- Команда cat в Linux
- Синтаксис команды Cat
- Отображение содержимого файла
- Перенаправить содержимое файла
- Печатать номера строк
- Подавить повторяющиеся пустые строки
- Отображение символов TAB
- Показать конец строк
- Объединение файлов
- Создание файлов
- Выводы
- Объединение файлов командой cat
- Простые советы в примерах по PHP, MySQL, HTML, CSS, JS и LINUX
- Объединить несколько файлов в один в Linux
- Комментарии
- Отправить комментарий
- Популярные сообщения из этого блога
- Как преобразовать строку в массив в ClickHouse / How to transform string to array in ClickHouse
- Как разложить массив на несколько строк в ClickHouse
- Экспорт одной таблицы базы данных или mysqldump одной таблицы (MySQL)
- join multiple files
- 8 Answers 8
Команда cat в Linux
Команда cat — одна из наиболее широко используемых команд в Linux. Имя cat команды происходит от его функциональности против кошачьих файлов Enate. Он может читать и объединять файлы, записывая их содержимое в стандартный вывод. Если файл не указан или если имя входного файла указано в виде одного дефиса ( — ), он считывается из стандартного ввода.
Cat чаще всего используется для отображения содержимого одного или нескольких текстовых файлов, объединения файлов путем добавления содержимого одного файла в конец другого файла и создания новых файлов.
В этом руководстве мы покажем вам, как использовать команду cat на практических примерах.
Синтаксис команды Cat
Прежде чем перейти к использованию команды cat, давайте начнем с обзора основного синтаксиса.
Выражения утилиты cat принимают следующую форму:
- OPTIONS — варианты кошек . Используйте cat —help чтобы просмотреть все доступные параметры.
- FILE_NAMES — Ноль или более имен файлов.
Отображение содержимого файла
Наиболее простое и распространенное использование команды cat — это чтение содержимого файлов.
Например, следующая команда отобразит содержимое файла /etc/issue в терминале:
Перенаправить содержимое файла
Вместо вывода вывода на стандартный вывод (на экране) вы можете перенаправить его в файл.
Следующая команда скопирует содержимое file1.txt в file2.txt с помощью оператора ( > ):
Если файл file2.txt не существует, команда создаст его. В противном случае он перезапишет файл.
Используйте оператор ( >> ), чтобы добавить содержимое file1.txt в file2.txt :
Как и раньше, если файла нет, он будет создан.
Печатать номера строк
Чтобы отобразить содержимое файла с номерами строк, используйте параметр -n :
1 DISTRIB_ID=Ubuntu 2 DISTRIB_RELEASE=18.04 3 DISTRIB_CODENAME=bionic 4 DISTRIB_DESCRIPTION="Ubuntu 18.04.1 LTS" Подавить повторяющиеся пустые строки
Используйте параметр -s чтобы пропустить повторяющиеся пустые выходные строки:
Отображение символов TAB
Параметр -T позволяет визуально различать табуляции и пробелы.
127.0.0.1^Ilocalhost 127.0.1.1^Iubuntu1804.localdomain Символы TAB будут отображаться как ^I
Показать конец строк
Чтобы отобразить невидимый символ окончания строки, используйте аргумент -e :
DISTRIB_ID=Ubuntu$ DISTRIB_RELEASE=18.04$ DISTRIB_CODENAME=bionic$ DISTRIB_DESCRIPTION="Ubuntu 18.04.1 LTS"$ Окончание строки будет отображаться как $ .
Объединение файлов
При передаче двух или более имен файлов в качестве аргументов команде cat содержимое файлов будет объединено. cat читает файлы в последовательности, указанной в его аргументах, и отображает содержимое файла в той же последовательности.
Например, следующая команда прочитает содержимое file1.txt и file2.txt и отобразит результат в терминале:
Вы можете объединить два или более текстовых файла и записать их в файл.
Следующая команда file1.txt содержимое file1.txt и file2.txt и запишет их в новый combinedfile.txt file2.txt с помощью оператора ( > ):
cat file1.txt file2.txt > combinedfile.txtЕсли combinedfile.txt файл не существует, то команда будет создавать. В противном случае он перезапишет файл.
Чтобы file1.txt содержимое file1.txt и file2.txt и добавить результат в file3.txt с помощью оператора ( >> ):
cat file1.txt file2.txt >> file3.txtЕсли файла нет, он будет создан.
При объединении файлов с помощью cat вы можете использовать те же аргументы, что и в предыдущем разделе.
Создание файлов
Создавать небольшие файлы с помощью cat часто проще, чем открывать текстовый редактор, такой как nano , Vim, Sublime Text или Visual Studio Code .
Чтобы создать новый файл, используйте команду cat за которой следует оператор перенаправления ( > ) и имя файла, который вы хотите создать. Нажмите Enter , введите текст и, когда закончите, нажмите CRTL+D чтобы сохранить файл.
В следующем примере мы создаем новый файл с именем file1.txt :
Если присутствует файл с именем file1.txt , он будет перезаписан. Используйте оператор « >> », чтобы добавить вывод в существующий файл.
Выводы
Команда cat может отображать, комбинировать и создавать новый файл.
Если у вас есть какие-либо вопросы или отзывы, не стесняйтесь оставлять комментарии.
Объединение файлов командой cat
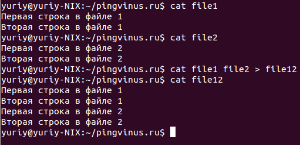
Команду cat в большинстве случаев используют только для просмотра файлов. На самом деле одно из ее предназначений это конкатенация (объединение) файлов. А название команды происходит от слова catenate (сцепить), то есть присоединение одного после другого.
Под объединением файлов понимается их соединение. Например, если мы имеем два текстовых файла и в одном из них записана строка:
My text file 1
А в другом:
My text file 2
То после объединения мы получим файл с двумя строками:
My text file 1
My text file 2
То есть происходит простое соединение файлов. К содержимому одного добавляется содержимое другого. Это касается не только текстовых файлов, но и всех остальных (бинарных, например).
Чтобы объединить два файла командой cat нужно просто указать в качестве аргументов названия этих файлов и направить результат выполнения в новый файл. Например, мы хотим объединить два файла file1 и file2, а результат записать в новый файл file12. Тогда мы должны выполнить следующую команду:
Вы можете объединить неограниченное количество файлов. Например, чтобы объединить четыре файла и записать результат в файл myfile, выполните команду:
cat file1 file2 file3 file4 > myfileПростые советы в примерах по PHP, MySQL, HTML, CSS, JS и LINUX
Простые советы разработки сайтов и приложений. Вы найдете ответы на вопросы, которые нельзя найти где-то ещё.
Объединить несколько файлов в один в Linux
- Получить ссылку
- Электронная почта
- Другие приложения
Для того, чтобы объединить несколько файлов в Linux, нужно воспользоваться командой cat.
- Получить ссылку
- Электронная почта
- Другие приложения
Комментарии
Отправить комментарий
Популярные сообщения из этого блога
Как преобразовать строку в массив в ClickHouse / How to transform string to array in ClickHouse
Сегодня я столкнулся с проблемой, что в документации ClickHouse нет функции преобразования строки в массив. Поискав в StackOverflow , я тоже ничего внятно не нашел. Попробую объяснить на примере: У вас есть некая колонка data типа String, которая хранит JSON: <"user_id":123456,"item_ids": [1203,1204,1205] ,"count":5>Вы хотите преобразовать поле item_ids в массив, чтобы в дальнейшем с ним производить любые функции по работе с массивами ( ссылка на документацию в конце поста ). Как преобразовать строку в массив из JSON Строка может содержать не в отдельной колонке, а, например, в поле json. Пример ниже продемонстрирует как этого добиться: С помощью функции visitParamExtractRaw достать значение поля item_ids в сыром виде: visitParamExtractRaw( data , ‘item_ids’ ) С помощью функции trim убрать лишние квадратные скобки по краям: trim ( BOTH ‘[]’ FROM visitParamExtractRaw( data , ‘reward_ids’ )) p.s. Можно также убрать и фигур
Как разложить массив на несколько строк в ClickHouse

Иногда возникает ситуация, когда нужно разложить поле, содержащее столбец-массив на несколько строк, то есть вынести в столбец каждый отдельный элемент массива. Другими словами: как разгруппировать колонку в несколько строк. Например, разложить колонку room_number на несколько строк. В примере ниже мы разложили колонку room_number на несколько строк для consumer_id = 1694953573. Получаем следующий результат: Как видим из примера выше, каждый элемент массива room_numbers теперь на отдельной строке. Делается это при помощи конструкции ARRAY JOIN. Синтаксис следующий: [ LEFT ] ARRAY JOIN < array >Вместо
Экспорт одной таблицы базы данных или mysqldump одной таблицы (MySQL)
Как экспортировать одну таблицу из базы данных MySQL, используя mysqldump Например, Вам нужно произвести экспорт всего одной таблицы из всей базы данных MySQL, существует довольно простая утилита mysqldump . Синтаксис довольно прост: mysqldump —user= [имя пользователя] —host= [имя хоста или ip-адрес] —password= [пароль] [имя базы данных] [имя таблицы] > имя-файла.sql Например: mysqldump —user-root —host=127.0.0.1 —pasword=mypassword mydbname table1 > report1.sql Вот и все, все оказалось просто. Весь дамп текущей таблицы, будет находиться в файле: report1.sql Экспорт структуры таблицы MySQL Если Вам нужно экспортировать только структуру таблицы базы данных, а сами данные не нужны, то нужно просто добавить флаг —no-data . Вот пример: mysqldump —user-root —host=127.0.0.1 —pasword=mypassword —no-data mydbname table1 > report2.sql Теперь в файле report2.sql будет только структура таблицы table1. Экспорт нескольких таблиц базы дан
join multiple files
I am using the standard join command to join two sorted files based on column1. The command is simple join file1 file2 > output_file. But how do I join 3 or more files using the same technique ? join file1 file2 file3 > output_file Above command gave me an empty file. I think sed can help me but I am not too sure how ?
8 Answers 8
NAME join - join lines of two files on a common field SYNOPSIS join [OPTION]. FILE1 FILE2 it only works with two files.
if you need to join three, maybe you can first join the first two, then join the third.
join file1 file2 | join - file3 > output that should join the three files without creating an intermediate temp file. — tells the join command to read the first input stream from stdin
One can join multiple files (N>=2) by constructing a pipeline of join s recursively:
#!/bin/sh # multijoin - join multiple files join_rec() < if [ $# -eq 1 ]; then join - "$1" else f=$1; shift join - "$f" | join_rec "$@" fi >if [ $# -le 2 ]; then join "$@" else f1=$1; f2=$2; shift 2 join "$f1" "$f2" | join_rec "$@" fi Definitely my favourite answer! However, I replaced the join_rec function’s body by this : f1=$1; f2=$2; shift 2; if [ $# -gt 0 ]; then; join «$f1» «$f2» | join_rec — «$@»; else; join «$f1» «$f2»; fi as to eliminate the need for the second if . The call would look like join_rec «$@»
I know this is an old question but for future reference. If you know that the files you want to join have a pattern like in the question here e.g. file1 file2 file3 . fileN Then you can simply join them with this command
Where output will be the series of the joined files which were joined in alphabetical order.
This works superb for text files. How about the binary files which have been split using other commands / packages / software.
well there you have probably some header in every file which indicates, what kind of file is it, so there is this not sufficient, but you should search for other so questions for this, i am sure someone solved it already
I created a function for this. First argument is the output file, rest arguments are the files to be joined.
function multijoin() < out=$1 shift 1 cat $1 | awk '' > $out for f in $*; do join $out $f > tmp; mv tmp $out; done > multijoin output_file file* While a bit an old question, this is how you can do it with a single awk :
awk -v j= ' # get key and delete field j (NR==FNR) # store the key-order # update key-entry END < for(i=1;i<=FNR;++i) < key=order[i]; print key entryОбъединить два файла linux # print >>' file1 . filen - all files have the same amount of lines
- the order of the output is the same order of the first file.
- files do not need to be sorted in field
- is a valid integer.
The man page of join states that it only works for two files. So you need to create and intermediate file, which you delete afterwards, i.e.:
> join file1 file2 > temp > join temp file3 > output > rm temp Join joins lines of two files on a common field. If you want to join more — do it in pairs. Join first two files first, then join the result with a third file etc.
Assuming you have four files A.txt, B.txt, C.txt and D.txt as:
~$ cat A.txt x1 2 x2 3 x4 5 x5 8 ~$ cat B.txt x1 5 x2 7 x3 4 x4 6 ~$ cat C.txt x2 1 x3 1 x4 1 x5 1 ~$ cat D.txt x1 1 firstOutput='0,1.2'; secondOutput='2.2'; myoutput="$firstOutput,$secondOutput"; outputCount=3; join -a 1 -a 2 -e 0 -o "$myoutput" A.txt B.txt > tmp.tmp; for f in C.txt D.txt; do firstOutput="$firstOutput,1.$outputCount"; myoutput="$firstOutput,$secondOutput"; join -a 1 -a 2 -e 0 -o "$myoutput" tmp.tmp $f > tempf; mv tempf tmp.tmp; outputCount=$(($outputCount+1)); done; mv tmp.tmp files_join.txt ~$ cat files_join.txt x1 2 5 0 1 x2 3 7 1 0 x3 0 4 1 0 x4 5 6 1 0 x5 8 0 1 0