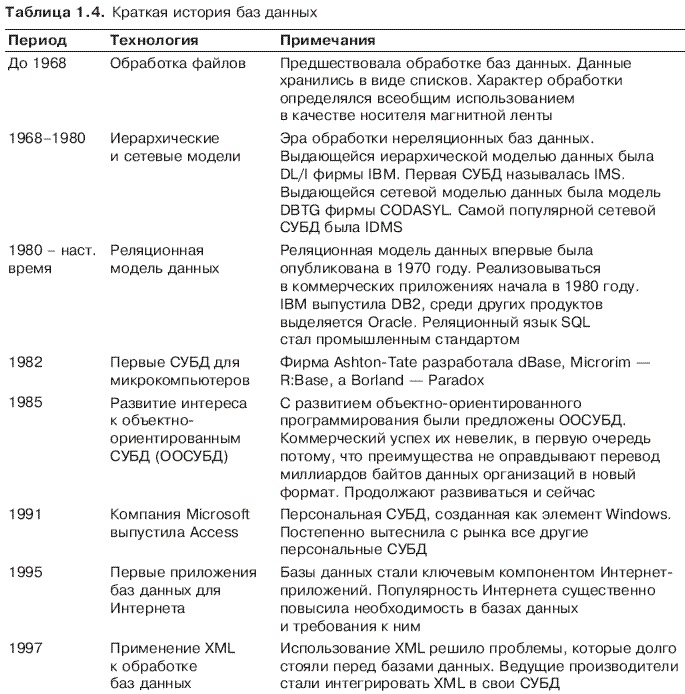
2. Модели организации данных
В иерархической модели объекты-сущности и отношения предметной области представляются наборами данных, которые имеют древовидную (иерархическую) структуру. Иерархическая модель данных была исторически первой. На ее основе в конце 60-х — начале 70-х годов были разработаны первые профессиональные СУБД.
Пример структуры иерархической БД приведен на рис. 5.1.
Основное внимание в ограничениях целостности в иерархической модели уделяется целостности ссылок между предками и потомками с учетом основного правила: никакой потомок не может существовать без родителя.
Сетевая модель данных позволяет отображать разнообразные взаимосвязи элементов данных в виде произвольного графа. Сетевая БД состоит из набора записей и набора соответствующих связей. На формирование связи особых ограничений не накладывается. Если в иерархических структурах запись-потомок могла иметь только одну запись-предка, то в сетевой модели данных запись-потомок может иметь произвольное число записей-предков.
Достоинством сетевой мидели данных является возможность ее эффективной реализации. В сравнении с иерархической моделью сетевая модель предоставляет бульшие возможности в смысле допустимости образования произвольных связей.
Недостатком сетевой модели данных является высокая сложность и жесткость схемы БД, построенной на ее основе, а также сложность ее понимания обычным пользователем. Кроме того, в сетевой модели данных ослаблен контроль целостности связей из-за допустимости установления произвольных связей между записями.
Системы на основе сетевой модели не получили широкого распространения на практике.
Реляционная модель данных предложена сотрудником фирмы IВМ Эдгаром Коддом и основывается на понятии отношения (relation).
Отношение представляет собой множество элементов, называемых кортежами. Наглядной формой представления отношения является двумерная таблица.
С помощью одной таблицы удобно описывать простейший вид связей между данными, а именно: деление одного объекта, информация о котором хранится в таблице, на множество подобъектов, каждому из которых соответствует строка или запись таблицы.
Основными недостатками реляционной модели являются следующие: отсутствие стандартных средств идентификации отдельных записей и сложность описания иерархических и сетевых связей.
3. Реляционные базы данных
Реляционная модель данных (РМД) некоторой предметной области представляет собой набор отношений, изменяющихся во времени. При создании информационной системы совокупность отношений позволяет хранить данные об объектах предметной области и моделировать связи между ними. Термины РМД представлены в табл. 5.1
Таблица 5.1 Термины реляционной модели
Термин реляционной модели
Лекция №2
В иерархической модели объекты-сущности и отношения предметной области представляются наборами данных, которые имеют древовидную (иерархическую) структуру. Иерархическая модель данных была исторически первой. На ее основе в конце 60-х — начале 70-х годов были разработаны первые профессиональные СУБД.
Пример структуры иерархической БД приведен на рис. 5.1.
Основное внимание в ограничениях целостности в иерархической модели уделяется целостности ссылок между предками и потомками с учетом основного правила: никакой потомок не может существовать без родителя.
Сетевая модель данных позволяет отображать разнообразные взаимосвязи элементов данных в виде произвольного графа. Сетевая БД состоит из набора записей и набора соответствующих связей. На формирование связи особых ограничений не накладывается. Если в иерархических структурах запись-потомок могла иметь только одну запись-предка, то в сетевой модели данных запись-потомок может иметь произвольное число записей-предков.
Достоинством сетевой мидели данных является возможность ее эффективной реализации. В сравнении с иерархической моделью сетевая модель предоставляет бульшие возможности в смысле допустимости образования произвольных связей.
Недостатком сетевой модели данных является высокая сложность и жесткость схемы БД, построенной на ее основе, а также сложность ее понимания обычным пользователем. Кроме того, в сетевой модели данных ослаблен контроль целостности связей из-за допустимости установления произвольных связей между записями.
Системы на основе сетевой модели не получили широкого распространения на практике.
Реляционная модель данных предложена сотрудником фирмы IВМ Эдгаром Коддом и основывается на понятии отношения (relation).
Отношение представляет собой множество элементов, называемых кортежами. Наглядной формой представления отношения является двумерная таблица.
С помощью одной таблицы удобно описывать простейший вид связей между данными, а именно: деление одного объекта, информация о котором хранится в таблице, на множество подобъектов, каждому из которых соответствует строка или запись таблицы.
Основными недостатками реляционной модели являются следующие: отсутствие стандартных средств идентификации отдельных записей и сложность описания иерархических и сетевых связей.
3. Реляционные базы данных
Реляционная модель данных (РМД) некоторой предметной области представляет собой набор отношений, изменяющихся во времени. При создании информационной системы совокупность отношений позволяет хранить данные об объектах предметной области и моделировать связи между ними. Термины РМД представлены в табл. 5.1
Таблица 5.1 Термины реляционной модели
Термин реляционной модели Эквивалентный термин
Схема отношения Строка заголовков столбцов таблицы (заголовок таблицы)
Кортеж Строка таблицы, запись
Сущность Описание свойств объекта
Домен Множество допустимых значений атрибута
Первичный ключ Уникальный идентификатор
Кардинальность Количество строк
Степень Количество столбцов
Реляционная база данных представляет собой хранилище данных, содержащее набор двухмерных таблиц. Данные в таблицах должны удовлетворять следующим принципам.
1. Значения атрибутов должны быть атомарными (иными словами,
каждое значение, содержащееся на пересечении строки и колонки,
должно быть не расчленяемым на несколько значений).
2. Значения каждого атрибута должны принадлежать к одному и тому же типу.
3. Каждая запись в таблице уникальна.
4. Каждое поле имеет уникальное имя.
5. Последовательность полей и записей в таблице не существенна.
Отношение является важнейшим понятием и представляет собой
двумерную таблицу, содержащую некоторые данные.
Сущность есть объект любой природы, данные о котором хранятся в базе данных. Данные о сущности хранятся в отношении.
Атрибуты представляют собой свойства, характеризующие сущность. В структуре таблицы каждый атрибут именуется и ему соответствует заголовок некоторого столбца таблицы.
Ключом отношения называется совокупность его атрибутов, однозначно идентифицирующих каждый из кортежей отношения. Иными словами, множество атрибутов К, являющееся ключом отношения, обладает свойством уникальности. Следующее свойство ключа — неизбыточность. То есть никакое из собственных подмножеств множества К не обладает свойством уникальности.
Каждое отношение всегда имеет комбинацию атрибутов, которая может служить ключом. Ее существование гарантируется принципом № 3 РМД. По крайней мере, вся совокупность атрибутов обладает свойством уникальности.
Возможны случаи, когда отношение имеет несколько комбинаций атрибутов, каждая из которых однозначно определяет все кортежи отношения. Все эти комбинации атрибутов являются возможными ключами отношения. Любой из возможных ключей может быть выбран как первичный.
Ключи обычно используют для достижения следующих целей:
» исключения дублирования значений в ключевых атрибутах (остальные атрибуты в расчет не принимаются);
» упорядочения кортежей. Возможно упорядочение по возрастанию или убыванию значений всех ключевых атрибутов, а также смешанное упорядочение (по одним — возрастание, а по другим — убывание);
» организации связывания таблиц.
Важным является понятие внешнего ключа. Внешний ключ можно определить как множество атрибутов одного отношения R2, значения которых должны совпадать со значениями возможного ключа другого отношения R1.
Атрибуты отношения К2, составляющие внешний ключ, не являются ключевыми для данного отношения.
С помощью внешних ключей устанавливаются связи между отношениями.
Ограничения целостности реляционной модели можно разделить на две группы — ограничения целостности сущностей и ограничения целостности ссылок.
Ограничения целостности сущностей заключаются в требовании уникальности кортежей отношения (записей таблицы). Отсюда вытекают следующие ограничения:
» отсутствие кортежей-дубликатов (данное требование предъявляется лишь к атрибутам первичных ключей);
» отсутствие атрибутов с множественным характером значений.
Ограничения целостности ссылок заключаются в том, что для любой записи с конкретным значением внешнего ключа должна обязательно существовать запись связанной таблицы-отношения с соответствующим значением первичного ключа.
К отношениям можно применять систему операций, позволяющую получать одни отношения из других. Например, результатом запроса к реляционной БД может быть новое отношение, вычисленное на основе имеющихся отношений. Поэтому можно разделить обрабатываемые данные на хранимую и вычисляемую части.
Основной единицей обработки данных в реляционных БД является отношение, а не отдельные его кортежи (записи).
Отсутствие упорядоченности записей в таблицах усложняет поиск. На практике с целью быстрого нахождения нужной записи вводят индексирование полей (обычно ключевых). Создание индексных массивов заключается в построении дополнительной упорядоченной информационной структуры для быстрого доступа к записям.
Как для самих таблиц, так и для индексных массивов применяются линейные и нелинейные структуры. В качестве линейных структур индексных массивов в большинстве случаев выступают инвертированные списки. Инвертированный список строится по схеме таблицы с двумя колонками — «Значение индексируемого поля» и «Номера строк» рисунок.
Значение индексируемого поля («год рождения») Номера строк
Рис. Пример инвертированного списка
Инвертированные списки чаще всего применяются для индексации полей, значения которых в разных записях могут повторяться. В этом случае количество ситуаций, при которых требуется добавление или удаление строк индекса, невелико и затраты на переупорядочение индекса при изменениях данных в базовой таблице незначительны.
Строки инвертированного списка упорядочиваются по значению индексируемого поля. Для доступа к нужной записи исходной таблицы сначала в упорядоченном инвертированном списке отыскивается строка с требуемым значением поля, затем считываются номера соответствующих записей основной таблицы, к которым осуществляется доступ по этим номерам.
Нелинейные структуры индексов применяются для создания индексных массивов ключевых полей или тех полей, значения по которым не повторяются. При организации индексов в таких случаях чаще всего используются древовидные иерархические структуры в виде В-деревьев.