск
Чтобы восстановить Диск после переустановки операционной системы, смены жёсткого диска или удаления программы:
Выполните настройку клиента. Если на вашем компьютере остались старые файлы Диска, они автоматически синхронизируются с сервером.
Загрузить архив с Я.Диска на сервер
Здравствуйте. Подскажите пожалуйста есть ли возможность загружать файлы с Яндекс Диска на сервер напрямую. Использовал команды scp и wget. Первой не выходит. Второй загружает в папку файл с именем окончательной части урла выдаваемой сервисом публичной ссылки типа ljfouqhqoyulj и в нем содержится куча какого-то html кода с урлами яндекса. Может есть другой способ?
Реальный облачный майнинг (https://goo.gl/FWzPQQ) окупаемость 7 мес. Здесь (http://goo.gl/Sm0llJ) бесперебойный VPS: 1Gb, 1xCPU, 20Gb SSD, безлимит за 250 руб./мес.
Диск=>ПК=>Сервер через FTP Напрямую вряд ли получится. Разве что качаете на комп через браузер и во время скачки, пока она еще не закончилась смотрите в загрузках видно полный путь скачиваемого файла. За то время пока качается нужно wget ом начать качать по этой ссылке на сервер. Возможно звучит сложно, но ничего сложного и как более понятно обьяснить не знаю.
⭐ BotGuard (https://botguard.net) ⭐ — защита вашего сайта от вредоносных ботов, воровства контента, клонирования, спама и хакерских атак!
smart2web:
Диск=>ПК=>Сервер через FTP
Напрямую вряд ли получится. Разве что качаете на комп через браузер и во время скачки, пока она еще не закончилась смотрите в загрузках видно полный путь скачиваемого файла. За то время пока качается нужно wget ом начать качать по этой ссылке на сервер.
Возможно звучит сложно, но ничего сложного и как более понятно обьяснить не знаю.
Нет, все понятно, я уже сам стал подумывать что надо найти способы выуживания прямой ссылки. Надо попробовать.
Вы имеете ввиду синхронизацию сервера и я.диска? Я это сделал. Вопрос стоит теперь как с диска загруженный туда бекап закачать на новый сервер и развернуть его на нем. Еще есть идея синхронизировать папки бекапов обоих серверов с одним аккаунтом ядиска, возможно на новом сервере появится после синхронизации копии бекапов старого и их там уже разворачивать, а потом отключать от ядиска старый сервер?
smart2web, а как определить прямой урл к файлу, я там увидел только название файла, а дальше везде абракадабра