- Мониторинг и восстановление программного RAID в Linux
- Вики IT-KB
- Мониторинг Linux Software RAID (mdraid) в Icinga с плагином check_raid
- Плагин check_raid
- Icinga Director и check_raid
- mdraid и cron
- Обсуждение
- Мониторинг программного raid linux
- Zabbix — мониторинг программных RAID массивов в Linux
- Установка шаблона
- Версии
Мониторинг и восстановление программного RAID в Linux
Восстановление функционирования (rebuild) разделов диска по одному после
однократного “несмертельного” сбоя:
# mdadm -a /dev/md /dev/sd
например:
# mdadm -a /dev/md0 /dev/sdb1
Нужно быть аккуратным с номерами разделов
В случае ошибки, удалить компонент из RAID командой:
# mdadm -r /dev/md0 /dev/sdb1
получается не всегда – устройство может быть занято.
1. Выключить компьютер и заменить диск
2. Включить компьютер и определить имеющиеся на обоих дисках разделы:
# fdisk /dev/sd -l
3. С помощью fdisk создать на новом диске разделы, идентичные оригиналу
Необходимо пометить нужный раздел нового диска (sda1 или sdb1) как загрузочный
до включения в зеркало.
Swap-разделы не подлежат зеркалированию в программном RAID
4. Выполнить Мониторинг состояния и Восстановление функционирования
Мониторинг выполняется с помощью crond ежечасно.
В папку /etc/cron.haurly помещен файл mdRAIDmon, содержащий команду:
# mdadm –monitor –scan -1 –mail=postmaster@domain.name.ru
Для проверки рассылки сообщения добавляется ключ –test:
# mdadm –monitor –scan -1 –mail=postmaster@domain.name.ru –test
Помещая файл задания в папку, необходимо установить права доступа на выполнение
Если нужно чаще, самое простое, добавьте в /etc/crontab строку, используя нотацию с “/”, например:
*/5 * * * * root run-parts /etc/cron.my5min
Конечно, можно попробовать и другие варианты планирования заданий с atd или batch.
Создайте папку /etc/cron.my5min и поместите туда файл mdRAIDmon
C имитацией отказа диска мне было проще – сервер SR1425BK1 – с корзиной HotSwap
Вики IT-KB
Мониторинг Linux Software RAID (mdraid) в Icinga с плагином check_raid

Среди ряда публично доступных плагинов мониторинга программной реализации RAID в ОС Linux на базе Linux Software RAID (Multiple Device/MD RAID/mdraid), совместимых с Icinga, по функциональным возможностям можно выделить плагин: check_raid. В этой статье мы рассмотрим пример установки и простейшей настройки плагина check_raid.
Плагин check_raid
Плагин check_raid по своей сути — большой скрипт, написанный на Perl. Плагин является универсальным, так как поддерживает мониторинг множества разных типов RAID-контроллеров. Основная информация о плагине доступна на странице проекта: nagios-plugin-check_raid
Если заглянем в releases, то увидим, что стабильной версией на данный момент признаётся версия 4.0.10 (16 May 2019).
Загружать плагин нужно на тот сервер, где нам требуется выполнять проверку mdraid.
Для начала определимся с каталогом размещения плагинов Icinga и закинем путь к нему в переменную окружения с удобным нам именем, например ICINGA_PLUGIN_DIR на Debian 64-bit это будет выглядеть так:
# export ICINGA_PLUGIN_DIR="/usr/lib/nagios/plugins/"
на CentOS 64-bit это будет выглядеть так:
# export ICINGA_PLUGIN_DIR="/usr/lib64/nagios/plugins/"
Скачиваем плагин в каталог плагинов:
# wget https://github.com/glensc/nagios-plugin-check_raid/releases/download/4.0.10/check_raid.pl --directory-prefix=$ICINGA_PLUGIN_DIR
Переходим в этот каталог и делаем плагин исполняемым
# cd $ICINGA_PLUGIN_DIR # chmod +x ./check_raid.pl
Выполняем проверку запуска плагина с выводом поддерживаемых сриптом проверок для данной системы
# ./check_raid.pl --list-plugins
hp_msa hpacucli mdstat 3 active plugins
Как видим, скрипт на нашей системе поддерживает 3 типа проверок, так называемых «плагинов» (не путать с самим плагинами Icinga), то есть написанных внутри него модулей проверок разных типов. В контексте данной статьи нас интересует лишь тип проверки mdstat, который доступен нам, так как на сервере имеются программные RAID-массивы Linux mdraid.
Попробуем выполнить проверку типа mdstat
# ./check_raid.pl --plugin mdstat
OK: mdstat:[md1(4.55 TiB raid6):UUUUUUUUUUUU, md0(4.55 TiB raid6):UUUUUUUUUUUU]
Как видим, плагин успешно опознал имеющиеся в нашей системе программные RAID-массивы md1 / md0 и выдал информацию об их текущем состоянии.
Icinga Director и check_raid
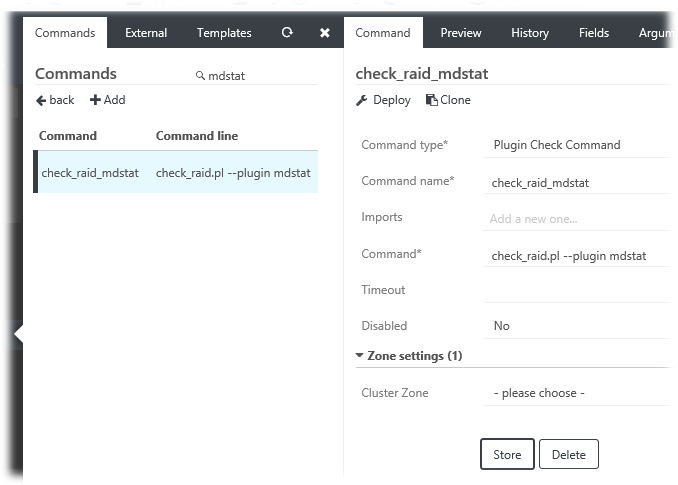
Теперь на стороне сервера Icinga в веб-консоли Icinga Director создаём команду, например «check_raid_mdstat» (с фактической командой вызова check_raid.pl –plugin mdstat )
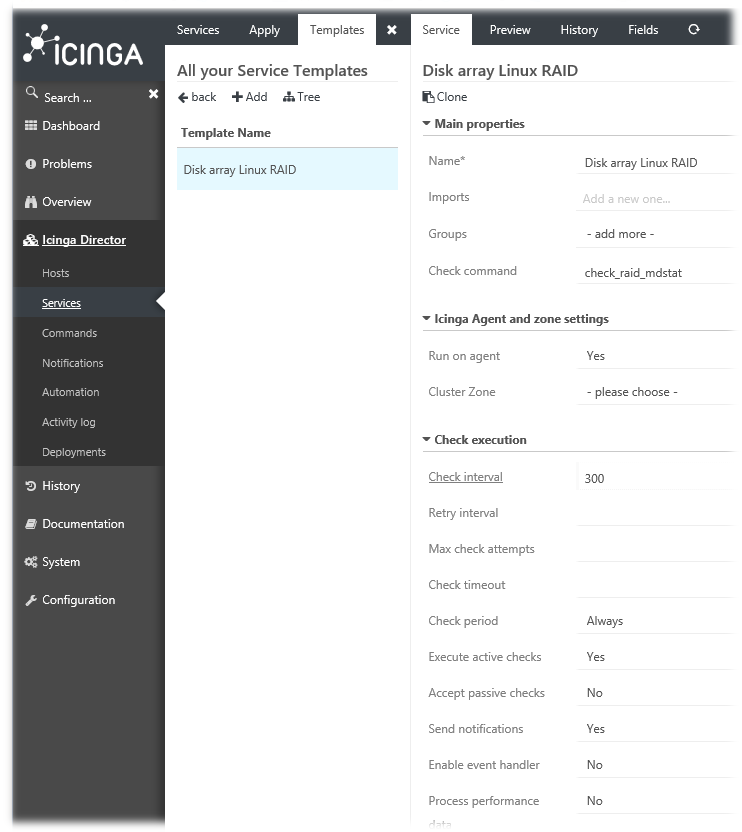
Затем на основе созданной ранее команды «check_raid_mdstat» создаём шаблон службы, например «Disk array Linux RAID»
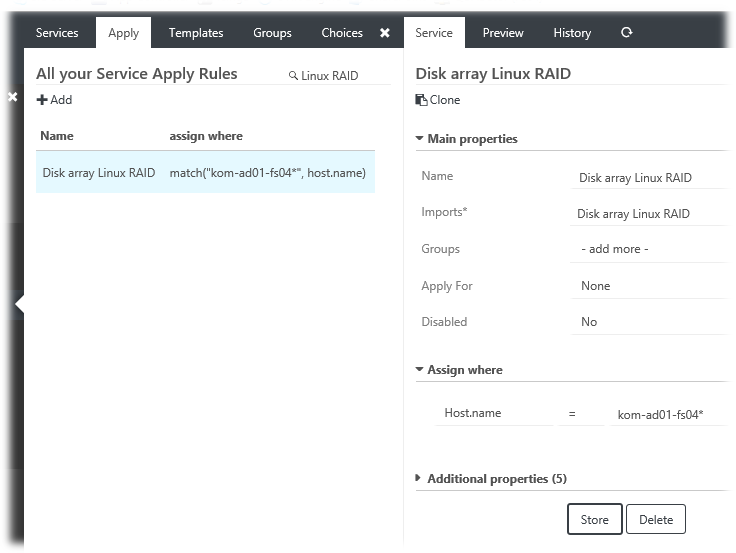
Назначаем любым удобным способом шаблон службы на хосты, которые необходимо мониторить данной службой (разумеется на всех соответствующих хостах в каталоге $ICINGA_PLUGIN_DIR предварительно должен быть установлен плагин check_raid.pl). В нашем упрощённом примере создано правило Apply Rule с нацеливанием на имя конкретного сервера.
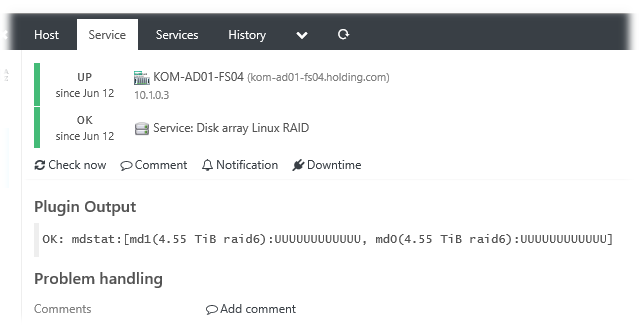
В конечном итоге получаем желаемый результат:
mdraid и cron
Есть мнение, что периодически запускаемые в конфигурации по умолчанию (ежемесячно, в первое Воскресенье месяца в 00:57) проверки mdraid в задании планировщика cron (файл задания /etc/cron.d/mdadm с командой /usr/share/mdadm/checkarray –cron –all –idle –quiet ) в некоторых случаях могут отрицательно повлиять на производительность. Таким образом, имея настроенный мониторинг программных массивов mdraid средствами Icinga, можно отключить данные периодические проверки. Для меня данный вопрос пока остаётся открытым.
Проверено на следующих конфигурациях:
| Версия ОС на стороне клиента Icinga | Версия клиента Icinga | Скрипт и его версия |
|---|---|---|
| Debian GNU/Linux 9.4 (Stretch) x86_64 | r2.7.0-1 | check_raid 4.0.8 (2017-09-01) |
| Debian GNU/Linux 10.13 (Buster) x86_64 | r2.13.5-1 | check_raid 4.0.10 (2019-05-16) |

Автор первичной редакции:
Алексей Максимов
Время публикации: 18.06.2018 19:22
Обсуждение
icinga/icinga-monitoring-of-linux-software-raid-mdraid-via-check_raid-plugin.txt · Последнее изменение: 13.10.2022 15:17 — Алексей Максимов
Мониторинг программного raid linux
PS
> Swap-разделы не подлежат зеркалированию в программном RAID
>Не разу кстати не видел, чтобы рейд жрал хотя-бы один процент процессорного времени.
От видения неприятного процента CPU за md*_raid*, страшных iowait и LA помогают:
— тесты _заранее_ под нагрузкой (bonnie/bonnie++ в помощь): может, лишнее место не стоит тормозов БД (или ещё чего активно пишущего) и лучше сделать 1/10, а не 5?
— для 5/6: stripe alignment (http://www.pythian.com/blogs/411/aligning-asm-disks-on-linux)
— понимание, что такое seek, и разнос нагрузки по физическим шпинделям (и их пачкам)
— монтировать с noatime, если оно некритично
— xfs (ОБЯЗАТЕЛЬНО с UPS!)
— разумное поднятие readahead и stripe cache, подбор io scheduler — например, для двух SATA RAID5 по четыре диска каждый:
for i in a b c d e f g h; do
echo deadline > /sys/block/sd$i/queue/scheduler
echo 1024 > /sys/block/sd$i/queue/read_ahead_kb
done
echo 2048 > /sys/block/md0/md/stripe_cache_size
echo 2048 > /sys/block/md4/md/stripe_cache_size
>Можно все тоже самое, только «на пальцах»? (Для простых смертных)
bonnie/bonnie++ — это бенчмарки, обычно живут в одноименных пакетах в дистрибутиве.
noatime — параметр монтирования ФС, при котором чтение данных не приводит к записи в метаданные (см. man mount, man fstab).
xfs — файловая система, которая хорошо держит большую нагрузку.
Поскольку спросили — вот скрипт со ссылками:
#!/bin/sh
# http://www.mail-archive.com/linux-raid@vger.kernel.org/msg07509.html
# (thanks vsu@)
# https://mail.clusterfs.com/wikis/attachments/LustreManual.html#1.4.3_Proper_Ke
# ‘-> The «cfq» and «as» schedulers should never be used for server platform
for i in a b c d e f g h; do
echo deadline > /sys/block/sd$i/queue/scheduler
echo 1024 > /sys/block/sd$i/queue/read_ahead_kb
done
# http://scotgate.org/?p=107
echo 2048 > /sys/block/md0/md/stripe_cache_size
echo 2048 > /sys/block/md4/md/stripe_cache_size
#echo 3000 > /sys/block/md4/md/sync_speed_min
#echo 5000 > /sys/block/md4/md/sync_speed_max
| Добавить заметку |
| Версия для печати |
| Последние заметки |
| — 18.04 Перевод шифрованного раздела на LUKS2 и более надёжную функцию формирования ключа |
| — 31.03 Пример правил nftables с реализацией port knoсking для открытия доступа к SSH |
| — 27.02 Обновление сертификатов oVirt |
| — 20.11 Решение проблемы со шрифтами в Steam после выставления времени после 2038 года |
| — 18.11 Раскладка клавиатуры для ввода символов APL |
| — 10.09 Настройка СУБД Postgresql для аутентификации пользователей через Active Directory |
| — 09.09 Настройка СУБД PostgreSQL 13 под управлением Pacemaker/Corosync в Debian 11 |
| — 08.09 Создание виртуальных машин с помощью Qemu KVM |
| — 25.07 Создание программ под SynapseOS |
| — 24.07 Случайная задержка в shell-скрипте, выполняемом из crontab (без башизмов) |
| RSS | Следующие 15 записей >> |
Zabbix — мониторинг программных RAID массивов в Linux

Раньше для мониторинга программных RAID массивов в Linux я пользовался сторонним шаблоном, до тех пор, пока у меня не пропал SPARE диск. Я узнал об этом случайно, потому что SPARE диски обычным шаблоном не определялись. Пришлось писать шаблон самому.
Мой шаблон работает на основе утилиты mdadm. Список MD массивов определяется автоматически. В шаблоне 2 элемента данных, 10 прототипов элементов данных и 12 прототипов триггеров. Я читал мануал ядра Linux, но так и не смог определить все варианты статусов MD массива, которые выводятся утилитой mdadm, поэтому точно определяю статусы active и clean, в другом случае сработает триггер. Вы можете добавлять свои статусы, чтобы избавиться от ложных срабатываний.
С переводами строк разберитесь, могут быть несовпадения, т.к. файлы редактирую в Windows.
Установка шаблона
Качаем шаблон для Zabbix 5.0: zabbix_mdadm
Импортируем шаблон zbx5_mdadm_linux.xml. Подключаем шаблон к хостам.
В макросах шаблона можно отредактировать периодичность опроса данных:
- — 1h. Периодичность автообнаружения массивов.
- — 30d. Срок хранения истории.
- — 5m. Периодичность опроса важных данных.
- — 1h. Периодичность опроса данных, которые нужно получать не часто.
- — 10m. Периодичность опроса данных.
- — 180d. Срок хранения трендов.

На серверах, которые собираемся мониторить, установим mdadm:
Копируем userparameter_md.conf в папку с пользовательскими переменными, у меня это /etc/zabbix/zabbix_agentd.conf.d/userparameter_md.conf. Не забываем про владельца и права:
chown root\: /etc/zabbix/zabbix_agentd.conf.d/userparameter_md.conf chmod 644 /etc/zabbix/zabbix_agentd.conf.d/userparameter_md.confКопируем папку со скриптами в /etc/zabbix/scripts/. В ней у нас:
- /etc/zabbix/scripts/md_active_devices.sh
- /etc/zabbix/scripts/md_array_size.sh
- /etc/zabbix/scripts/md_failed_devices.sh
- /etc/zabbix/scripts/md_raid_devices.sh
- /etc/zabbix/scripts/md_raid_level.sh
- /etc/zabbix/scripts/md_spare_devices.sh
- /etc/zabbix/scripts/md_state.sh
- /etc/zabbix/scripts/md_total_devices.sh
- /etc/zabbix/scripts/md_used_dev_size.sh
- /etc/zabbix/scripts/md_working_devices.sh
Не забываем про владельца и права:
chown -R root\: /etc/zabbix/scripts chmod a+x /etc/zabbix/scripts/*Копируем sudoers_zabbix_md в /etc/sudoers.d. Не забываем про владельца и права:
chown root\: /etc/sudoers.d/sudoers_zabbix_md chmod 644 /etc/sudoers.d/sudoers_zabbix_mdservice zabbix-agent restartВерсии
v2 — исправления триггеров.
v3 — новые триггеры и исправление триггеров.
v4 — добавлен мониторинг минимальной и максимальной скорости синхронизации массивов, новые триггеры и исправление триггеров.