Find where inodes are being used
So I received a warning from our monitoring system on one of our boxes that the number of free inodes on a filesystem was getting low. df -i output shows this:
Filesystem Inodes IUsed IFree IUse% Mounted on /dev/xvda1 524288 422613 101675 81% / As you can see, the root partition has 81% of its inodes used.
I suspect they’re all being used in a single directory. But how can I find where that is at?
8 Answers 8
I saw this question over on stackoverflow, but I didn’t like any of the answers, and it really is a question that should be here on U&L anyway.
Basically an inode is used for each file on the filesystem. So running out of inodes generally means you’ve got a lot of small files laying around. So the question really becomes, «what directory has a large number of files in it?»
In this case, the filesystem we care about is the root filesystem / , so we can use the following command:
This will dump a list of every directory on the filesystem prefixed with the number of files (and subdirectories) in that directory. Thus the directory with the largest number of files will be at the bottom.
In my case, this turns up the following:
1202 /usr/share/man/man1 2714 /usr/share/man/man3 2826 /var/lib/dpkg/info 306588 /var/spool/postfix/maildrop So basically /var/spool/postfix/maildrop is consuming all the inodes.
*Note, this answer does have three caveats that I can think of. It does not properly handle anything with newlines in the path. I know my filesystem has no files with newlines, and since this is only being used for human consumption, the potential issue isn’t worth solving and one can always replace the \n with \0 and use -z options for the sort and uniq commands above as following:
Optionally you can add head -zn10 to the command to get top 10 most used inodes.
It also does not handle if the files are spread out among a large number of directories. This isn’t likely though, so I consider the risk acceptable. It will also count hard links to a same file (so using only one inode) several times. Again, unlikely to give false positives*
The key reason I didn’t like any of the answers on the stackoverflow answer is they all cross filesystem boundaries. Since my issue was on the root filesystem, this means it would traverse every single mounted filesystem. Throwing -xdev on the find commands wouldn’t even work properly.
For example, the most upvoted answer is this one:
for i in `find . -type d `; do echo `ls -a $i | wc -l` $i; done | sort -n If we change this instead to
for i in `find . -xdev -type d `; do echo `ls -a $i | wc -l` $i; done | sort -n even though /mnt/foo is a mount, it is also a directory on the root filesystem, so it’ll turn up in find . -xdev -type d , and then it’ll get passed to the ls -a $i , which will dive into the mount.
The find in my answer instead lists the directory of every single file on the mount. So basically with a file structure such as:
So we just have to count the number of duplicate lines.
@MohsenPahlevanzadeh that isn’t part of my answer, I was commenting on why I dislike the solution as it’s a common answer to this question.
Using a bind mount is a more robust way to avoid searching other file systems as it allows access to files under mount points. Eg, imagine I create 300,000 files under /tmp and then later the system is configured to mount a tmpfs on /tmp . Then you won’t be able to find the files with find alone. Unlikely senario, but worth noting.
Both work just had to remove sort because sort needs to create a file when the output is big enough, which wasn’t possible since I hit 100% usage of inodes.
Note that -printf appears to be a GNU extension to find, as the BSD version available in OS X does not support it.
The assumption that all files are in a single directory is a difficult one. A lot of programs know that many files in a single directory has bad performance and thus hash one or two levels of directories
This is reposted from here at the asker’s behest:
du --inodes --separate-dirs | sort -rh | sed -n \ '1,50' And if you want to stay in the same filesystem you do:
du --inodes --one-file-system --separate-dirs Here’s some example output:
15K /usr/share/man/man3 4.0K /usr/lib 3.6K /usr/bin 2.4K /usr/share/man/man1 1.9K /usr/share/fonts/75dpi . 519 /usr/lib/python2.7/site-packages/bzrlib 516 /usr/include/KDE 498 /usr/include/qt/QtCore 487 /usr/lib/modules/3.13.6-2-MANJARO/build/include/config 484 /usr/src/linux-3.12.14-2-MANJARO/include/config NOW WITH LS:
Note that the above require GNU du (i.e., from GNU coreutils), because POSIX du does not support —inodes , —one-file-system or —separate-dirs . (If you have Linux, you probably have GNU coreutils. And if you have GNU du , you can abbreviate —one-file-system to -x (lower case) and —separate-dirs to -S (upper case). POSIX du recognizes -x , but not -S or any long options.) Several people mentioned they do not have up-to-date coreutils and the —inodes option is not available to them. (But it was present in GNU coreutils version 8.22; if you have a version older than that, you should probably upgrade.) So, here’s ls :
ls ~/test -AiR1U | sed -rn '/^[./]/; G; s|^ *(53*)[^0-9][^/]*([~./].*):|\1:\2|p' | sort -t : -uk1.1,1n | cut -d: -f2 | sort -V | uniq -c | sort -rn | head -n10 If you’re curious, the heart-and-soul of that tedious bit of regex there is replacing the filename in each of ls ‘s recursive search results with the directory name in which it was found. From there it’s just a matter of squeezing repeated inode numbers, then counting repeated directory names and sorting accordingly.
The -U option is especially helpful with the sorting in that it specifically does not sort, and instead presents the directory list in original order – or, in other words, by inode number .
And of course -A for (almost) all, -i for inode and -R for recursive and that’s the long and short of it. The -1 (one) option was included out of force of habit.
The underlying method to this is that I replace every one of ls’s filenames with its containing directory name in sed. Following on from that. Well, I’m a little fuzzy myself. I’m fairly certain it’s accurately counting the files, as you can see here:
% _ls_i ~/test 100 /home/mikeserv/test/realdir 2 /home/mikeserv/test 1 /home/mikeserv/test/linkdir (where _ls_i represents the above ls — sed -. pipeline, defined as an alias or a script).
This is providing me pretty much identical results to the du command:
DU:
15K /usr/share/man/man3 4.0K /usr/lib 3.6K /usr/bin 2.4K /usr/share/man/man1 1.9K /usr/share/fonts/75dpi 1.9K /usr/share/fonts/100dpi 1.9K /usr/share/doc/arch-wiki-markdown 1.6K /usr/share/fonts/TTF 1.6K /usr/share/dolphin-emu/sys/GameSettings 1.6K /usr/share/doc/efl/html LS:
14686 /usr/share/man/man3: 4322 /usr/lib: 3653 /usr/bin: 2457 /usr/share/man/man1: 1897 /usr/share/fonts/100dpi: 1897 /usr/share/fonts/75dpi: 1890 /usr/share/doc/arch-wiki-markdown: 1613 /usr/include: 1575 /usr/share/doc/efl/html: 1556 /usr/share/dolphin-emu/sys/GameSettings: If you tediously compare the above, line by line, you’ll notice that the 8th line of the du output is /usr/share/fonts/TTF (1.6K) while the 8th line of the ls output is /usr/include (1613). I think the include thing just depends on which directory the program looks at first – because they’re the same files and hardlinked. Kinda like the thing above. I could be wrong about that though – and I welcome correction.
DU DEMO
% du --version du (GNU coreutils) 8.22 % mkdir ~/test ; cd ~/test % du --inodes --separate-dirs 1 . Some children directories:
% mkdir ./realdir ./linkdir % du --inodes --separate-dirs 1 ./realdir 1 ./linkdir 1 . % printf 'touch ./realdir/file%s\n' `seq 1 100` | . /dev/stdin % du --inodes --separate-dirs 101 ./realdir 1 ./linkdir 1 . % printf 'n="%s" ; ln ./realdir/file$n ./linkdir/link$n\n' `seq 1 100` | . /dev/stdin % du --inodes --separate-dirs 101 ./realdir 1 ./linkdir 1 . % cd ./linkdir % du --inodes --separate-dirs 101 % cd ../realdir % du --inodes --separate-dirs 101 They’re counted alone, but go one directory up.
% cd .. % du --inodes --separate-dirs 101 ./realdir 1 ./linkdir 1 . Then I ran my ran script from below and:
100 /home/mikeserv/test/realdir 100 /home/mikeserv/test/linkdir 2 /home/mikeserv/test 101 ./realdir 101 ./linkdir 3 ./ So I think this shows that the only way to count inodes is by inode. And because counting files means counting inodes, you cannot doubly count inodes – to count files accurately inodes cannot be counted more than once.
How to find a file’s Inode in Linux
Files written to Linux filesystems are assigned an inode. These unique IDs are used by the filesystem’s database in order to keep track of files. In this tutorial, you are going to learn how to view the inode number assigned to a file or directory.
There are two commands that can be used to view a file or directory’s inode, and they are ls and stat . Both of which are covered below.
The ls command is useful for discovering the inode number for a list of files in a directory, while the state command is better suited for single files or directories.
Using ls command
The simplist method of viewing the assigned inode of files on a Linux filesystem is to use the ls command. When used with the -i flag the results for each file contains the file’s inode number.
276944 drwxr-xr-x 16 www-data www-data 4096 Jun 4 2019 html 405570 drwxr-xr-x 5 www-data www-data 4096 Jun 10 21:48 wordpressIn the example above two directories are returned by the ls command. The first column of the returned listing is the assigned inode.
- the html directory was assigned inode 276944
- the wordpress directory was assigned inode 405570
Using stat command
Another method of viewing a file’s inode is to use the stat command. This method is generally used against a single file, while the ls command is used against a list of files.
The example will stat the html directory seen above.
File: ./html Size: 4096 Blocks: 8 IO Block: 4096 directory Device: 801h/2049d Inode: 276944 Links: 16 Access: (0755/drwxr-xr-x) Uid: ( 33/www-data) Gid: (33/www-data) Access: 2019-12-06 13:33:13.194964943 +0000 Modify: 2019-06-04 01:47:16.000000000 +0000 Change: 2019-12-06 13:33:05.246318669 +0000 As you can see from the output of state the inode value returned is the same as the one from the ls command: 276944.
How to Get Total Inodes of Root Partition
On Linux and other Unix-like operating systems, an inode stores information that describes a file or directory (also a file – because everything is a file in Unix) except its name and content or its actual data. Therefore, each file is indexed by an inode which is metadata about the file.
An inode contains information such as the physical location of the file, the size of the file, the file’s owner and group, the file’s access permissions (read, write and execute), timestamps, as well as a counter indicating the number of hard links pointing to the file.
Why is it important to keep an eye on inodes?
One of the possible ways in which a filesystem can run out of space is when all the inodes are used up. This can happen even when there is enough free space on disk; consumption of all inodes in the filesystem can block the creation of new files. Besides, it can result in a sudden stop of the system.
To get the number of inodes of files in a directory, for example, the root directory, open a terminal window and run the following ls command, where the -l option means long listing format, -a means all files and -i mean to print the index number of each file.
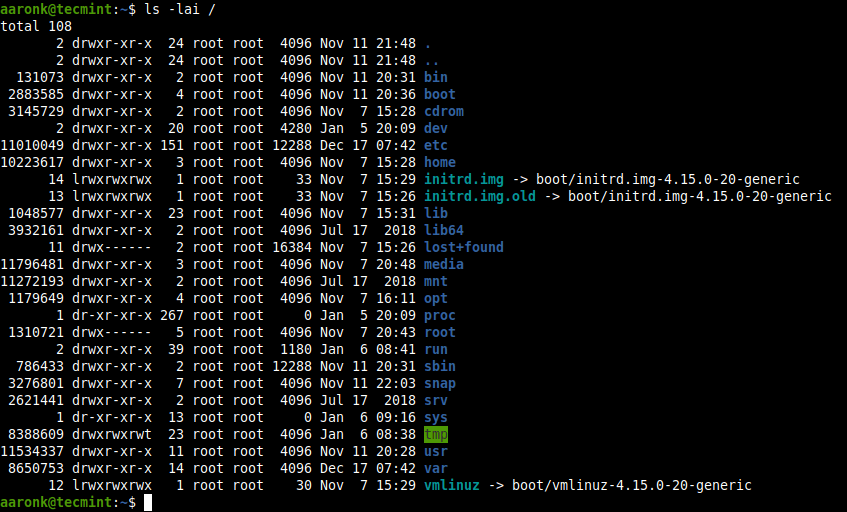
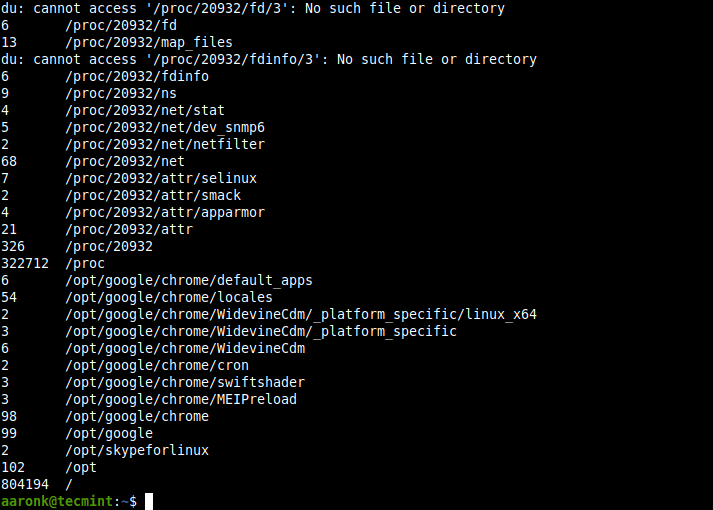
To get the total number of inodes in the root directory, run the following du command.
To list statistics about inode usage (amount available, amount used and amount free and use percentage) in the root partition, use the df commands as follows (the -h flag allows for showing information in a human-readable format).