- Структурные компоненты Интернета
- Как устроен интернет и при чём тут акулы
- Как работает интернет?
- Почему сайтом может пользоваться много человек одновременно?
- Как быстро работает браузер?
- Почему реклама на сайтах знает так много?
- Как работает веб-архив?
- Сайты живут вечно?
- Акулы — главная опасность интернета?
Структурные компоненты Интернета
Интернет — это сложное техническое образование, обладающее свойствами самоорганизации и саморегуляции, характерными для объектов живой природы и крайне редко проявляющимися в технических системах. На этих свойствах основана высокая устойчивость Интернета в техническом, экономическом, социальном и политическом смысле. Сегодня невозможно указать какой-то сектор Сети, при выходе которого из строя (по любой причине) нарушилось бы функционирование Интернета в целом и его дальнейшее саморазвитие.
Саморазвитие Интернета происходит путем его расширения за счет включения все новых и новых компонентов. Этот процесс напоминает ветвление живого растительного организма, только в его основе лежат не естественные процессы обмена веществ, а экономические процессы обмена ресурсами. Интернет не является коммерческой организацией и никому не принадлежит; оплачиваются только услуги провайдера — организации, предоставляющей возможность подключения к Интернету.
Рост и развитие происходят одновременно и сбалансировано по трем направлениям, соответствующим трем основным компонентам Интернета: аппаратному, программному и информационному.
Аппаратный компонент Интернета представлен компьютерами самых разных моделей и систем, линиями связи любой физической природы и устройствами, обеспечивающими механическую и электрическую стыковку между компьютерами и линиями связи:
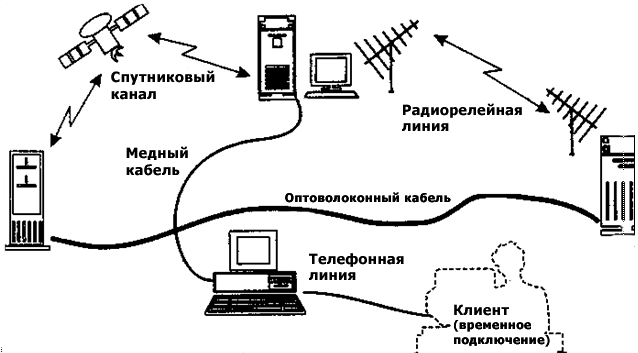
- компьютерами (серверами, рабочими станциями);
- сетевым, оборудованием (шлюзами, маршрутизаторами, брандмауэрами, сетевыми адаптерами);
- модемами и коммутационным оборудованием;
- кабельными системами передачи,
- источниками бесперебойного питания и др.
Шлюз(gateway) — это компьютер со специальным программным обеспечением, позволяющий связываться двум сетям с разными протоколами. Маршрутизатор (router) связывает сети с одинаковыми протоколами, но разными типами сетевого оборудования. Брандмауэр— это компьютер, ограничивающий доступ в сеть некоторой организации. Все аппаратные компоненты Интернета могут действовать в единой Сети как на постоянной, так и на временной основе. Физический выход из строя или временное отключение отдельных участков Сети, а также неработоспособность отдельных компьютеров Сети никак не влияет на возможность функционирования самой Сети. Физическую архитектуру Интернета составляют линии связи любых типов, как традиционных, так и экзотических (рис. 10). Программный компонент.Слаженная совместная работа разнообразного оборудования — функциональная совместимость — достигается благодаря программам, работающим на компьютерах, входящих в Сеть. Они позволяют так преобразовывать данные, чтобы их можно было передавать по любым каналам связи и воспроизводить на любых компьютерах. Программы следят за соблюдением единых протоколов, обеспечивают целостность передаваемых данных, контролируют состояние Сети и в случае обнаружения пораженных или перегруженных участков оперативно перенаправляют потоки данных. У программного обеспечения Сети очень много различных функций, важнейшими из которых являются: функции хранения информации, ее поиска, сбора, воспроизведения, а также обеспечения безопасности в Сети. Рис. 10. Линии связи в Интернет Информационный компонент в Интернете представлен сетевыми документами, то есть документами, хранящимися на компьютерах, подключенных к Сети или входящих в Сеть. Эти документы могут быть любого типа: текстовые, графические, звуковые (звукозаписи), видео (видеозаписи) и т. п..В настоящее время имеются опытные образцы, способные передавать тактильную (осязательную) информацию и ведутся работы в области передачи и воспроизведения обонятельной информации (запахов). Характерная особенность информационного компонента состоит в том, что он может быть распределенным. Так, например, при просмотре на экране книги, хранящейся в Интернете, текст может поступать из одних источников, звук и музыка — из других, графика — из третьих. Таким образом, первичные документы, хранящиеся в Сети, связаны между собой гибкой системой ссылок, которую создают авторы документов в том виде, в каком это им удобно для раскрытия своего замысла. В итоге образуется некое информационное пространство, состоящее из сотен миллионов взаимосвязанных между собой документов. Это пространство напоминает паутину. В нее можно войти со стороны любой нити, а дальше перемещаться между документами и исследовать паутину по собственному усмотрению. На первый взгляд, структура аппаратной части Интернета и структура информационного пространства очень похожи. И в том и в другом случае мы имеем дело с объектами, имеющими связь с другими объектами по принципу один — со многими. В аппаратном понимании Интернета каждый компьютер связан со многими компьютерами. Такая архитектура получила название Сеть (Net). В информационном понимании каждый документ тоже связан со многими документами, но в данном случае эта архитектура называется Паутиной (Web). На первый взгляд эти архитектуры одинаковы, однако применение разных терминов позволяет определить, где речь идет о совокупности компьютеров, a где — о пространстве документов, что далеко не одно и то же. На практике различие между физическим пространством Интернета и виртуальным информационным пространством документов проявляется в различных системах адресации. Каждый компьютер, входящий в состав Интернета, имеет адрес из четырех блоков, например: 183.45.231.97. Этот адрес называется IР-адресом. Компьютеры, входящие в Сеть на постоянной основе, имеют постоянный IP-адрес. Компьютеры пользователей, которые подключаются к Сети на время сеанса, получают временный IP-адрес, который действует только во время данного сеанса. Такой IP-адрес называется динамическим IP-адресом. Зная IP-адрес любой удаленной компьютерной системы, к ней можно обратиться с запросом:
- на поставку хранящихся в ней документов,
- на подключение к какой-либо программе,
- на использование оборудования, входящего в состав компьютерной системы.
Для информационного пространства документов характерна другая система адресации, основанная на понятии URL-адреса. Каждый документ, хранящийся во всемирной сети, имеет свой собственный уникальный адрес URL(Uniform Resource Locator — унифицированный указатель ресурса), примером которого является адрес официального сайта Брянского государственного университета http://www.brgu.ru. Если какой-то документ представлен в Сети не в единственном экземпляре, то у каждого экземпляра будет свой уникальный адрес URL. Двух документов с одинаковыми адресами в Интернете не может быть, точно так же, как на одном компьютере не может быть двух файлов с одинаковыми полными именами.
Как устроен интернет и при чём тут акулы

Слово «интернет» — это сокращение от английского словосочетания interconnected networks (взаимно соединённые сети). Инженеров во второй половине двадцатого века интересовало, как можно соединить компьютеры, чтобы объединить их вычислительные мощности и обмениваться информацией.
Первые разработки начались в США. В 1969 году учёные создали университетскую компьютерную сеть ARPANet, которая считается прототипом интернета. Разработчики соединили несколько компьютеров разных университетов. Позже, когда число компьютерных сетей выросло, возникла задача соединить между собой уже их.
Передавать информацию с одного компьютера на другой можно благодаря подводным кабелям — огромным проводам под водой, проложенным между континентами. Провода как бы «скрепляют» земной шар. Если посмотреть на карту интернет-кабелей, мы увидим, что она похожа на предшествующую ей карту телеграфа: провода проходят в тех же местах.

Как работает интернет?
Сначала пользователь вбивает адрес сайта в браузере. Информация нужного нам сайта находится на другом компьютере — на сервере. Чтобы получить эту информацию, браузеру нужно знать «адрес» компьютера, на котором она находится. Этот «адрес» называется IP-адрес. У каждого сервера он уникален.
Браузер отправляет запрос пользователя на DNS сервер — каталог всех IP-адресов. Его принцип работы можно сравнить с телефонной книгой. В нём доменные имена сайтов (например, google.com) соотносятся с IP-адресами (172.217.22.14, соответственно).
DNS-сервер даёт ответ: буквенному адресу интересующего вас сайта соответствует такой-то IP-адрес. И только тогда браузер отправляет на этот адрес запрос.
Тот в ответ отправляет файлы, и пользователь видит сайт, который он вбил в поисковую строку.
Почему сайтом может пользоваться много человек одновременно?
Интернет отличается от телефонной связи тем, что когда мы говорим по телефону, между нами и нашим собеседником открывается постоянно работающий канал связи. То есть никто третий в нашем разговоре просто так поучаствовать не может. Это называется «коммутация каналов». В Сети же принцип другой — «коммутация пакетов». Информация разбивается на кусочки, называемые пакетами. Это позволяет по одному каналу связи пересылать данные множества сайтов.
Как быстро работает браузер?
Промежуток времени, за который запрос с вашего компьютера достигает сервера и возвращается назад с необходимой информацией, называется ping. Для использования интернета в повседневных целях (например, скроллинга соцсетей) он не имеет значения.
Ping важен для геймеров и для видеоконференций. Если танк стреляет через секунду после нажатия на кнопку, можно проиграть. И, конечно, никто не любит, когда собеседник в Zoom-звонке вдруг замирает с открытым ртом. Ping больше 0,1 секунды считается медленным.
Почему реклама на сайтах знает так много?
Помимо того, что сервер выдаёт информацию по запросу пользователей, он также получает информацию о человеке, создавшем запрос. Например, где он находится. И вместе с информацией необходимого сайта отправляет человеку соответствующие его локации новости и другие материалы. Таким образом, он подстраивает контент под параметры пользователя.
Как работает веб-архив?
Изначально интернет задумывался как архив знаний человечества. Некоторые учёные и программисты хотели сделать так, чтобы всё, что попадает в интернет, осталось там навсегда. В 1996 году американские программисты Брюстер Кейл и Брюс Гиллиат решили, что нужно архивировать всё, что к этому моменту находилось в интернете.
Они создали Web Archive. Это сайт, хранящий информацию о других сайтах, веб-архив. Он работал благодаря технологии Web crawler, или «веб-паук». Это такой скрипт, который «оббегает» сайты и узнаёт, изменились ли они. Если сайт изменился, то «веб-паук» создаёт архивную копию. С 2001 года этот архив стал публичным. В некоторых странах, например, в Дании, есть и свои, национальные архивы интернета.
Сайты живут вечно?
Среднее время жизни интернет-страницы — год. Это логично объясняется тем, что владельцы сайта обычно оплачивают доменное имя сайта на год. Если его не оплачивать, у сайта забирают адрес, и он перестаёт существовать. Исследователи из Гарвардской школы права изучили сайт New York Times и установили, что 72% гиперссылок из материалов 1998 года «мертвы».
Акулы — главная опасность интернета?
Существует легенда, будто акулы представляют собой главную опасность для интернета, потому что перекусывают подводные кабели. Кабели действительно лежат под водой, и их относительно легко повредить. Однако под водой находится гораздо больше кабелей, чем нужно для стабильной работы интернета.

Даже если акула и повредит кабель, интернет продолжит работать. К тому же кабели находятся очень глубоко — акулы там не плавают. А вот телеграфные кабели они перекусывали часто.
Гораздо опаснее для интернета рыболовецкие судна. Они могут сбросить якорь и перебить несколько кабелей сразу. Так, например, недавно произошло в Великобритании.
То, что мы называем интернетом, — это, в сущности, соединённые проводами компьютеры. никаких облаков или виртуальной реальности.