Сетевые и иерархические модели данных
Сетевая или иерархическая модели данных реализуют соответствующий метод логической организации базы данных в СУБД, поддерживающей модель, и операции по обработке данных. До массового внедрения ПК СУБД, поддерживающие сетевую модель данных, были наиболее распространенными.
В СУБД, поддерживающих иерархические и сетевые модели данных, как правило, требуется производить настройку на конкретную БД. При этом надо делать описание структуры базы данных – схемы данных средствами языка описания данных (ЯОД). Полученное описание подлежит генерации для формирования специального программного модуля, который используется при всех обращениях к базе данных. Изменения в структуре БД требуют корректировки описания модели и повторной генерации программного модуля 10,12.
Операции обработки данных сетевых и иерархических моделей осуществляются средствамиязыка манипулирования данными. Язык манипулирования данными, который реализует типовые процедуры доступа к данным, специфичен для каждой сетевой или иерархической СУБД.
Структуры данных сетевых и иерархических моделей
К типовым структурам данных относятся: элемент данных, агрегат данных, запись, база данных.
Элемент данных (атрибут)– это наименьшая поименованная структурная единица данных (аналог поля в файловых системах).
Агрегат данных– поименованное подмножество элементов данных или других агрегатов внутри записи. В агрегатах допускается множественный элемент, который содержит несколько значений элемента в одном экземпляре агрегата.
Записьв сетевой или иерархической модели в общем случае является составным агрегатом, который не входит в состав других агрегатов. Она характеризуется структурой взаимосвязей ее элементов и агрегатов. Структура записи может иметь иерархический характер. Все множество экземпляров записи одинаковой структуры образуюттип записи. Запись конкретного типа в иерархической модели являетсяобъектом моделиданных.
На рис.1 приведен пример иерархической записи, в которой имеются названные выше типы структур данных. Тип записи назван “Договор”, так как в записи представлена вся структура информации о договорах с заказчиками на поставку изделий.
Следует отметить, что собственно данные (элементарные данные, имеющие значение) представлены лишь в конечных (терминальных) вершинах записи. Остальные типы структур данных, в том числе агрегаты, являются лишь поименованной совокупностью данных (групповыми данными).
Связи объектов в сетевых и иерархических моделях данных
Модель данных, как правило, включает несколько разных объектов. Между объектами модели данных устанавливаются связи. Совокупность взаимосвязанных конкретных объектов модели для некоторой предметной области образует базу данных.
Связи между любыми двумя объектами модели определяются групповыми отношениями между их экземплярами.

Рис.1. Пример иерархической записи “Договор”.
Групповое отношение(набор) – это строго иерархическое отношение между записями двух типов: главной записью набора и подчиненными записи набора.
Способы организации групповых отношений. Отличия в разных СУБД может иметь и организация связей (групповых отношений) объектов сетевой модели – цепи, логические связи (аналоги набора). При этом могут отличаться и способы реализации групповых отношений, например, с помощью адресных указателей или по ключу связи (атрибуту связи) – одинаковому в связанных объектах (записях, файлах) модели.
Связи в иерархических и сетевых моделях часто реализуются физически и при большом числе объектов преимущества организации базы данных могут резко снижаться из-за трудностей поддержания связей, которые становятся громоздкими.
Модель данных
В иерархическоймодели база данных представляется в виде иерархически упорядоченных структур – деревьев (диаграммы Бахмана). Каждая вершина дерева означает объект данных, каждая дуга означает связь между объектами. Все вершины графа – дерева распределены по уровням. Каждая вершина низшего уровня связана только с одной вершиной из верхнего уровня. Связей внутри уровня и через уровень не существует. На самом верхнем уровне существует только одна вершина — корень дерева. корень 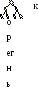 2-й уровень Пример, описание ННГУ в иерархической модели выглядит так 2 уровень. К
2-й уровень Пример, описание ННГУ в иерархической модели выглядит так 2 уровень. К орень дерева Вуз
орень дерева Вуз 
 Уровень 1. Университет вершины
Уровень 1. Университет вершины 

 У
У
 ровень 2. Финансовый ф-т Мехмат
ровень 2. Финансовый ф-т Мехмат 
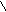 связи У
связи У
 ровень 3. Группа 1311 У
ровень 3. Группа 1311 У


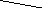 ровень 4. Иванов И.И. Рис. 4.3. Иерархическая модель Ниже перечислены преимущества иерархической модели.
ровень 4. Иванов И.И. Рис. 4.3. Иерархическая модель Ниже перечислены преимущества иерархической модели.
- Простота модели. Иерархия базы данных напоминает структуру компании или генеалогическое дерево.
- Использование отношений предок/потомок. СУБД позволяет легко представлять отношения подчиненности, например: «А является частью В» или «А владеет В».
- Быстродействие. В СУБД отношения предок/потомок реализованы в виде физических указателей из одной записи на другую, вследствие чего перемещение по базе данных происходило быстро.
Групповое отношение— иерархическое отношение между записями двух типов. Родительская запись называется исходной записью, а дочерние записи – подчиненными. Для групповых отношений в иерархической модели обеспечивается автоматический режим включения ификсированное членство. Это означает, что для запоминания любой некорневой записи в БД должна существовать ее родительская запись. При удалении родительской записи автоматически удаляются все подчиненные. Недостатки иерархических БД:
- Каждый объект данных может участвовать только в одной иерархии объектов. Поэтому, если объект должен присутствовать в нескольких иерархиях, то его приходится дублировать.
Например, данные о сотруднике должны участвовать в иерархии подчиненности отделам и в подчиненности контрактам в качестве исполнителей (такие записи называют парными). В иерархической модели не предусмотрена поддержка соответствия между парными записями.
- . Иерархическая модель реализует отношение между исходной и дочерней записью по схеме l:N, то есть одной родительской записи может соответствовать любое число дочерних. Допустим теперь, что исполнитель может принимать участие более чем в одном контракте (т.е. возникает связь типа M:N). В этом случае в базу данных необходимо ввести еще одно групповое отношение, в которомИсполнитель будет являться исходной записью, а контракт – дочерней. Таким образом, мы опять вынуждены дублировать информацию.
- Изменение структуры данных требует перестройки всей системы указателей на записи.
Чтобы получить доступ к данным, содержащимся в базе данных, СУБД может:
- найти конкретный объект (Финансовый факультет) по его номеру;
- перейти «вниз» к первому потомку (Группа 13101);
- перейти «вверх» к предку (Университет);
- перейти «в сторону» к другому потомку (Мехмат).
Таким образом, для чтения данных из иерархической базы данных требуется перемещаться по записям, за один раз переходя на одну запись вверх, вниз или в сторону. Поддерживается только целостность связей между владельцами и членами группового отношения (никакой потомок не может существовать без предка). Типичным представителем иерархической модели является СУБД Information Management System (IМS) фирмы IBM. Первая версия появилась в 1968 г. В сетевоймодели БД изображается в виде графа произвольной структуры (рис 11.4.). 

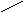

 А В
А В 
 С
С 
 Д
Д 
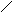 Е Рис. 11.4. Основные различия двух моделей состоят в том, что в сетевой модели запись может быть членом более чем одного группового отношения. Согласно сетевой модели каждое групповое отношение именуется и проводится различие между его типом и экземпляром. Тип группового отношения задается его именем и определяет свойства, общие для всех экземпляров данного типа. Экземпляр группового отношения представляется записью-владельцем и множеством (возможно пустым) подчиненных записей. При этом имеется следующее ограничение: экземпляр записи не может быть членом двух экземпляров групповых отношений одного типа (т.е. сотрудник, например, не может работать в двух отделах). Каждый экземпляр группового отношения характеризуется следующими признаками:
Е Рис. 11.4. Основные различия двух моделей состоят в том, что в сетевой модели запись может быть членом более чем одного группового отношения. Согласно сетевой модели каждое групповое отношение именуется и проводится различие между его типом и экземпляром. Тип группового отношения задается его именем и определяет свойства, общие для всех экземпляров данного типа. Экземпляр группового отношения представляется записью-владельцем и множеством (возможно пустым) подчиненных записей. При этом имеется следующее ограничение: экземпляр записи не может быть членом двух экземпляров групповых отношений одного типа (т.е. сотрудник, например, не может работать в двух отделах). Каждый экземпляр группового отношения характеризуется следующими признаками:
- способ упорядочения подчиненных записей:
- произвольный,
- хронологический /очередь/,
- обратный хронологический /стек/,
- сортированный.
Если запись объявлена подчиненной в нескольких групповых отношениях, то в каждом из них может быть назначен свой способ упорядочивания.
- режим включения подчиненных записей:
- автоматический — невозможно занести в БД запись без владельца;
- ручной — позволяет запомнить в БД подчиненную запись и не включать ее немедленно в экземпляр группового отношения. Эта операция позже инициируется пользователем.
- Гибкость. Множественные отношения предок/потомок позволяли хранить данные, структура которых была сложнее простой иерархии.
- Стандартизация. Появление стандарта CODASYL обеспечили популярность сетевой модели.
- Быстродействие. Вопреки своей большой сложности, сетевые базы данных достигли быстродействия, сравнимого с быстродействием иерархических баз данных. Множества были представлены указателями на физические записи данных.
Конечно, у сетевых баз данных были недостатки. Как и иерархические базы данных, сетевые базы данных были очень жесткими. Наборы отношений и структуру записей приходилось задавать наперед. Изменение структуры базы данных обычно означало перестройку всей базы данных. Как иерархическая, так и сетевая база данных были инструментами программистов. Чтобы получить ответ на вопрос типа: «Какой товар наиболее часто заказывает компания Паровые машины?», программисту приходилось писать программу для навигации по базе данных. Реализация пользовательских запросов часто затягивалась на недели и месяцы, и к моменту появления программы информация, которую она предоставляла, часто оказывалась бесполезной. Типичным представителем является Integrated Database Management System (IDMS) компании Cиllinet Software, Inc. Практически все существующие СУБД в наше время используют реляционную модель данных.
Для продолжения скачивания необходимо пройти капчу: