Как узнать причину перезагрузки Linux
👋🏻 Привет! С вами снова Merion Academy — платформа доступного IT образования . Сегодня мы расскажем о том, как узнать причину перезагрузки Linux. Гоу.
Часто бывает, что на системе Linux произошла незапланированная или по неизвестным очевидным причинам, перезагрузка. Поиск и устранение первопричины может помочь предотвратить повторение таких проблем и избежать незапланированных простоев.
Есть несколько способов выяснить, что вызвало перезагрузку. В этой статье мы обсудим эти способы и способы использования доступных утилит и журналов в системе Linux для устранения таких сценариев.
Проверка времени перезагрузки
Чтобы посмотреть, когда именно произошла перезагрузка системы можно воспользоваться командами who и last
Проверка системных журналов
Кроме того, можно сопоставить время перезагрузки, которую требуется диагностировать, с системными сообщениями.
Для систем CentOS/RHEL журналы можно найти по адресу /var/log/messages , а для систем Ubuntu/Debian — по адресу /var/log/syslog . Для фильтрации или поиска конкретных данных можно использовать команду tail или любимый текстовый редактор.
Как видно из приведенных ниже журналов, такие записи предполагают завершение работы или перезагрузку, инициированную администратором или пользователем root . Эти сообщения могут варьироваться в зависимости от типа ОС и способа запуска перезагрузки или завершения работы, но вы всегда найдете полезную информацию, просматривая системные журналы, хотя этого не всегда может быть достаточно, чтобы определить причину.
Ниже приведена одна такая команда, которую можно использовать для фильтрации системных журналов:
sudo grep — iv ‘: starting\|kernel: .*: Power Button\|watching system buttons\|Stopped Cleaning Up\|Started Crash recovery kernel’ \
/ var / log / messages / var / log / syslog / var / log / apcupsd * \
| grep — iw ‘recover[a-z]*\|power[a-z]*\|shut[a-z ]*down\|rsyslogd\|ups’
Зафиксированные события не всегда могут быть конкретными. Всегда отслеживайте события, которые дают признаки предупреждений или ошибок, которые могут привести к выключению или сбою системы.
Проверка журнала auditd
Для систем, использующих auditd – это отличное место для проверки различных событий с помощью инструмента ausearch . Используйте приведенную ниже команду для проверки последних двух записей из журналов аудита.
$ sudo ausearch — i — m system_boot , system_shutdown | tail — 4
Появится сообщение о двух последних остановках или перезагрузках. Если это сообщает о SYSTEM_SHUTDOWN , за которым следует SYSTEM_BOOT , все должно быть хорошо. Но, если он сообщает две строки SYSTEM_BOOT подряд или только одно сообщение SYSTEM_BOOT , то, скорее всего, система некорректно завершила работу. Вывод при нормальной работе должен быть примерно следующим:
$ sudo ausearch — i — m system_boot , system_shutdown | tail — 4
—-
type = SYSTEM_SHUTDOWN msg = audit ( Saturday 13 February 2021 A . 852 : 8 ) : pid = 621 uid = root auid = unset ses = unset subj = system_u : system_r : init_t : s0 msg = ‘ comm=systemd-update-utmp exe=/usr/lib/systemd/systemd-update-utmp hostname=? addr=? terminal=? res=success’
—-
type = SYSTEM_BOOT msg = audit ( Saturday 13 February 2021 A . 368 : 8 ) : pid = 622 uid = root auid = unset ses = unset subj = system_u : system_r : init_t : s0 msg = ‘ comm=systemd-update-utmp exe=/usr/lib/systemd/systemd-update-utmp hostname=? addr=? terminal=? res=success’
В приведенных ниже выходных данных перечислены два последовательных сообщения SYSTEM_BOOT , которые могут указывать на аварийное завершение работы, хотя результаты нужно скорректировать с данными системного журнала.
$ sudo ausearch — i — m system_boot , system_shutdown | tail — 4
—-
type = SYSTEM_BOOT msg = audit ( Saturday 13 February 2021 A . 852 : 8 ) : pid = 621 uid = root auid = unset ses = unset subj = system_u : system_r : init_t : s0 msg = ‘ comm=systemd-update-utmp exe=/usr/lib/systemd/systemd-update-utmp hostname=? addr=? terminal=? res=success’
—-
type = SYSTEM_BOOT msg = audit ( Saturday 13 February 2021 A . 368 : 8 ) : pid = 622 uid = root auid = unset ses = unset subj = system_u : system_r : init_t : s0 msg = ‘ comm=systemd-update-utmp exe=/usr/lib/systemd/systemd-update-utmp hostname=? addr=? terminal=? res=success’
Анализ журнала systemd
Чтобы сохранить журнал системных логов на диске, необходимо иметь постоянный системный журнал, иначе логи будут очищаться при перезагрузке. Для этого можно либо внести изменения в /etc/systemd/journald.conf , либо создать каталог самостоятельно с помощью следующих команд:
$ sudo mkdir / var / log / journal
$ sudo systemd — tmpfiles — create — prefix / var / log / journal 2 > /dev/ null
$ sudo systemctl — s SIGUSR1 kill systemd — journald
После этого можно дополнительно перезагрузить систему для ввода нескольких записей перезагрузки в журнал, хотя это и не требуется.
Приведенную ниже команда позволяет выводить список записанных событий о загрузке из журнала:
Вот его выходные данные на моем сервере:
Ubuntu Server — узнать причину перезагрузки

Сервер с операционной системой Ubuntu Server 16 ушёл в перезагрузку. Да-да, не самая новая ОС. Анализ логов не дал понимания, что-же произошло. Как узнать причину перезагрузки?
Большая часть советов из Интернет не дала нужного результата, но потом, парочка статей подсказала где искать. В Oracle Linux есть сервис kdump, который в директорию /var/crash сохраняет аварийный дамп памяти и dmesg. В Ubuntu Server такой службы нет. Однако, где-то же Oracle Linux берёт dmesg даже после аварийного отключения питания сервера, где-то же эти данные есть.
Про pstore
Мы не первые у кого сервер не смог скинуть в файлы лога информацию об аварийном завершении работы. Ещё в доисторические времена у серверов выходили из строя диски, память, отключалось питание. Специально для нас в Linux была сделана такая штука как pstore — Persistent STORagE file system. Основная идея — сохранять лог ошибок где-то в энергонезависимой памяти. И отдельно от дисков. Для сохранения такой информации могут использоваться разные хранилища: — это ACPI ERST и UEFI.
ERST (Error Record Serialization Table) — это механизм, указанный в спецификации ACPI (Advanced Configuration and Power Interface), который позволяет сохранять и извлекать информацию об аппаратных ошибках в энергонезависимое место (например, во флэш-память). Такой механизм обычно реализован в серверных платформах.
Не обычных старых компьютерах есть только одно место с энергонезависимой памятью — это часы реального времени, но там мало места, логи не сбросишь. Но более новые ПК (и сервера) могут иметь память в UEFI.
Выбор куда писать ошибки (ERST или UEFI) можно настроить при конфигурировании ядра. По умолчанию в Ubuntu Server используется ERST, но это не точно.
Ищем ошибки
В любом случае, если ваш сервер реализует механизм pstore, то хранилище в Debian-подобных системах после загрузки монтируется в /sys/fs/pstore.
При хранении дампов в ERST можно увидеть такую картину:
# ls -al /sys/fs/pstore total 0 drwxr-x--- 2 root root 0 Jul 28 11:35 . drwxr-xr-x 9 root root 0 Jul 28 11:35 .. -r--r--r-- 1 root root 17711 Jul 28 11:35 dmesg-erst-6990001317951307777 -r--r--r-- 1 root root 17755 Jul 28 11:35 dmesg-erst-6990001317951307778 -r--r--r-- 1 root root 17736 Jul 28 11:35 dmesg-erst-6990001317951307779 -r--r--r-- 1 root root 17746 Jul 28 11:35 dmesg-erst-6990001317951307780При хранении дампов в UEFI картина немного другая:
# ls -al /sys/fs/pstore total 0 drwxr-x--- 2 root root 0 May 9 09:50 . drwxr-xr-x 7 root root 0 May 9 09:50 .. -r--r--r-- 1 root root 1610 May 9 09:49 dmesg-efi-155741337601001 -r--r--r-- 1 root root 1778 May 9 09:49 dmesg-efi-155741337602001 -r--r--r-- 1 root root 1726 May 9 09:49 dmesg-efi-155741337603001 -r--r--r-- 1 root root 1746 May 9 09:49 dmesg-efi-155741337604001Вывод данных может и отличаться, здесь приведены примеры для Oracle Linux. В примере ниже он будет немного другой, для Ubuntu Server 16, но это и не принципиально.
Читаем dmesg
Итак, Ubuntu Server 16 аварийно перезагрузился. В логах ничего нет. Смотрим pstore.
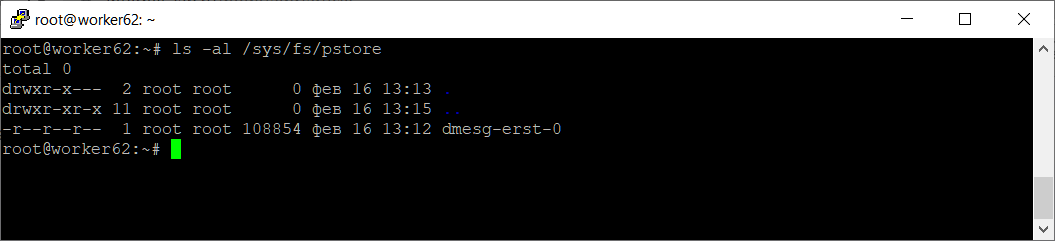
Есть один файл dmesg-erst-0. Дата создания файла говорит нам о том, что именно в это время произошёл сбой, как раз в этот период времени в логах ничего найти не удалось.
cp /sys/fs/pstore/dmesg-erst-0 /tmpТеперь можно прочитать файл:
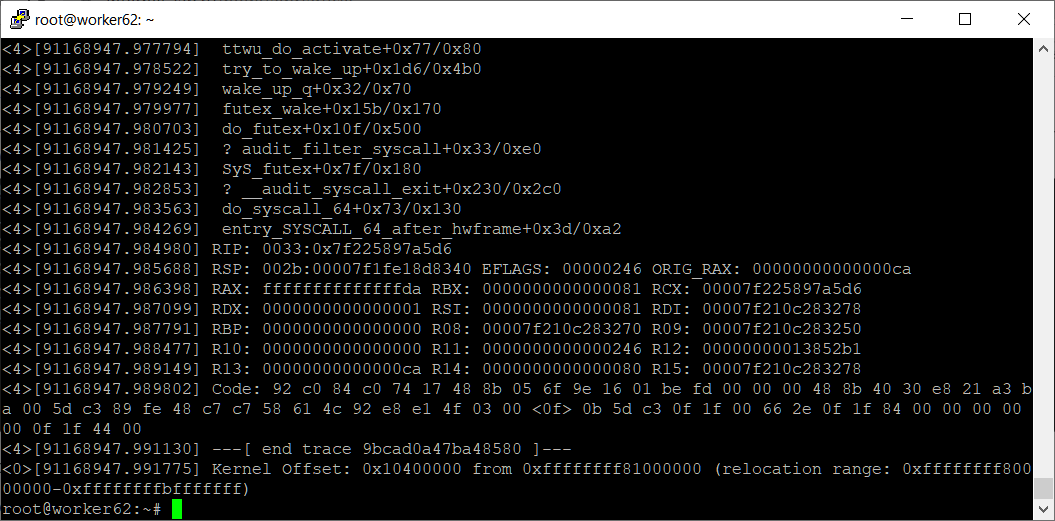
Дата выводится в неудобном формате, можно исправить с помощью dmesg:

Ориентироваться со временем стало проще. Следует понимать, что дата в dmesg живёт какой-то своей жизнью. Не стал разбираться, просто снизу отмотал до первого сбоя, ближе к времени последней записи:
------------[ cut here ]------------ kernel BUG at /build/linux-hwe-IBxGXO/linux-hwe-4.15.0/include/linux/fs.h:2804! invalid opcode: 0000 [#1] SMP PTI

Кто знает как преобразовать дату к удобоваримому виду — пишите в комментариях.
Узнать время и причину перезагрузки системы?
Всех приветствую, подскажите, казалось бы простой вопрос, но выводы разных команд неоднозначные.
Надо выяснить время последней загрузки системы и её причины (самопроизвольной перезагрузки)
Т.к. имеется машина с Debian 11, и она иногда самопроизвольно перезагружается, последняя перезагрузка была сегодня ночью, 22.12.2022 то есть,
пытаюсь выяснить точное время перезагрузки, фактически этим временем будет время загрузки до момента запуска системы:
Выполняю:
То есть система запустилась в 01:52:05 22.12.2022
Но если выполнить who -b то результат получаю уже другой:
$ who -b system boot 2022-12-22 04:52$ last -x | head | tac reboot system boot 5.10.0-18-amd64 Sat Dec 17 22:35 - 19:35 (-2:59) runlevel (to lvl 5) 5.10.0-18-amd64 Sat Dec 17 19:35 - 19:35 (00:00) user tty7 :0 Sat Dec 17 19:35 - 19:35 (00:00) shutdown system down 5.10.0-18-amd64 Sat Dec 17 19:35 - 22:07 (3+02:32) reboot system boot 5.10.0-18-amd64 Tue Dec 20 22:07 still running runlevel (to lvl 5) 5.10.0-18-amd64 Tue Dec 20 19:08 - 01:52 (1+06:44) user tty7 :0 Tue Dec 20 19:08 - crash (1+09:43) reboot system boot 5.10.0-18-amd64 Thu Dec 22 04:52 still running user tty7 :0 Thu Dec 22 01:52 still logged in runlevel (to lvl 5) 5.10.0-18-amd64 Thu Dec 22 01:52 still running$last reboot reboot system boot 5.10.0-18-amd64 Thu Dec 22 04:52 still running reboot system boot 5.10.0-18-amd64 Tue Dec 20 22:07 still running reboot system boot 5.10.0-18-amd64 Sat Dec 17 22:35 - 19:35 (-2:59) reboot system boot 5.10.0-18-amd64 Thu Dec 15 15:50 - 19:26 (2+03:36) reboot system boot 5.10.0-18-amd64 Tue Dec 13 21:31 - 12:49 (1+15:18) reboot system boot 5.10.0-18-amd64 Sun Dec 11 09:32 - 08:10 (-1:22) reboot system boot 5.10.0-18-amd64 Sat Dec 10 22:27 - 06:20 (07:53) reboot system boot 5.10.0-18-amd64 Sat Dec 10 22:26 - 19:27 (-2:59) reboot system boot 5.10.0-18-amd64 Fri Dec 9 18:29 - 19:27 (1+00:58)Ввожу journalctl —list-boots и получаю :
$journalctl --list-boots -7 87dfc57ca71c4222bef22bfa5dbae479 Fri 2022-12-09 18:30:00 MSK—Sat 2022-12-10 19:24:57 MSK -6 64c776f2b80c428da59decdf072c6ef5 Sat 2022-12-10 19:28:23 MSK—Sun 2022-12-11 06:20:53 MSK -5 74197b0e4b374149be74c7ec044be8fe Sun 2022-12-11 06:35:30 MSK—Sun 2022-12-11 08:10:15 MSK -4 3fa332231dcd483681012600fb04e009 Wed 2022-12-14 09:21:51 MSK—Thu 2022-12-15 12:49:20 MSK -3 30f364131acb45b793dcafd8c908de6c Thu 2022-12-15 12:50:22 MSK—Sat 2022-12-17 19:26:46 MSK -2 7a43f3e651f04f0ba38ea2a1523a2a64 Sat 2022-12-17 19:35:18 MSK—Sat 2022-12-17 19:35:35 MSK -1 dde5f76cb00a4bcc9a2eaf80a5bc1bba Tue 2022-12-20 19:08:15 MSK—Wed 2022-12-21 05:32:31 MSK 0 3156e721dffc49ee95e72f197ab74fa4 Thu 2022-12-22 01:52:31 MSK—Thu 2022-12-22 11:02:01 MSKДалее, надо почитать логи системных журнал, что происходило перед перезагрузкой,
нагуглил команду:
sudo grep -iv ': starting\|kernel: .*: Power Button\|watching system buttons\|Stopped Cleaning Up\|Started Crash recovery kernel' \ /var/log/messages /var/log/syslog /var/log/apcupsd* \ | grep -iw 'recover[a-z]*\|power[a-z]*\|shut[a-z ]*down\|rsyslogd\|ups'Смотрю инфу по последней загрузке с номером 0:
$journalctl -b -0 -n
Да и просто смотрю журналы /var/log/messages, /var/log/kern.log и вижу:
Весь вывод /var/log/messages приводить не имеет смысла так как важно узнать что было до перезагрузки, т.е. до [ 0.000000]
а начиная с [ 0.000000] уже пошла загрузка системы,
итого как я вижу события до перезагрузки:
Но ничего что может вызвать перезагрузку не вижу
также смотрю и /var/log/kern.log, ессно и интересны только события до [ 0.000000] :
И тоже не вижу ничего особенного
Простой 4 комментария