7.2.2. Сетевая модель данных
В сетевой модели при тех же основных понятиях (уровень, узел, связь) каждый порожденный элемент может быть иметь более одного порождающего элемента.
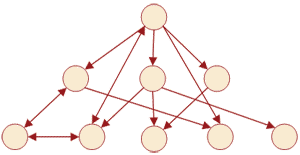
Рис. 7.2.2.1. Сетевая модель данных
Сетевая модель отличается большей гибкостью, чем иерархическая, так как в ней существует возможность устанавливать дополнительно к вертикальным иерархическим связям горизонтальные связи. Это облегчает процесс поиска требуемых элементов данных, так как уже не требуется обязательное прохождение всех предшествующих ступеней.
Примером сетевой структуры может служить структура базы данных, содержащей сведения о студентах, участвующих в научно-исследовательских работах (НИРС). Возможно участие одного студента в нескольких НИРС, а также участие нескольких студентов в разработке одной НИРС.

Рис. 7.2.2.2. Принцип построения сетевой модели организации БД.
7.2.3. Реляционная модель данных
Можно доказать, что и иерархическую, и сетевую структуры данных можно преобразовать в двумерную таблицу. Такое представление является наиболее удобным и для пользователя, и для компьютера, – подавляющее большинство современных информационных систем работает именно с такими таблицами. Базы данных, которые состоят из двумерных таблиц, называют реляционными.
Основная идея реляционного подхода состоит в том, чтобы представить произвольную структуру данных в виде двумерной таблицы или, как говорят, нормализовать структуру. Нормализация – это процесс прохода по веткам иерархического дерева с целью разместить листочки» со всеми их узлами и ветками в отдельных строках таблицы.
Основы теории реляционных БД разработал в 70-х годах XX века Э.Кодд (США).
Основными понятиями реляционной модели данных являются сущность, отношение, атрибут и кортеж.
Сущность – это конкретный объект реального мира в какой-либо предметной области. т.е. объектом можно назвать то «нечто», для которого существуют название и способ отличить один подобный объект от другого. Например, каждый ВУЗ – это объект. Объектами также являются человек, фирма, сплав, химическое соединение и т. д. Объектами могут быть не только материальные предметы, но и более абстрактные понятия, отражающие реальный мир, например, события, произведения искусства, правовые нормы, научные теории и пр.
Группы всех подобных объектов образует набор объектов. Например, наборами объектов могут быть факультеты ВУЗа, товары на складе, люди, работающие на предприятии. Конкретный объект в такой группе называют экземпляром объекта.
Данные о сущности хранятся в двумерных таблицах, которые называются реляционными. Формальное построение таблиц связано с фундаментальным понятием отношение (от английского слова relation – отношение).
Каждая строка таблицы представляет собой одну запись файла данных, каждый столбец – одно поле.

Рис. 7.2.3.1. Структура табоицы базы данных
Атрибут (или данное) – это некоторый показатель, который характеризует некий объект и принимает для конкретного экземпляра объекта некоторое числовое, текстовое или иное значение. Например, возьмем в качестве набора объектов группы факультета. Число студентов в группе – это атрибут, который принимает числовые значения (у одной группы 25, у другой 18). Название группы – это атрибут, который принимает текстовые значения (у одной – ФК-11, у другой – ЭКО-12 и т.д.).
Очень часто в современных информационных системах используются «качественные» данные об объектах, например рейтинг (фильма, спортсмена, политика), увлечения человека, его темперамент.
Атрибут некоторого набора объектов сам может быть набором объектов, имеющим собственные атрибуты. Например, атрибутом человека (как экземпляра набора объектов «Люди») является ВУЗ, который этот человек окончил (МГУ, МарГТУ и т.п.). С другой стороны, конкретный ВУЗ – это экземпляр набора объектов «Вузы» и характеризуется множеством данных: фамилия ректора, адресом, специализацией, количеством студентов и т.д. Наконец, ректор, в свою очередь – это экземпляр набора объектов «Люди». Таким образом, возникает возможность установления связи между экземплярами объектов из разных наборов.
Списки возможных значений атрибутов называются классификаторами (справочниками, словарями). Например, страна, гражданином которой является конкретное лицо, служит атрибутом этого лица. Список всех стран планеты – это и есть классификатор, из которого выбирают значение атрибута для конкретного лица.
Иногда для конкретного объекта один и тот же атрибут может принимать несколько значений. Например, одна фирма изготавливает разные виды продукции, один человек может иметь несколько увлечений и т. п. Такие данные образуют так называемые повторяющиеся группы.
Значения некоторых данных постоянны у конкретных объектов (например, год рождения человека); значения других могут меняться с течением времени (например, образование человека, его должность, число работающих на предприятии и т.п.).
Кортеж – это элемент отношения , строка таблицы; упорядоченный набор из N элементов.
Хотя любое отношение можно изобразить в виде таблицы, нужно четко понимать, что отношения не являются таблицами. Это близкие, но не совпадающие понятия. Термины, которыми оперирует реляционная модель данных, имеют соответствующие «табличные» синонимы:
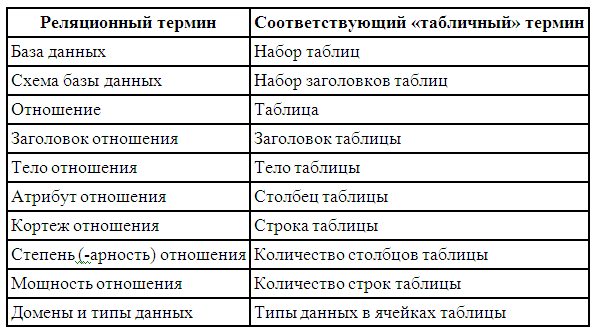
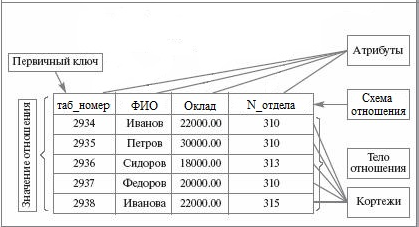
Рис. 7.2.3.2. Основные понятия баз данных
- В отношении нет одинаковых кортежей.
- Кортежи не упорядочены (сверху вниз).
- Все атрибуты содержат однородные по типу данные.
- Имена атрибутов должны быть уникальны в пределах отношения.
- Атрибуты не упорядочены (слева направо).
Сетевая модель данных
Сетевая модель данных является развитием иерархической модели. В сетевой модели, так же как и в иерархической модели, есть понятие элемента данных и связи, которая может быть именована. Главное отличие сетевой модели от иерархической заключается в том, что к каждому элементу может идти связь не от одного элемента (“родителя”), а от нескольких.
Например, генеалогическое дерево, построенное только по мужской линии (или, только по материнской), является древовидной, иерархической структурой — у каждого человека (элемента), есть только один родитель. Если же включать в генеалогическое дерево всех родителей, то такое дерево с точки зрения структур данных будет уже не деревом, а сетью:
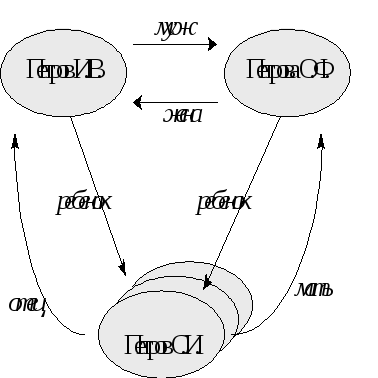
Рис.2.3. Представление фрагмента генеалогического дерева на основе сетевой модели данных
На данном рисунке представлены элементы только одно класса — описание людей, и на этом множестве для некоторых конкретных пар людей существуют связи, именуемые “муж”, “жена”, “отец”, “мать”, “ребенок”. Поэтому с точки зрения графического представления схемы этой базы данных (а не конкретных данных о семье Петровых), можно использовать следующий рисунок:
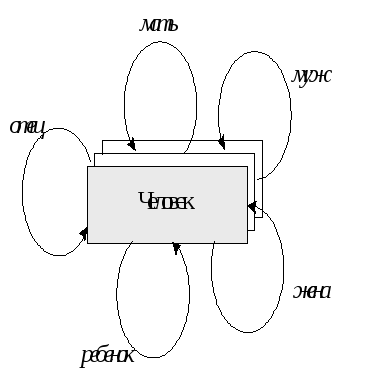
Рис.2.4. Представление схемы базы данных генеалогического дерева на основе сетевой модели данных
Сетевая модель данных основывается на понятии элемента данных и связей, задающих логику взаимоотношениями между данными. Связи от каждого элемента могут быть направлены на произвольное количество других элементов. На каждый элемент могут быть направлены связи от произвольного числа других элементов. Каждый элемент данных описывает некоторое понятие из предметной области и характеризуется некоторыми атрибутами. Для каждого элемента данных (элемент — это часть схемы) в реальной базе данных может существовать несколько экземпляров этого элемента. С каждым конкретным экземпляром по конкретной связи может быть связано разное число экземпляров другого элемента (например, у каждого человека разное число детей), но число видов связи одинаково для всех экземпляров одного элемента.
Если мы вернемся к нашему примеру про издательства тематических сборников (этот пример рассматривался в разделе про иерархические СУБД) и попытаемся расширить его, для того чтобы он более полно соответствовал реальным взаимоотношениям, то схема базы данных будет выглядеть следующим образом:
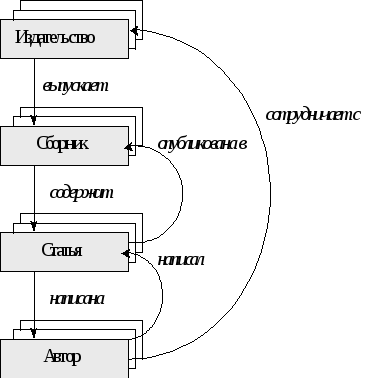
Рис.2.5. Представление расширенной схемы базы данных для описания издательств на основе сетевой модели
К достоинствам сетевой модели относится очень высокая скорость поиска и возможность адекватно представлять многие задачи в самых разных предметных областях. Высокая скорость поиска основывается на классическом способе физической реализации сетевой модели — на основе списков.
Главным недостатком сетевой модели, как, впрочем, и иерархической, является ее жесткость. Поиск данных, доступ к ним, возможен только по тем связям, которые реально существуют в данной конкретной модели. При поиске данных сетевая СУБД требует перемещаться только по существующим, заранее предусмотренным связям.
Сетевая модель данных и ее характеристики. Понятие набора
Сетевая модель данных позволяет отображать разнообразные взаимосвязи элементов данных в виде произвольного графа, обобщая тем самым иерархическую модель данных (рис. 2.4). Наиболее полно концепция сетевых БД впервые была изложена в Предложениях группы КОДАСИЛ (KODASYL).
Рис. 2.4. Представление связей в сетевой модели
Для описания схемы сетевой БД используется две группы типов: «запись» и «связь». Тип «связь» определяется для двух типов «запись»: предка и потомка. Переменные типа «связь» являются экземплярами связей. Сетевая БД состоит из набора записей и набора соответствующих связей. На формирование связи особых ограничений не накладывается. Если в иерархических структурах запись-потомок могла иметь только одну запись-предка, то в сетевой модели данных запись-потомок может иметь произвольное число записей-предков (сводных родителей). Пример схемы простейшей сетевой БД показан на рис. 2.5. Типы связей здесь обозначены надписями на соединяющих типы записей линиях.

Рис. 2.5. Пример схемы сетевой БД

Рис. 2.5. Пример схемы сетевой БДВ различных СУБД сетевого типа для обозначения одинаковых по сути понятий зачастую используются различные термины. Например, такие, как элементы и агрегаты данных, записи, наборы, области и т. д. Физическое размещение данных в базах сетевого типа может быть организовано практически теми же методами, что и в иерархических базах данных. К числу важнейших операций манипулирования данными баз сетевого типа можно отнести следующие: поиск записи в БД; переход от предка к первому потомку; переход от потомка к предку; создание новой записи; удаление текущей записи; обновление текущей записи; включение записи в связь; исключение записи из связи; изменение связей и т. д. Достоинством сетевой модели данных является возможность эффективной реализации по показателям затрат памяти и оперативности. В сравнении с иерархической моделью сетевая модель предоставляет большие возможности в смысле допустимости образования произвольных связей. Недостатком сетевой модели данных является высокая сложность и жесткость схемы БД, построенной на ее основе, а также сложность для понимания и выполнения обработки информации в БД обычным пользователем. Кроме того, в сетевой модели данных ослаблен контроль целостности связей вследствие допустимости установления произвольных связей между записями. Системы на основе сетевой модели не получили широкого распространения на практике. Наиболее известными сетевыми СУБД являются следующие: IDMS, db VistaIII, СЕТЬ, СЕТОР и КОМПАС.
Набор –это структура данных, которая отображает связи меду объектами в предметной области. Каждый набор содержит единственную запись, называемую владельцем набора, и множество записей, называемых членами набора. Наборы, имеющие одинаковый тип владельца и одинаковый тип члена, а также обладающие одинаковой семантикой (смыслом), объединяются в тип набора, который имеет уникальное имя.