Тема 15: Реализация ввода-вывода в системе linux
Функция драйвера заключается в изолировании остальной части системы от особенностей аппаратного обеспечения. При помощи стандартных интерфейсов между драйверами и остальной операционной системой основная часть системы ввода-вывода может быть помещена в машинно-зависимую часть ядра.
Когда пользователь обращается к специальному файлу, (виртуальная) файловая система определяет номер старшего и младшего устройств, а так же выясняет, является ли файл блочным специальным файлом или символьным специальным файлом. Номер старшего устройства используется в качестве индекса для одной из двух внутренних хэш-таблиц, содержащих структуры данных для блочных или символьных специальных файлов. Найденная таким образом структура содержит указатели на процедуры открытия устройства, чтения из устройства, записи и т.д. Номер младшего устройства передается в виде параметра. Добавление нового типа устройства в системе linux означает добавление нового элемента к одной из этих таблиц, а так же предоставления соответствуюших процедур выполнения, различных операций с устройством. Каждый драйвер разделен на 2 части, причем обе они являются частью ядра linuxи работают в режиме ядра. Верхняя часть драйвера работает в контексте вызывающей стороны и служит интерфейсом к остальной системе linux. Нижняя часть работает в контексте ядра и взаимодействует с устройствами. Драйверам разрешается делать вызовы процедур ядра для выделения памяти, управления таймерами. Набор функций ядра, который они могут вызывать определен в документе под названием интерфейс-драйвер-ядро (Driver-Kernel-Interface). Система ввода-вывода занимается обработкой блочных специальных файлов и символьных специальных файлов.
1. Обработка блочных специальных файлов.
Главная цель при работе с данными файлами заключается в минимизации количества операций передачи данных. Для достижения данной цели в linux-системах между дисковыми драйверами и файловой системой имеется кэш. Кэш представляет собой таблицу в ядре, в которой хранятся тысячи недавно использованных блоков. Когда файловой системе требуется блок диска, то сначала проверяется кэш. Если нужный блок есть в кэше, то он берется оттуда, при этом обращения к диску удается избежать. Если же блока в кэше нет, то он считывается с диска в кэш и оттуда копируется в место назначения. Кэш страниц работает не только при чтении, но и при записи. Когда программа пишет блок, то этот блок не попадает напрямую на диск, а отправляется в кэш. В любой другой системе ОС linux существует решение проблемы излишних перемещений дисковых головок. Для решения этой проблемы в linuxиспользуется планировщик ввода-вывода. Цель планировщика – переупорядочить или собрать в пакеты запросы ввода вывода к блочному устройству. Базовый планировщик linux основан на исходном планировщике LinusElevatorScheduler. Он работает следующим образом:
Дисковые операции сортируются в дважды связанном списке, упорядоченном по адресам сектора дискового запроса. Новые запросы вставляются в этот отсортированный список. Это позволяет избежать излишних перемещений дисковых головок. Этот список запросов затем объединяется, чтобы смежные операции выполнялись за один запрос к диску.
2. Обработка символьных файлов.
Поскольку символьные устройства потребляют или производят потоки символов, то поддержка произвольного доступа не имеет смысла. Исключение составляет дисциплина линии связи. Дисциплина линии связи может быть связана с терминальным устройством и работает как интерпретатор данных, обмен которыми происходит с терминальным устройством.
Работа с сетевыми устройствами в системе linux отличается от вышерассмотренных. Сетевые устройства также потребляют и производят потоки символов, однако асинхронная природа делает их не очень подходящими для интеграции в один интерфейс с другими символьными устройствами. Драйверы сетевого устройства производят пакеты, состоящие из большого количества байтов (IRP-пакеты). Эти пакеты затем маршрутизируются через несколько драйверов сетевых протоколов и в конечном итоге передаются программе пользователя.
-Ввод и вывод в Linux
Система файлов Linux, ориентированная на устройства, осуществляет доступ к дисковой памяти с помощью двух кэшей:
- Данные хранятся в кэше страниц, который объединен с системой виртуальной памяти;
- Метаданные хранятся в буферном кэше, причем каждый кэш индексируется блоком диска.
Linux разбивает устройства на три класса:
Блочные устройства допускают произвольный доступ к полностью независимым блокам данных фиксированного размера.
Символьные устройства включают большую часть всех других устройств; они не нуждаются в поддержке функциональности обычных файлов.
Сетевые устройства взаимодействуют с сетевой системой ядра.
Модульная структура драйверов устройств в Linux изображена на рис. 26.5.
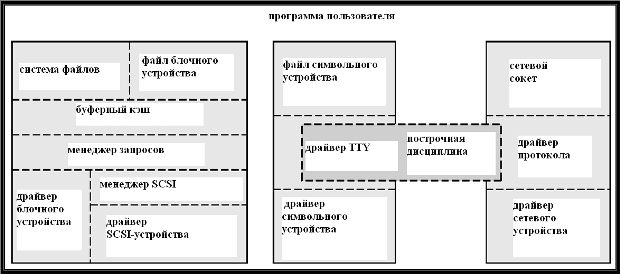
Рис. 26.5. Модульная структура драйверов устройств.
Блочные устройства обеспечивают основной интерфейс ко всем дисковым устройствам в системе. Блочный буферный кэш служит для двух основных целей:
Менеджер запросов управляет чтением и записью содержимого буферов с помощью драйвера блочного устройства.
Символьные устройства. Драйвер символьного устройства не поддерживает произвольный доступ к фиксированным блокам данных.
Драйвер символьного устройства регистрирует набор функций, реализующих разнообразные требуемые операции ввода-вывода.
Ядро не выполняет почти никакой предварительной обработки запроса на чтение или запись в файл символьного устройства, но просто передает данный запрос драйверу устройства.
Основное исключение из этого правила – это особый набор драйверов символьных устройств, которые реализуют доступ к терминальным устройствам (TTY); для них ядро поддерживает стандартный интерфейс.
-Алгоритмы планирования запросов к жесткому диску
Прежде чем приступить к непосредственному изложению самих алгоритмов, давайте вспомним внутреннее устройство жесткого диска и определим, какие параметры запросов мы можем использовать для планирования.
-Строение жесткого диска и параметры планирования
Современный жесткий магнитный диск представляет собой набор круглых пластин, находящихся на одной оси и покрытых с одной или двух сторон специальным магнитным слоем (см. рис. 13.2). Около каждой рабочей поверхности каждой пластины расположены магнитные головки для чтения и записи информации. Эти головки присоединены к специальному рычагу, который может перемещать весь блок головок над поверхностями пластин как единое целое. Поверхности пластин разделены на концентрические кольца, внутри которых, собственно, и может храниться информация. Набор концентрических колец на всех пластинах для одного положения головок (т. е. все кольца, равноудаленные от оси) образует цилиндр. Каждое кольцо внутри цилиндра получило название дорожки (по одной или две дорожки на каждую пластину). Все дорожки делятся на равное число секторов. Количество дорожек, цилиндров и секторов может варьироваться от одного жесткого диска к другому в достаточно широких пределах. Как правило, сектор является минимальным объемом информации, которая может быть прочитана с диска за один раз.
При работе диска набор пластин вращается вокруг своей оси с высокой скоростью, подставляя по очереди под головки соответствующих дорожек все их сектора. Номер сектора, номер дорожки и номер цилиндра однозначно определяют положение данных на жестком диске и, наряду с типом совершаемой операции — чтение или запись, полностью характеризуют часть запроса, связанную с устройством, при обмене информацией в объеме одного сектора.
При планировании использования жесткого диска естественным параметром планирования является время, которое потребуется для выполнения очередного запроса.
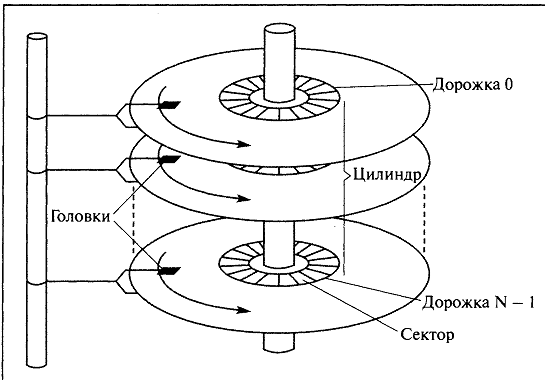
Рис. 13.2. Схема жесткого диска
Время, необходимое для чтения или записи определенного сектора на определенной дорожке определенного цилиндра, можно разделить на две составляющие: время обмена информацией между магнитной головкой и компьютером, которое обычно не зависит от положения данных и определяется скоростью их передачи (transfer speed), и время, необходимое для позиционирования головки над заданным сектором, — время позиционирования (positioning time). Время позиционирования, в свою очередь, состоит из времени, необходимого для перемещения головок на нужный цилиндр, — времени поиска (seek time) и времени, которое требуется для того, чтобы нужный сектор довернулся под головку, задержки на вращение (rotational latency). Времена поиска пропорциональны разнице между номерами цилиндров предыдущего и планируемого запросов, и их легко сравнивать. Задержка на вращение определяется довольно сложными соотношениями между номерами цилиндров и секторов предыдущего и планируемого запросов и скоростями вращения диска и перемещения головок. Без знания соотношения этих скоростей сравнение становится невозможным. Поэтому естественно, что набор параметров планирования сокращается до времени поиска различных запросов, определяемого текущим положением головки и номерами требуемых цилиндров, а разницей в задержках на вращение пренебрегают.
Ввод и вывод в Linux
Система файлов Linux, ориентированная на устройства, осуществляет доступ к дисковой памяти с помошью двух кэшей:

- Данные хранятся в кэше страниц, который объединен с системой виртуальной памяти;
- Метаданные хранятся в буферном кэше, причем каждый кэш индексируется блоком диска.
Linux разбивает устройства на три класса: Блочные устройства допускают произвольный доступ к полностью независимым блокам данных фиксированного размера. Символьные устройства включают большую часть всех других устройств; они не нуждаются в поддержке функциональности обычных файлов. Сетевые устройства взаимодействуют с сетевой системой ядра. Модульная структура драйверов устройств в Linux изображена на рис. 1.5. Рис. 1.5. Модульная структура драйверов устройств. Блочные устройства обеспечивают основной интерфейс ко всем дисковым устройствам в системе. Блочный буферный кэш служит для двух основных целей:
- Как буферный пул для активного ввода-вывода
- Как кэш для завершенного ввода-вывода.
Менеджер запросов управляет чтением и записью содержимого буферов с помощью драйвера блочного устройства. Символьные устройства. Драйвер символьного устройства не поддерживает произвольный доступ к фиксированным блокам данных. Драйвер символьного устройства регистрирует набор функций, реализующих разнообразные требуемые операции ввода-вывода. Ядро не выполняет почти никакой предварительной обработки запроса на чтение или запись в файл символьного устройства, но просто передает данный запрос драйверу устройства. Основное исключение из этого правила – это особый набор драйверов символьных устройств, которые реализуют доступ к терминальным устройствам (TTY); для них ядро поддерживает стандартный интерфейс.
Взаимодействие процессов в Linux
Как и UNIX, Linux информирует процессы о наступлении событий с помощью сигналов. Существует ограниченный набор сигналов, и они не могут нести какую-либо информацию: только факт, что сигнал имеет место, доступен процессу. Ядро Linux не использует сигналы для коммуникации процессов, исполняемых в режиме ядра. Коммуникация внутри ядра осуществляется с помощью структур планировщика – states (состояния) и wait.queue (очередь ожидания). Механизм конвейера (pipe) позволяет дочернему процессу наследовать коммуникационный канал от процесса-родителя. Данные, записываемые с одного конца конвейера, могут быть прочитаны на другом конце. Общая память обеспечивает очень быстрый способ коммуникации; любые данные, записанные одним процессом в регион общей памяти, могут быть немедленно прочитаны любым другим процессом, который отобразил этот регион в свое адресное пространство. Однако с целью синхронизации общая память должна использоваться в сочетании с каким-либо другим комуникационным механизмом. Объект в общей памяти используется как файл откачки для регионов общей памяти, так же как файл может быть использован для откачки информации из региона, отображаемого в память. Отображения в общую память перенаправляют отказы страниц в регион памяти, занятый разделяемым объектом. Разделяемые объекты помнят свое содержимое, даже если в данный момент никакие процессы не отображают их в свои виртуальные пространства памяти.