- Как узнать загрузку процессора и памяти в Linux — команда vmstat
- Как нужно оценивать производительность?
- Синтаксис команды vmstat
- Опции vmstat
- Примеры использования vmstat
- Заключение
- Похожие записи:
- Загрузка процессора Linux
- Как посмотреть загрузку процессора в Linux
- 1. Утилита htop
- 2. Файл /proc/loadavg
- 3. Утилита mpstat
- 4. Команда nmon
- 5. CoreFreq
- Выводы
Как узнать загрузку процессора и памяти в Linux — команда vmstat
Производительность (или непроизводительность) систем очень сложно оценивать «на глаз» или даже с секундомером. Ведь даже если это и получится, то из виду будут упущены ключевые детали, предоставляющие информацию о том, почему производительность может быть именно такой, а не больше (или меньше). Для выяснения причин стоит углубиться в анализ этой самой производительности более основательно. И для этих целей существуют специализированные утилиты, одной из которых является vmstat – довольно популярный инструмент (после команды top разве что), которым пользуются многие системные администраторы Linux.
Как нужно оценивать производительность?
Вообще, производительность и/или быстродействие — величины постоянные только для конкретного (и довольно короткого) промежутка времени для конкретной системы. Для более объективной оценки необходимо проводить многочисленные «замеры» в разное время в течении довольно длительного (месяц и более) периода.
Немаловажно и то, что анализ следует проводить без использования всевозможных «синтетических» тестов — т. е. только в условиях реальной и пиковой нагрузки, возникающей во время реальный задач, предусмотренных техпроцессом, регламентом в рамках реальной «производственной» необходимости. Очень часто именно в таких условиях можно выявить ошибки в конфигурации системы, приводящие к ограничениям в использовании программно-аппаратных ресурсов.
Синтаксис команды vmstat
Утилитой vmstat можно анализировать не только использование процессора, но также память — оперативную и/или дисковую. Синтаксис команды следующий:
vmstat [options] [delay [count]]
Основными аргументами являются delay – время (в секундах), в течение которого следует производить замер, а также count – количество замеров или отчётов. Если дать команду vmstat без указания количества замеров, то она будет выводить отчёты, пока не будет прервано её выполнение сочетанием клавиш .
Вывод vmstat разбит на столбцы, которые объединены в следующие категории:
- procs – информация о процессах;
- memory – состояние оперативной памяти;
- swap – состояние виртуальной памяти (раздел или файл подкачки);
- io – активность устройств хранения (диски, флешки и т. д.);
- system – общая активность системы;
- cpu – использование центрального процессора.
Как уже было отмечено выше, эти категории объединяют колонки из вывода vmstat по соответствующему типу информации. Стоит рассмотреть их по отдельности. Для раздела procs:
- r – количество процессов в обрабатываемой процессором очереди;
- b – количество процессов, стоящих в очереди на выполнение операций ввода/вывода.
- free – размер свободной памяти. То же значение, которое определяется командой free;
- swpd – количество блоков, которые были перемещены в Swap;
- buff – буферы памяти;
- cache – кеш памяти.
- si – общее количество блоков, считываемых системой из Swap;
- so – общее количество блоков, перемещаемых системой в Swap.
- bi – количество блоков в секунду, считываемых с диска;
- bo – количество блоков в секунду, записанных на диск.
- in – частота (количество в секунду) системных прерываний;
- cs – частота переключений между задачами.
- us – используемое (в процентах) время для выполнения «пользовательских» (т. е. не принадлежащих ядру) задач;
- sy — используемое (в процентах) время для выполнения задач ядра;
- id – время (в процентах) в простое;
- wa — время (в процентах), отведённое на ожидание операций ввода/вывода.
Опции vmstat
Доступные для vmstat опции приведены в следующей таблице:
| Опция | Назначение |
| -a, — active | Выводит активную и неактивную память. Доступно начиная с ядра версии 2.5.41 и выше. |
| -f, — forks | Выводит количество системных вызовов fork, vfork и rfork, а также страниц виртуальной памяти, используемых этими вызовами. |
| -m, — slabs | Количество используемой динамической памяти для ядра. |
| -n, —one-header | Отображает заголовок таблицы результатов только один раз, а не периодически. |
| -s, — stats | Переключение режима отображения вывода. |
| -d, — disk | Выводит статистику использования диска. |
| -w | Для больших объёмов данных увеличивает визуально ширину столбцов. |
| -p, — partition device | Выводит статистику использования раздела. Необходимо указывать раздел device. |
| -S, —unit character | Выводит статистику в указанных единицах [k, K, m, M] – в килобитах, килобайтах, мегабитах и мегабайтах соответственно. |
| — t, —timestamp | Добавлять к выводу время замеров. |
| — D, —disk-sum | Выводит общую статистику по использованию дисков. |
Примеры использования vmstat
Несмотря на то, что опции vmstat и позволяют получить ценные сведения, однако в большинстве случаев системные администраторы их практически не используют. Чаще всего использование vmstat сводится к следующему (что вполне достаточно):
procs -----------memory------- -swap- --io-- -system-- ----cpu---- r b swpd free buff cache si so bi bo in cs us sy id wa 1 0 820 2606356 428776 487092 0 0 4741 65 1063 4857 25 1 73 0 1 0 820 2570324 428812 510196 0 0 4613 11 1054 4732 25 1 74 0 1 0 820 2539028 428852 535636 0 0 5099 13 1057 5219 90 1 9 0 1 0 820 2472340 428920 581588 0 0 4536 10 1056 4686 87 3 10 0 3 0 820 2440276 428960 605728 0 0 4818 21 1060 4943 20 3 77 0
Вообще, сервер общего назначения считается хорошо отбалансирован в плане нагрузки, если около 50% времени он тратит на обработку пользовательских задач и ещё столько же — на работу системных вызовов, взаимодействующих с ядром. Простои в системе должны быть — это потенциал для увеличения нагрузки, но в то же время они (простои) не должны быть слишком большими — это значит, что мощности сервера расходуются впустую.
Из приведённого примера следует, что центральный процессор практически постоянно переключается между высоконагруженными режимами и периодами почти полного простоя. Таким образом, можно сделать вывод, что необходима настройка используемого в работе сервера ПО и системной конфигурации для более равномерного распределения нагрузки.
Заключение
Как можно видеть, даже без использования графических приложений с графиками и диаграммами, обычная команда vmstat способна дать наглядную картину происходящего, касающегося использования ресурсов системы. Ну а самые объективные и достоверные результаты анализа производительности могут зависеть от применяемой для каждого конкретного случая методики.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Похожие записи:
Загрузка процессора Linux
Чтобы узнать хватает ли мощности процессора вашему серверу или компьютеру надо посмотреть загрузку процессора в данный момент или за последнее время. Это значение показывает на сколько процентов используется вычислительная мощность процессора.
В этой статье мы рассмотрим несколько способов решения этой задачи с помощью привычных системных утилит и более сложных инструментов.
Как посмотреть загрузку процессора в Linux
1. Утилита htop
Самый простой способ узнать насколько процессор загружен в данный момент — воспользоваться утилитой htop. Она показывает не только процент загрузки по каждому ядру процессора отдельно, но и позволяет найти процессы, которые нагружают систему больше всего. Для установки htop в Debian или Ubuntu выполните:
Главное окно программы выглядит вот так:
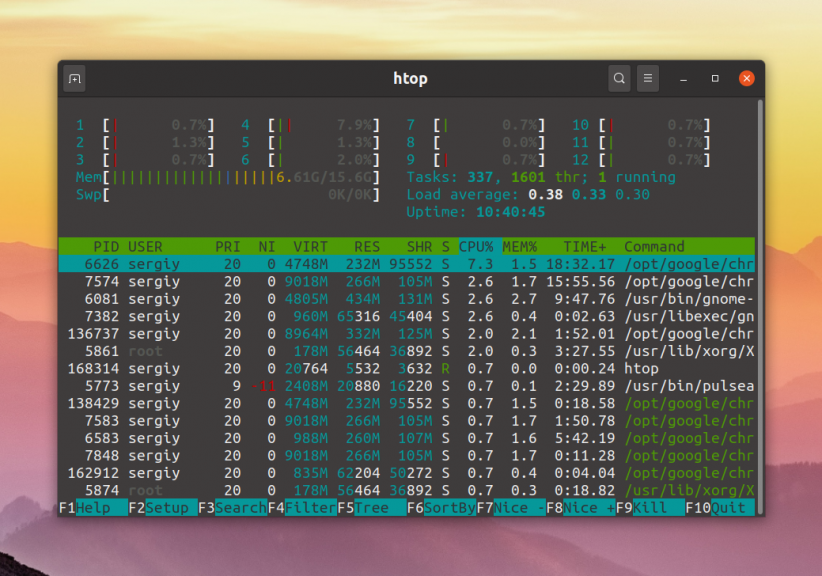
Здесь в верхней части окна выводится загрузка ядер процессора в виде наглядных шкал, а ниже процессы. В данном примере у процессора 12 ядер и каждое из них загружено не больше чем на один процент.
2. Файл /proc/loadavg
Если надо сориентироваться какая была нагрузка на процессор в последнее время, тут htop не поможет. Можно воспользоваться файлом /proc/loadavg. Его создаёт ядро и в нём содержится информация о средней нагрузке за одну, пять и пятнадцать минут. Но обратите внимание, данные, находящиеся в этом файле не такие однозначные. Во первых, это не проценты, во вторых, они отображают не нагрузку на процессор, а нагрузку на систему в целом.
Первые три значения в этом файле означают среднее количество процессов или потоков, которые выполняются, находятся в очереди на выполнение или ждут завершения операций ввода/вывода за 1, 5 и 15 минут. Вот:
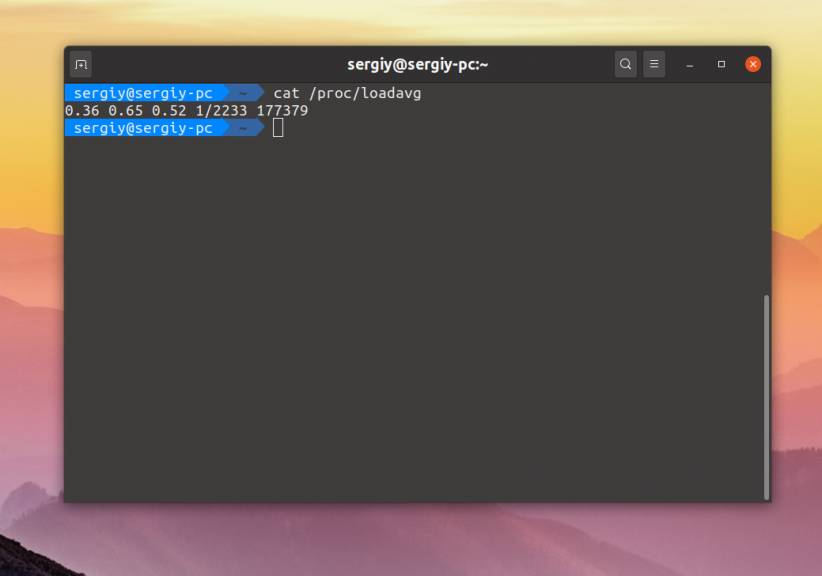
Обычно, если значение больше единицы — значит нагрузка уже большая и надо разбираться почему. Если значение за минуту меньше значений за пять и пятнадцать минут — нагрузка падает, если больше — растёт. Таким образом можно немного сориентироваться насколько загружена ваша система. Эти значения можно использовать для общего ориентирования или отправки уведомлений на почту, а для разбора полётов уже применять другие метрики и программы.
Четвертое значение здесь — это количество процессов — выполняемых в данный момент, обычно соответствует количеству процессоров, следующее число через слеш — это общее количество таких процессов в системе. Последнее значение — PID последнего созданного процесса.
3. Утилита mpstat
Утилита mpstat позволяет посмотреть подробную статистику по использованию процессора. Можно посмотреть не только информацию по каждому из ядер, но и куда используются ресурсы — на ввод/вывод, ядро или программы пространства пользователя. Для установки программы в Ubuntu или Debian выполните:
Для просмотра общей информации выполните такую команду:
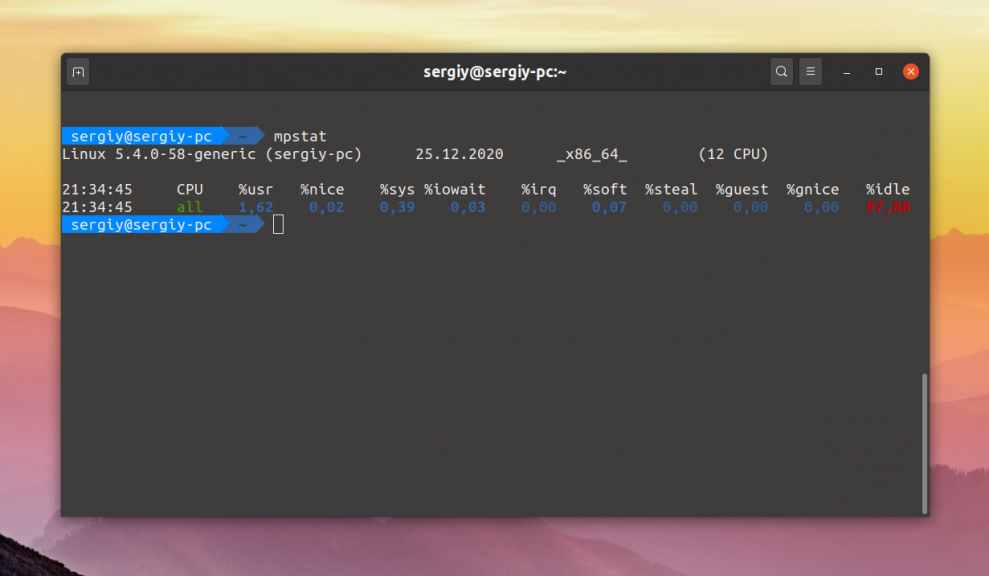
А для просмотра подробностей по каждому ядру процессора используйте опцию -P с параметром ALL:
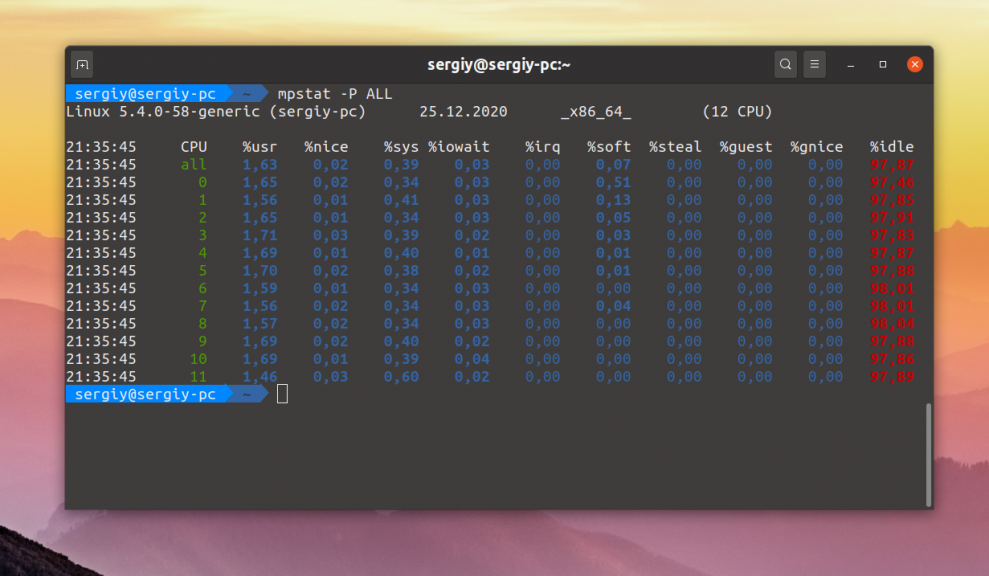
Вот значения колонок в выводе этой программы:
- CPU — номер ядра процессора;
- %usr — потребление программами пространства пользователя;
- %nice — потребление ресурсов в процентах программами в пространстве пользователя с повышенным приоритетом;
- %sys — потребление ресурсов процессора ядром;
- %iowait — затраты на ожидание ввода/вывода;
- %irq — ресурсы, потраченные на прерывания для работы с аппаратным обеспечением;
- %soft — ресурсы, потраченные на программные прерывания;
- %steal — украденные процессорные ресурсы, актуально для виртуальных машин;
- %guest — ресурсы, потраченные на работу виртуального процессора;
- %idle — неиспользованные ресурсы.
Как видите, в данном случае нагрузка на процессор не достигает даже трех процента для некоторых ядер.
4. Команда nmon
Утилита nmon позволяет выводить данные, в виде, похожем на htop, но только немного подробнее. Для установки её в Ubuntu и Debian выполните:
Для установки в CentOS или REHL:
После запуска надо нажать кнопку c для того чтобы отобразить информацию о нагрузке на ядра процессора:
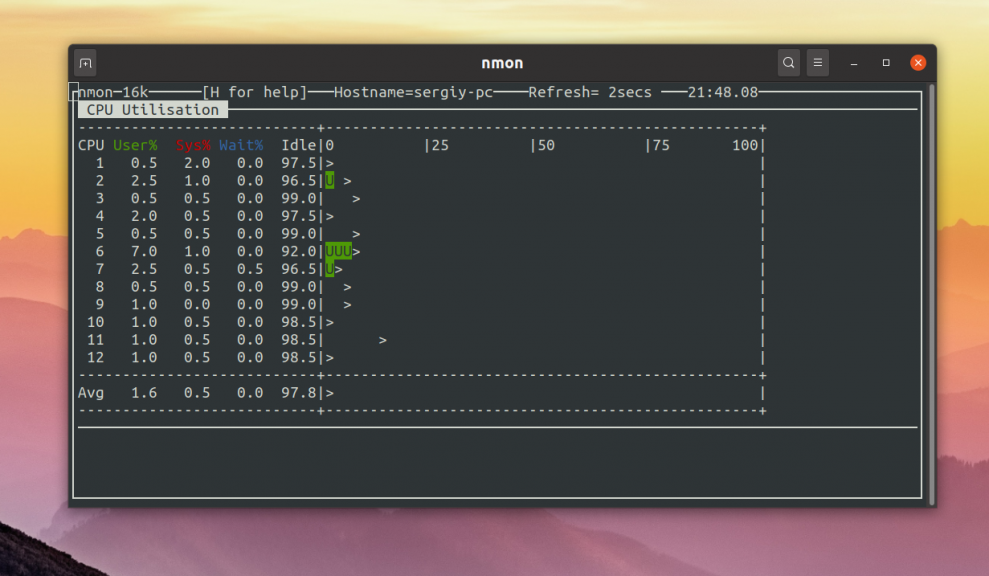
Здесь кроме наглядной шкалы по каждому ядру выводится информация в процентах по таким показателям:
- User% — ресурсы, потраченные программами в пространстве пользователя;
- Sys% — ресурсы, потраченные ядром;
- Wait% — ресурсы, которые идут на ожидание ввода/вывода;
Здесь уже можно сориентироваться насколько всё загружено и в чём проблема.
5. CoreFreq
Если всей полученной ранее информации о производительности вам мало, можно воспользоваться утилитой CoreFreq. Её нет в официальных репозиториях, поэтому придется собирать программу из исходников. Но зато она имеет свой модуль ядра, который устанавливает свои счетчики производительности в ядре и возвращает утилите наиболее подробные данные. Сначала установите необходимые компоненты. В Ubuntu:
sudo apt install dkms git libpthread-stubs0-dev
sudo yum group install ‘Development Tools’
Затем скачайте репозиторий утилиты с GitHub и соберите её:
git clone https://github.com/cyring/CoreFreq.git
Загрузите модуль ядра такой командой:
Затем запускайте программу:
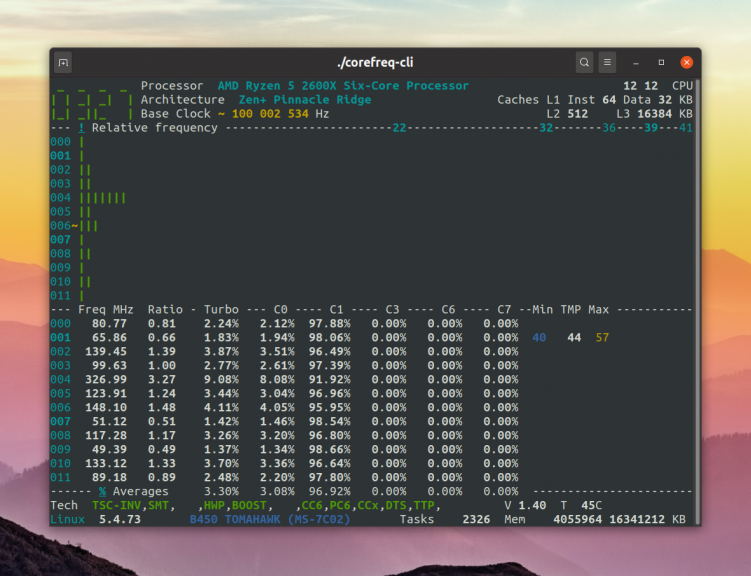
Вверху программы отображается информация о процессоре, ниже шкалы с загруженностью каждого ядра, а её ниже различные показатели по каждому ядру: частота — Freq, ускорение — Turbo, C0-C7 — значения состояний C-State процессора. В данном примере, большинство ядер процессора работают на минимальной частоте и большую часть времени находятся в состоянии C1. Это состояние означает, что ядро не активно, но может в любой момент перейти к выполнению инструкций. Состояние C0 — означает, что ядро активно и выполняет какие-то действия.
С помощью этой утилиты вы сможете узнать максимально подробную информацию о загрузке процессора и о самом процессоре в целом.
Выводы
В этой небольшой статье мы рассмотрели как определяется загрузка процессора Linux с помощью различных утилит. Как системных, так и сторонних. А какие утилиты для таких целей используете вы? Напишите в комментариях!
Обнаружили ошибку в тексте? Сообщите мне об этом. Выделите текст с ошибкой и нажмите Ctrl+Enter.