- I/O Waiting CPU Time – ‘wa’ in Top
- What Is ‘Waiting’ CPU Time?
- How to Find ‘Waiting’ CPU Time?
- How to Simulate a High ‘Waiting’ CPU Time?
- Evaluating the CPU I/O wait on Linux
- What is iowait and how does it affect Linux performance?
- What is I/O wait?
- “iowait shows the percentage of time that the CPU or CPUs were idle during which the system had an outstanding disk I/O request.” – iostat man page.
- I/O wait and Linux server performance
- Monitoring and reducing I/O wait related issues
- Conclusion
I/O Waiting CPU Time – ‘wa’ in Top
Join the DZone community and get the full member experience.
CPU consumption in Unix/Linux operating systems is broken down into 8 different metrics: User CPU time, System CPU time, nice CPU time, Idle CPU time, Waiting CPU time, Hardware Interrupt CPU time, Software Interrupt CPU time, and Stolen CPU time. In this article, let us study ‘waiting CPU time’.
What Is ‘Waiting’ CPU Time?
Waiting CPU time indicates the amount of time the CPU spends waiting for disk I/O or network I/O operations to complete. A high waiting time indicates that the CPU is *stranded* because of the I/O operations on that device. For optimal performance, one should aim to keep the I/O waiting CPU time as low as possible. If waiting time is > 10%, then it is worth investigating it.
You can visualize I/O waiting time through this analogy: Say there are hundreds of cars/bikes that are waiting on a busy road for the traffic light to switch from ‘red’ to ‘green’. But due to some technical glitch, it takes a long time for the traffic light to switch from ‘red’ to ‘green’ – then those hundreds of cars/bikes would get stranded unnecessarily. It will result in several undesirable side effects: passengers will reach their destination late, drivers can get frustrated and start to honk the horn (noise pollution), and fuel will be wasted (air pollution).
How to Find ‘Waiting’ CPU Time?
Waiting CPU time can be found from the following sources:
a. You can use web-based root cause analysis tools to report ‘waiting’ CPU time. The tool is capable of generating alerts if ‘waiting’ CPU time goes beyond a threshold.
b. ‘Waiting’ CPU time is also reported in the Unix/Linux command line tool ‘top’ in the field ‘wa’ as highlighted in the image below.

Fig: ‘wa’ time in top
How to Simulate a High ‘Waiting’ CPU Time?
To simulate high ‘waiting’ CPU reporting, let’s use BuggyApp. BuggyApp is an open-source Java project that can simulate various performance problems. When you launch BuggyApp with the following arguments, it will cause the ‘waiting’ CPU consumption to spike on the host.
Evaluating the CPU I/O wait on Linux
You need to be careful when evaluating these figures.
- IOWait is related, but not necessarily linearly correlated with disk activity.
- The number of CPUs you have affects your percentage.
- A high IOWait (depending on your application) does not necessarily indicate a problem for you. Alternatively a small IOWait may translate into a problem for you. It basically boils down to what task is waiting.
IOWait in this context is the measure of time over a given period that a CPU (or all CPUS) spent idle because all runnable tasks were waiting for a IO operation to be fulfilled.
In your example, if you have 20 CPUs, with one task really hammering the disk, this task is (in effect) spending 100% of its time in IOWait, subsequently the CPU that this task runs on spends almost 100% of its time in IOWait. However, if 19 other CPUs are effectively idle and not utilizing this disk, they report 0% IOWait. This results in an averaged IOWait percentage of 5%, when in fact if you were to peek at your disk utilization this could report 100%. If the application waiting on disk is critical to you — this 5% is somewhat misleading because the task in the bottleneck is seeing likely much higher performance issues than going 5% slow.
there are almost as many CPU processes waiting than working? (=> bad)
Probably, remember for the most part CPUs run tasks and tasks are what request IO. If two separate tasks are busy querying the same disk on two separate CPUs, this will put both CPUs at 100% IOWait (and in the 20 CPU example a 10% overall average IOWait).
Basically if you have a lot of tasks that request IO, especially from the same disk, plus that disk is 100% utilized (see iostat -mtx ) then this is bad.
the working processeses are waiting 5,0% of their execution plan? (=> ok in this case)
No. The working processes are almost certainly waiting full-time for IO. It’s just the average report case («the other CPUs are not busy») fudges the percentage or the fact that the CPU has many tasks to run, of which many don’t need to do IO.
As a general rule, on a multi-CPU system, an IOWait percentage which is equal to the number of CPUs you have divided by a 100 is probably something to investigate.
See above. But note that applications that do very heavy writing are throttled (stop using writeback, start writing directly to disk). This causes those tasks to produce high IOWait whilst other tasks on the same CPU writing to the same disk would not. So exceptions do exist.
Also note if you have 1 CPU dedicated to running 2 tasks, one is a heavy IO read/writer and the other is a heavy CPU user, then the CPU will report 50% IOWait in this case, if you have 10 tasks like this it would be 10% IOWait (and a horrific load), so the number can be reported much lower than what might actually be a problem.
I think you really need to take a look at iostat -mtx to get some disk utilization metrics, and pidstat -d to get some per-process metrics, then consider whether or not the applications hitting those disks in that way are likely to cause a problem, or other potential applications that hit those disks being likely to cause a problem.
CPU metrics really act as indicators to underlying issues, they are general so understanding where they may be too general is a good thing.
What is iowait and how does it affect Linux performance?
I/O wait or iowait , wait , wa , %iowait , or wait% is often displayed by command-line Linux system monitoring tools such as top, sar, atop, and others. On its own, it’s one of many performance stats that provide us insight into Linux system performance.
I/O wait came up in a recent discussion with a new client. During our support call, they reported load spikes of 60 to 80 on their 32 CPU core system. This resulted in slow page loading, timeouts, and intermittent outages. The cause? Storage I/O bottleneck was initially hinted at by a consistently high iowait and later confirmed with additional investigation.
What is I/O wait? How does I/O wait affect Linux server performance? How can we monitor and reduce I/O wait related issues? Continue reading for the answers to these questions.
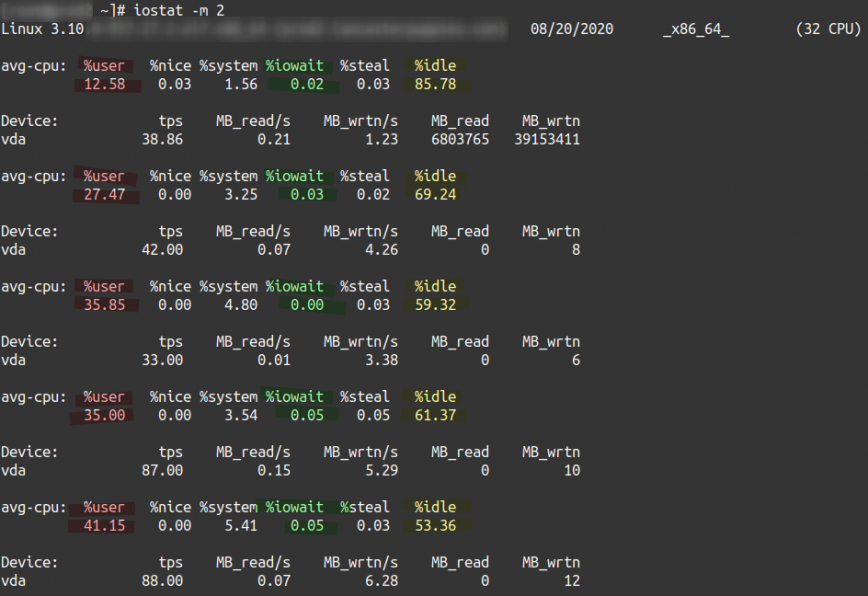
What is I/O wait?
I/O wait applies to Unix and all Unix-based systems, including macOS, FreeBSD, Solaris, and Linux.
I/O wait (iowait) is the percentage of time that the CPU (or CPUs) were idle during which the system had pending disk I/O requests. (Source: man sar ) The top man page gives this simple explanation: “I/O wait = time waiting for I/O completion.” In other words, the presence of I/O wait tells us that the system is idle when it could be processing outstanding requests.
“iowait shows the percentage of time that the CPU or CPUs were idle during which the system had an outstanding disk I/O request.” – iostat man page.
When using Linux top and other tools, you’ll notice that a CPU (and its cores) operate in the following states: us (user), sy (system), id (idle), ni (nice), si (software interrupts), hi (hardware interrupts), st (steal) and wa (wait). Of these, the user, system, idle, and wait values should add up to 100%. Note that “idle” and “wait” are not the same. “Idle” CPU means there is no workload present while, on the other hand, “wait” (iowait) indicates when the CPU is waiting in an idle state for outstanding requests.
If the CPU is idle, the kernel will ascertain any pending I/O requests (i.e., SSD or NFS) originating from the CPU. If there are, then the ‘iowait’ counter is incremented. If nothing is pending, then the ‘idle’ counter is incremented.
I/O wait and Linux server performance
It’s important to note that iowait can, at times, indicate a bottleneck in throughput, while at other times, iowait may be completely meaningless. It’s possible to have a healthy system with high iowait, but also possible to have a bottlenecked system without iowait.
I/O wait is simply one of the indicated states of your CPU / CPU cores. A high iowait means your CPU is waiting on requests, but you’ll need to investigate further to confirm the source and effect.
For example, server storage (SSD, NVMe, NFS, etc.) is almost always slower than CPU performance. Because of this, I/O wait may be misleading, especially when it comes to random read/write workloads. This is because iowait only measures CPU performance, not storage I/O.
Although iowait indicates that the CPU can handle more workload, depending on your server’s workload and how load performs computations or makes use of storage I/O, it isn’t always possible to solve I/O wait. Or not feasible to achieve a near-zero value.
Based on end-user experience, database query health, transaction throughput, and overall application health, you will have to decide whether or not the iowait reported indicates poor Linux system performance.
For example, if you see a low iowait of 1 to 4 percent, and you then upgrade the CPU to 2x the performance, the iowait will also increase. A 2x faster CPU with the same storage performance = ~ 2x the wait. You’ll want to consider your workload to determine which hardware you should pay attention to first.
Monitoring and reducing I/O wait related issues
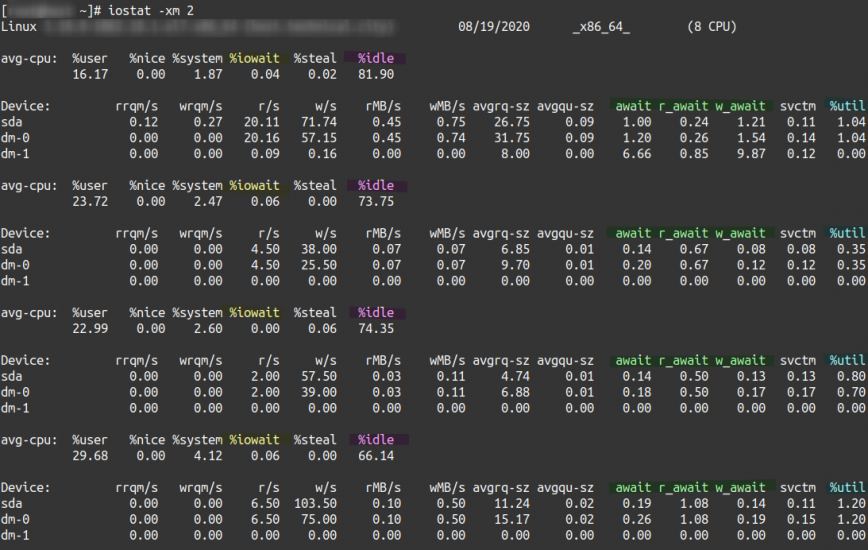
Let’s look at some valuable tools used to monitor I/O wait on Linux.
- atop – run it with -d option or press d to toggle the disk stats view.
- iostat – try it with the -xm 2 options for extended statistics, in megabytes and in two-second intervals.
- iotop – top-like I/O monitor. Try it with the -oPa options to show the accumulated I/O of active processes only.
- ps – use auxf , then under the “STAT” column “D” usually indicates disk iowait.
- strace – view the actual operations issued by a process. Read the strace man page.
- lsof – after you’ve identified the process responsible, use -p [PID] to find the specific files.
Reducing I/O wait related issues
Take the following steps to reduce I/O wait related issues.
- Optimize your application’s code and database queries. This can go a long way in reducing the frequency of disk reads/writes. This should be your first approach because the more efficient your application is, the less you’ll have to spend on hardware long-term. See also: 100 Application Performance Monitoring (APM) & Observability Solutions.
- Keep your Linux system and software versions up-to-date. Not only is this better for security, but more often than not, the latest supported versions offer notable performance improvements, whether it’s Nginx, Node.js, PHP, Python, or MySQL.
- Make sure that you have free memory available. Enough free memory so that around half of the server’s memory is being used for in-memory buffers and cache, rather than swapping and paging to disk. Of course, this ratio will differ case by case. Therefore, be sure you are not swapping and kernel cache pressure isn’t high due to a lack of free memory.
- Tweak your system, storage device(s), and the Linux kernel for increased storage performance and lifespan.
- Finally, if all else fails: upgrade storage devices to faster SSD, NVMe, or other high throughput storage devices.
Conclusion
The iowait statistic is a helpful performance stat for monitoring CPU utilization health. It notifies the Sysadmin when the CPU is idle and can perform more computations. We can then use observability, benchmarking, and tracing tools such as those listed above to put together a complete picture of the system’s overall I/O performance. Your main goal should be to eliminate any iowait directly resulting from waiting on disk, NFS, or other storage-related I/O.
Published: Aug 19th, 2020 | Last updated: Jan 28th, 2022.