3. Технология обработки данных в локальной сети
В зависимости от используемых технических и программных средств могут быть реализованы различные сетевые технологии. Технология обработки данных в локальных сетях организаций, предприятий во многом зависит от состава и функций серверов.
В ЛВС под сервером понимается компьютер или соответствующая программа. На одном выделенном компьютере-сервере ЛВС может функционировать несколько серверов-программ, например, коммуникационный сервер, сервер приложений. В больших корпоративных сетях с десятками, сотнями рабочих станций могут быть выделены серверы, которые «специализируются» на выполнении той или иной функции.
Сервер ЛВС – мощный, надежный компьютер, предназначенный для обработки запросов от сетевых рабочих станций, предоставляющий им доступ к общим ресурсам. Основные функции сервера ЛВС: «отвечает» за коммуникационные связи сетевых рабочих станций; организует доступ к общим сетевым ресурсам (дисковому пространству, принтеру, модему); выполняет прикладные программы, которые запускают пользователи со своих рабочих станций (технология “клиент-сервер”); обеспечивает одновременную совместную работу пользователей сети.
Сервер баз данных – компьютер, выполняющий функции хранения, обработки и управления файлами баз данных (используется промышленная СУБД).
Коммуникационный сервер – компьютер, предоставляющий клиентским компьютерам (рабочим станциям) сети доступ к модему, факс-модему, к Интернет по выделенной линии.
Сервер приложений – компьютер, используемый для выполнения прикладных программ (решения задач) пользователей сети. Обработка данных (решение задач) ведется не на сетевых рабочих станциях, а на сервере приложений.
Файловый сервер – компьютер, хранящий данные (файлы условно-постоянной и переменной информации) пользователей сети и обеспечивающий доступ к этим данным.
Концентрация в ЛВС баз данных и программ на сервере требует его надежности, достигаемой за счет повторного считывания с диска и сверки информации, выполнения всех операций спасения-восстановления информации при отключении питания без участия оператора, применения источника бесперебойного питания, оперативного обнаружения дефектных участков диска, появившихся в процессе работы, исключения их использования, использования «зеркального» (резервного) диска.
В ЛВС используют в основном две модели (архитектуры) взаимодействия сетевых рабочих станций и серверов: «файл-сервер» и «клиент-сервер».
Компьютер, управляющий ресурсами, называют сервером, а компьютер, желающий ими воспользоваться – клиентом.
В модели «файл-сервер» для получения сведений, например о поставщике, с сервера на рабочую станцию пользователя передается весь файл (справочник) поставщиков.
В модели «клиент-сервер» для получения сведений, например о поставщике, сервер находит сведения о нем и передает на рабочую станцию пользователя.
Передача с сервера на рабочие станции больших объемов информации в модели «файл-сервер» ведет к перегрузке сети. При использовании модели «клиент-сервер» объемы данных, передаваемых в сети, значительно меньше, чем при модели «файл-сервер». Между клиентом и сервером обмен идёт в основном кодами клавиш, событиями «мыши», фрагментами изображения (вводится необходимая информация).
Запрос, например, к базе данных, и получение результатов его обработки называют транзакцией. СУБД посредством механизма транзакций поддерживают одновременный доступ к данным многих пользователей, без возможности влияния каждого на результаты запросов. Каждая транзакция либо выполняется целиком, либо не выполняется вовсе (свойство атомарности). В этом случае производится операция, называемая откатом транзакции. Монитор транзакций и ОС следят за транзакциями и, в случае аварии сервера, при повторном его запуске ликвидируют все действия незавершенной транзакции (производят откат). Транзакции выполняются независимо одна от другой (свойство изолированности).
В локальных сетях с выделенным сервером, работающим под управлением сетевой (серверной) ОС Windows Server 2003/2008, Novell NetWare 5.х/6.х. и др. совместно используемые файлы хранятся на сервере, что облегчает их сопровождение, обеспечение целостности; возможно совместное использование одной копии программы, хранимой на сервере; возможна совместная групповая работа нескольких человек (рабочих станций) при подготовке документов; один модем может использоваться для приема/передачи данных с каждой рабочей станции, на высокоскоростном сетевом принтере выводятся на печать данные со всех или части рабочих станций ЛВС.
В корпоративных сетях для построения единого информационного пространства территориально-распределенного предприятия используются технологии удаленной и распределенной обработки данных. Первый вариант обеспечивает регистрацию, обработку и хранение информации на одном сервере БД всеми пользователями системы, в т.ч. работающими в удаленных филиалах. Он требует использования высокоскоростных каналов связи для передачи большого объема информации. При реализации второго варианта регистрация и обработка информации выполняется на нескольких серверах БД, установленных в каждом филиале. Второй вариант предполагает содержание в каждом филиале высокооплачиваемого администратора БД. Работа с информацией реализуется в рамках клиент-серверной архитектуры. Каждый пользователь запускает на своей рабочей станции клиентское приложение точно так же, как и при работе в локальной сети.
7 Системы обработки многопользовательских баз данных
Обработка данных – это совокупность методов и средств, осуществляющих преобразование данных. Она включает в себя ввод данных в компьютер, преобразование и отбор данных по каким-либо критериям и вывод данных в удобном для пользователя виде. Одновременно с развитием вычислительной техники развивались и следующие концепции обработки данных:
1 Обработка на мэйнфреймах в пакетном режиме. Для обработки данных в этом режиме пользователь составлял задания на выполнение определенных операций над исходной программой и/или счет по программе. Исходная программа – это программа, написанная на алгоритмическом языке.
Задания, записанные на специальном языке описания заданий, а также текст программы и исходные данные наносились на бумажный носитель – перфокарты, которые формировались в пакет заданий. Пользователи передавали свои пакеты заданий в вычислительный центр на обработку на мэйнфрейме. Распечатанные результаты пользователи получали обычно только на следующий день. Отсутствие непосредственного контакта пользователя с компьютером и использование перфокарт увеличивали время получения результата обработки.
2 Обработка в многотерминальных системах. Такие системы появились по мере удешевления компьютеров в начале 1960-х гг. и позволили пользователям непосредственно общаться с компьютером. К мэйнфрейму, расположенному на вычислительном центре, были подключены терминалы, рассредоточенные по всему предприятию. Терминал – это устройство, предназначенное для взаимодействия с вычислительной системой или сетью ЭВМ. Первоначально терминалы были неинтеллектуальным, не имели собственных вычислительных ресурсов, а осуществляли только операции ввода-вывода.
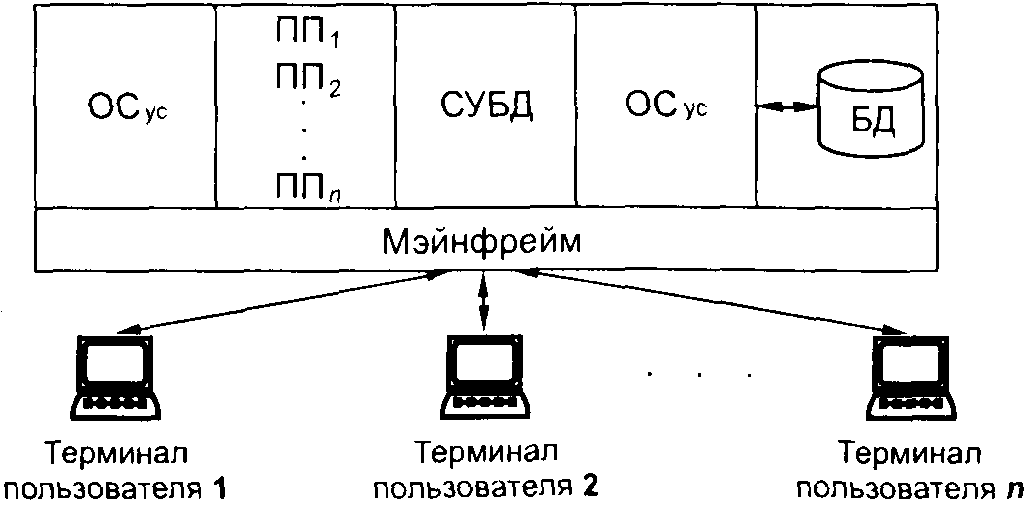
Пользователи с помощью терминалов передавали запросы к базе данных. Часть операционной системы, отвечающая за управление связью (ОСус), принимала их и передавала соответствующим прикладным программам (ПП), которые обращались к СУБД, а она выполняла операции с базой данных, используя часть операционной системы, отвечающую за управление данными (ОСуд). Результаты запросов возвращались пользователям, находящимся у терминалов, подсистемой управления связью. Многотерминальные системы называют еще системами удаленной обработки данных.
Пользовательские запросы обрабатывались в режиме разделения времени. Время обработки было достаточно мало, и пользователь не замечал параллельной работы с мэйнфреймом других пользователей. У него создавалась иллюзия единоличного владения компьютером.
3 Обработка на автономных персональных компьютерах. Она стала возможной в 1980-е гг. в связи с появлением этой техники. На персональном компьютере (ПК) устанавливалась СУБД, с помощью которой пользователь создавал на данном компьютере свою локальную базу данных и работал с ней в однопользовательском режиме. Такая СУБД называлась настольной. Она была ответственна за выполнение запросов и поддержание целостности базы данных. К аппаратному обеспечению компьютера предъявлялись скромные требования. Данные передавались с компьютера на компьютер на внешних носителях – дискетах. Настольные СУБД были просты для освоения и использования, обладали понятным пользовательским интерфейсом, ориентировались на самую широкую категорию пользователей – непрофессионалов, обеспечивали хорошее быстродействие при работе с небольшими базами данных.
4 Обработка с использованием компьютерных сетей. Основная концепция такой обработки заключается в обмене данными между компьютерами в автоматическом режиме посредством линий связи и специального оборудования. В первых компьютерных сетях были реализованы службы обмена файлами, синхронизации файлов (устранение различий между файлом, хранящимся на одном компьютере, и версией того же файла на другом компьютере), электронной почты и другие сетевые службы, ставшие теперь традиционными.
ПК стали идеальными элементами для построения сетей. С одной стороны, они были достаточно мощными для работы сетевого программного обеспечения, а с другой – не очень дорогими. При их объединении совокупная вычислительная мощность оказывалась достаточной для решения сложных задач, и стало возможным совместное использование периферийных устройств (например, принтеров) и дисковых массивов (RAID-массивов). Поэтому ПК стали преобладать в локальных сетях, причем в качестве не только компьютеров пользователей, но и центров хранения и обработки данных, потеснив с этих привычных ролей мэйнфреймы. Обработка данных с использованием компьютерных сетей является в настоящее время наиболее распространенной. При этом наблюдается тенденция к унификации технологий обработки данных в локальных сетях и в глоб. сети Интернет.
7.3 Системы совместного использования файлов
7.3.1 Обработка запросов в архитектуре файл/сервер
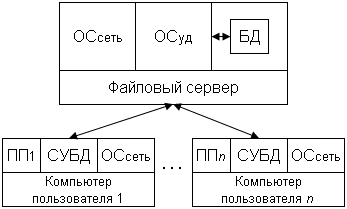
7.3.2 Обработка запросов в архитектуре клиент/сервер