Работа с linux. Пайплайны
Привет, сегодня продолжение небольшой заметки по командной строке. Начало здесь. Сегодня про конвеер∕пайплайн, управление потоками и немного о том как их скрещивать.
При старте любой программы операционная система связывает с ней 3 потока:
- Входящие данные (Standart input, STDIN)
- Выходные данные (Standart output, STDOUT)
- Данные об ошибках (Standart error, STDERR)
Для языка программирования эти потоки — просто файлы. Операционная система сама решит куда вывести результат и как в дальнейшем взаимодействовать с этими данными.
У потоков есть свои номера:
Зная это можно манипулировать данными и перенаправлять потоки. Например мы можем собрать ошибки в файл и вести своеобразный лог:
2>&1 позволяет перенаправить поток, отвечающий за ошибки в вывод и сохранить это все в файл output. При этом можно перенаправить в файл сразу оба потока с помощью &>some_file.
символ > позволяет перезаписать данные.
символ >> позволяет добавить данные в конец файла. Если заменить > на >> второй раз использовать команду, то в файле уже будет не одна запись а две.
Это все поможет, понять как работает конвеер (PIPELINE) .
Конвеер∕пайплайн позволяет протаскивать данные через цепочки команд.
Команды соединяются с помощью символа `|`. Выход данных одной команды подается на вход в другую. Так вы сможете разбить исполнение одной сложной программы на N простых операций, которыми будет гораздо проще управлять.
Один из самый простых примеров, который я периодически использую — поиск как-либо команды, которую уже использовал в терминале, но делал это достаточно давно, чтобы просто проматывать последние подключения.
Порядок выполнения такой: history читает информацию из файла с историей команд, введенных в терминал и передает её в grep, которая находит все строки, в которых использовалась команда подключения по ssh. Найденные данные уходят в tail, которая ограничивает вывод 5 строками.
За построением пайплайнов кроется несколько достаточно глубоких идей:
- Пишите программы, которые будут делать что-то одно и делать это хорошо.
- Пишите программы, которые будут работать вместе.
- Пишите программы, которые поддерживают текстовые потоки, т.к. это универсальный интерфейс.
На этом на сегодня всё) Последнее время поковыриваю питоновские кишки, в следующей заметке скорее всего будет перевод заметки о работе сборщика мусора. Будем разбираться как в Python считаются ссылки и когда он выкидывает объекты из памяти.
pipeline in linux/unix with examples
Pipeline technology is an inter-process communication technology in Linux and other Unix-like operating systems, similar to redirection, which transmits standard output to other target locations.
Linux pipe are used for communication between applications, between Linux commands, and between applications and commands.
Linux pipe symbol is the vertical bar symbol “|”, pipe communication format between commands:
command1 | command 2 | command3 | . | commandN Command1 to commandN represent N commands of linux.
These N commands use pipes to communicate. After the execution of command1 is completed, the execution result of command1 is used as the input parameter of command2 through the pipeline, and so on.
Pipeline usage examples
In the following examples, we will use multiple commands to communicate through the pipeline to achieve our ultimate goal.
tail, pipeline and grep command example
When we are dealing with problems, we often need to monitor the content of log files with specific identifiers in real time.
In the following example, we will need to use the tail -f command to monitor real-time log updates, and pass the updated log content as input parameters to the grep command through the pipeline, and search the pipeline input content through the grep command.
➜ ~ tail -f pipeFile.log | grep "test"
awk, pipeline and sort command example
In the following example, we want to count the value of the first occurrence of the string in the first column of the test file divided by “#”.
We first need to use awk to cut and use the awk execution result as the input parameter of the sort command through the channel. After the sorting is completed, the uniq command is executed through the channel.
➜ ~ awk -F'#' '' pipeFile.log | sort | uniq -c | sort -r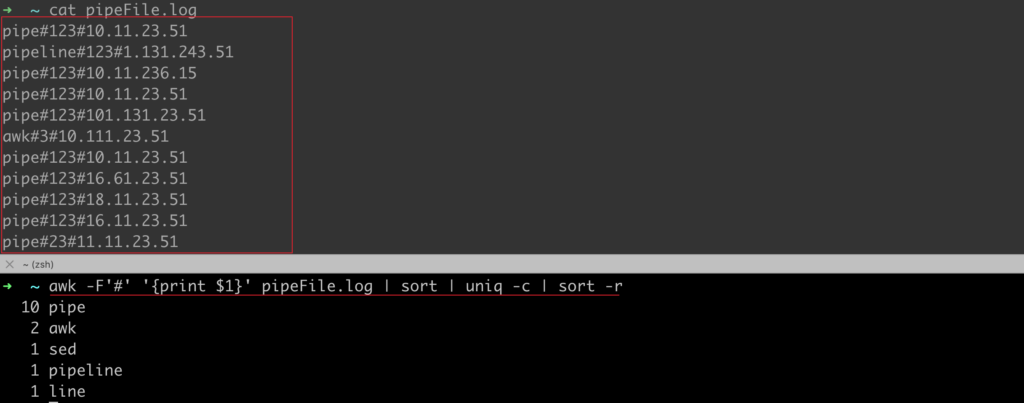
ls, pipe and grep command example
In the following example, we will use the ls command, pipeline, and grep command to query files or folders with the keyword “test” in the current directory.