Сетевая модель базы данных.
На разработку этого стандарта большое влияние оказал американский ученый Ч.Бахман. Основные принципы сетевой модели данных были разработаны в середине 60-х годов, эталонный вариант сетевой модели данных описан в отчетах рабочей группы по языкам баз данных (COnference on DAta SYstem Languages) CODASYL (1971 г.).
Сетевая модель данных определяется в тех же терминах, что и иерархическая. Она состоит из множества записей, которые могут быть владельцами или членами групповых отношений. Связь между записью-владельцем и записью-членом также имеет вид 1:N.
Основное различие этих моделей состоит в том, что в сетевой модели запись может быть членом более чем одного группового отношения. Согласно этой модели каждое групповое отношение именуется и проводится различие между его типом и экземпляром. Тип группового отношения задается его именем и определяет свойства общие для всех экземпляров данного типа. Экземпляр группового отношения представляется записью-владельцем и множеством (возможно пустым) подчиненных записей. При этом имеется следующее ограничение: экземпляр записи не может быть членом двух экземпляров групповых отношений одного типа (т.е. сотрудник из примера в п..1, например, не может работать в двух отделах).
Иерархическая структура рис.4.2 преобразовывается в сетевую следующим образом (см. рис. 4.3):
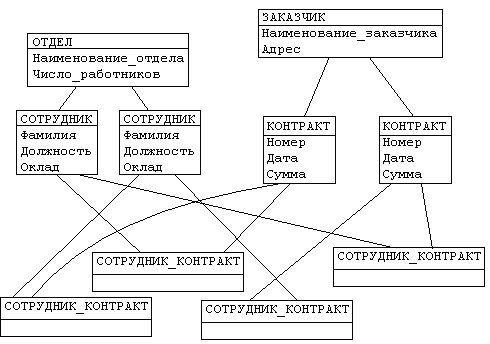
- деревья (a) и (b), показанные на рис. 4.2, заменяются одной сетевой структурой, в которой запись СОТРУДНИК входит в два групповых отношения;
- для отображения типа M:N вводится запись СОТРУДНИК_КОНТРАКТ, которая не имеет полей и служит только для связи записей КОНТРАКТ и СОТРУДНИК, см. рис. 4.3 (Отметим, что в этой записи может храниться и полезная информация, например, доля данного сотрудника в общем вознаграждении по данному контракту.)
Рисунок 4.3. Сетевая модель базы данных Каждый экземпляр группового отношения характеризуется следующими признаками: способ упорядочения подчиненных записей:
- произвольный,
- хронологический /очередь/,
- обратный хронологический /стек/,
- сортированный.
Если запись объявлена подчиненной в нескольких групповых отношениях, то в каждом из них может быть назначен свой способ упорядочивания. режим включения подчиненных записей: автоматический — невозможно занести в БД запись без того, чтобы она была сразу же закреплена за неким владельцем; ручной — позволяет запомнить в БД подчиненную запись и не включать ее немедленно в экземпляр группового отношения. Эта операция позже инициируется пользователем). режим исключения. Принято выделять три класса членства подчиненных записей в групповых отношениях:
- Фиксированное. Подчиненная запись жестко связана с записью владельцем и ее можно исключить из группового отношения только удалив. При удалении записи–владельца все подчиненные записи автоматически тоже удаляются. В рассмотренном выше примере фиксированное членство предполагает групповое отношение «ЗАКЛЮЧАЕТ» между записями «КОНТРАКТ» и «ЗАКАЗЧИК», поскольку контракт не может существовать без заказчика.
- Обязательное. Допускается переключение подчиненной записи на другого владельца, но невозможно ее существование без владельца. Для удаления записи-владельца необходимо, чтобы она не имела подчиненных записей с обязательным членством. Таким отношением связаны записи «СОТРУДНИК» и «ОТДЕЛ». Если отдел расформировывается, все его сотрудники должны быть либо переведены в другие отделы, либо уволены.
- Необязательное. Можно исключить запись из группового отношения, но сохранить ее в базе данных не прикрепляя к другому владельцу. При удалении записи-владельца ее подчиненные записи — необязательные члены сохраняются в базе, не участвуя более в групповом отношении такого типа. Примером такого группового отношения может служить «ВЫПОЛНЯЕТ» между «СОТРУДНИКИ» и «КОНТРАКТ», поскольку в организации могут существовать работники, чья деятельность не связана с выполнением каких-либо договорных обязательств перед заказчиками.
2.2. Сетевая модель данных
СМД позволяет отображать разнообразные взаимосвязи элементов данных в виде произвольного графа, обобщая тем самым ИМД (рис. 2.4). Наиболее полно концепция сетевых БД впервые была изложена в Предложениях группы КОДАСИЛ (KODASYL).

Рис. 2.4. Представление связей в сетевой модели
Для описания схемы сетевой БД используется две группы типов: «запись» и «связь». Тип «связь» определяется для двух типов «запись»: предка и потомка. Переменные типа «связь» являются экземплярами связей.
Сетевая БД состоит из набора записей и набора соответствующих связей. На формирование связи особых ограничений не накладывается. Если в иерархических структурах запись-потомок могла иметь только одну запись-предка,то в сетевой модели данных запись-потомок может иметь произвольное число записей-предков (сводных родителей).
Пример схемы простейшей сетевой БД показан на рис. 2.5. Типы связей здесь обозначены надписями на соединяющих типы записей линиях.

Рис. 2.5. Пример схемы сетевой БД
В различных СУБД сетевого типа для обозначения одинаковых по сути понятий зачастую используются различные термины. Например, такие как элементы и агрегаты данных, записи, наборы, области и т. д. (см. п. 1.1.3).
Физическое размещение данных в базах сетевого типа может быть организовано практически теми же методами, что и в иерархических базах данных.
К числу важнейших операций манипулирования данными баз сетевого типа можно отнести следующие:
переход от предка к первому потомку;
переход от потомка к предку;
обновление текущей записи;
исключение записи из связи;
Достоинством сетевой модели данных является возможность эффективной реализации по показателям затрат памяти и оперативности. В сравнении с иерархической моделью сетевая модель предоставляет большие возможности в смысле допустимости образования произвольных связей.
Недостатком сетевой модели данных является высокая сложность ижесткость схемы БД, построенной на ее основе, а также сложность для понимания и выполнения обработки информации в БД обычным пользователем. Кроме того, в сетевой модели данных ослаблен контрольцелостности связей вследствие допустимости установления произвольных связей между записями.
Системы на основе сетевой модели не получили широкого распространения на практике. Наиболее известными сетевыми СУБД являются следующие: IDMS, db_VistaIII, СЕТЬ, СЕТОР и КОМПАС.
2.3. Реляционная модель данных
Реляционная модель данных предложена сотрудником фирмы IBMЭдгаром Коддом и основывается на понятии «отношение» (relation).
Отношение представляет собой множество наборов элементов, называемых кортежами. Подробно теоретическая основа реляционной модели данных рассматривается в следующем разделе. Наглядной формой представления отношения является привычная для человеческого восприятия двумерная таблица.
Таблица имеет строки (записи) и столбцы (колонки). Каждая строка (запись) таблицы имеет одинаковую структуру и состоит из полей. Строкам таблицы соответствуют кортежи, а столбцам — атрибуты отношения (имена полей).
С помощью одной таблицы удобно описывать простейший вид связей между данными, а именно деление одного объекта (явления, сущности, системы и проч.), информация о котором хранится в таблице, на множество под объектов, каждому из которых соответствует строка или запись таблицы. При этом каждый из подобъектов имеет одинаковую структуруили свойства, описываемые соответствующими значениями полей записей. Например, таблица может содержать сведения о группе обучаемых, о каждом из которых известны следующие характеристики: фамилия, имя и отчество, пол, возраст и образование. Поскольку в рамках одной таблицыне удается описать более сложные логические структуры данных из предметной области, применяют связывание таблиц.
Физическое размещение данных в реляционных базах на внешних носителях легко осуществляется с помощью обычных файлов.
Достоинство реляционной модели данных заключается в простоте, понятности и удобстве физической реализации на ЭВМ. Именно простота и понятность для пользователя явились основной причиной их широкого использования. Проблемы же эффективности обработки данных этого типа оказались технически вполне разрешимыми.
Основными недостатками реляционной модели являются:отсутствие стандартных средств идентификации отдельных записей и сложность описания иерархических и сетевых связей.
Примерами зарубежных реляционных СУБД для ПЭВМ являются следующие: dBaseIII Plus и dBase IV (фирма Ashton-Tate), DB2 (IBM), R:BASE (Microrim), FoxPro ранних версий и FoxBase (Fox Software), Paradox и dBASE for Windows (Borland), FoxPro более поздних версий, Visual FoxPro и Access (Microsoft), Clarion (Clarion Software), Ingres (ASK Computer Systems) иOracle(Oracle).
К отечественным СУБД реляционного типа относятся системы: ПАЛЬМА (ИК АН Украины), а также система HyTech (МИФИ, РФ).
Заметим, что последние версии реляционных СУБД имеют некоторые свойства объектно-ориентированных систем. Такие СУБД часто называют объектно-реляционными. Примером такой системы можно считать продукты Oracle 8.x. Системы предыдущих версий вплоть до Oracle 7.x считаются «чисто» реляционными.
Сетевая модель данных и ее характеристики. Понятие набора
Сетевая модель данных позволяет отображать разнообразные взаимосвязи элементов данных в виде произвольного графа, обобщая тем самым иерархическую модель данных (рис. 2.4). Наиболее полно концепция сетевых БД впервые была изложена в Предложениях группы КОДАСИЛ (KODASYL).
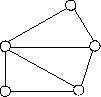
Рис. 2.4. Представление связей в сетевой модели
Для описания схемы сетевой БД используется две группы типов: «запись» и «связь». Тип «связь» определяется для двух типов «запись»: предка и потомка. Переменные типа «связь» являются экземплярами связей. Сетевая БД состоит из набора записей и набора соответствующих связей. На формирование связи особых ограничений не накладывается. Если в иерархических структурах запись-потомок могла иметь только одну запись-предка, то в сетевой модели данных запись-потомок может иметь произвольное число записей-предков (сводных родителей). Пример схемы простейшей сетевой БД показан на рис. 2.5. Типы связей здесь обозначены надписями на соединяющих типы записей линиях.

Рис. 2.5. Пример схемы сетевой БД

Рис. 2.5. Пример схемы сетевой БДВ различных СУБД сетевого типа для обозначения одинаковых по сути понятий зачастую используются различные термины. Например, такие, как элементы и агрегаты данных, записи, наборы, области и т. д. Физическое размещение данных в базах сетевого типа может быть организовано практически теми же методами, что и в иерархических базах данных. К числу важнейших операций манипулирования данными баз сетевого типа можно отнести следующие: поиск записи в БД; переход от предка к первому потомку; переход от потомка к предку; создание новой записи; удаление текущей записи; обновление текущей записи; включение записи в связь; исключение записи из связи; изменение связей и т. д. Достоинством сетевой модели данных является возможность эффективной реализации по показателям затрат памяти и оперативности. В сравнении с иерархической моделью сетевая модель предоставляет большие возможности в смысле допустимости образования произвольных связей. Недостатком сетевой модели данных является высокая сложность и жесткость схемы БД, построенной на ее основе, а также сложность для понимания и выполнения обработки информации в БД обычным пользователем. Кроме того, в сетевой модели данных ослаблен контроль целостности связей вследствие допустимости установления произвольных связей между записями. Системы на основе сетевой модели не получили широкого распространения на практике. Наиболее известными сетевыми СУБД являются следующие: IDMS, db VistaIII, СЕТЬ, СЕТОР и КОМПАС.
Набор –это структура данных, которая отображает связи меду объектами в предметной области. Каждый набор содержит единственную запись, называемую владельцем набора, и множество записей, называемых членами набора. Наборы, имеющие одинаковый тип владельца и одинаковый тип члена, а также обладающие одинаковой семантикой (смыслом), объединяются в тип набора, который имеет уникальное имя.