- Print first and last line of all files in folder
- 10 Answers 10
- Explanation
- Explanation
- Print a file, skipping the first X lines, in Bash [duplicate]
- 13 Answers 13
- How to use head and tail Command in Linux
- Syntax of head command
- Example
- Options used with head
- 1. Printing Some Characters and not lines
- 2. Print first n lines
- tail
- Syntax
- Example
- Options Used with tail command
- 1. Printing Some Characters and not lines
- 2. Print first n lines
- 3. To see a real time view of data being added to file
- Practice Questions on how to use head and tail command in Linux
Print first and last line of all files in folder
I have a bunch of log files that get overwritten ( file.log.1 , file.log.2 etc). When I copy them from the device making them onto my local machine I lose the original time stamps. So I’d like to put them in chronological order. The problem is that I don’t necessarily know which is the newest and which is the oldest. What I’d like to be able to do is, if all the logs are in a directory, print something like this:
file: file.log.1 first line: [first line that isn't whitespace] last line: [last line that isn't whitespace] I can just write a python script to do this, but I’d much rather do it with linux built-ins if possible. Is this a job for awk/sed? Or would this really be better off for a scripting language? If yes to awk/sed, how woul dyou go about doing it? I found this awk command by searching, but it only accepts one file name and will print whatever the last line is (and there can be a variable number of empty lines at the end)
What are you using to copy the files? If you are copying to another linux file system then you should be able to preserve user, timestamp data. e.g. cp -p
10 Answers 10
So I like sed the answer can be
for file in file.log.* do echo "file: $file" echo -n "first line: " cat "$file" | sed -n '/^\s*$/!' echo -n "last line: " tac "$file" | sed -n '/^\s*$/!' done No need to echo+cat and echo+tac , you could just sed -n ‘/^[[:space:]]*$/!‘ «$file» and sed -n ‘/^[[:space:]]*$/!h;$!d;g;s/^/last line: /p’ «$file»
@don_crissti Nice. I like such decisions. But echo+tac much simple and, in case of big file, quicker.
It works like a charm. But I really don’t know what the thing is you put into the sed argument, especially the
awk -v OFS=: ' FNR==1 < # the last non-blank line from the previous file if (line) filename=FILENAME line="" p=0 > /^[[:blank:]]*$/ !p < # the first non-blank line print FILENAME, FNR, $0; p=1 > END ' * for each file, print the filename, line number and line, colon-separated.
GNU awk v4 has BEGINFILE and ENDFILE patterns which simplify things quite a bit:
gawk -v OFS=: ' BEGINFILE /^[[:blank:]]*$/ !p ENDFILE ' * Another approach would be to use head and tail :
EDIT (Thank you for the suggestion @don_crissti!)
for file in file.log.* do echo "file: $file" echo -n "first line: " grep -v '^\s*$' "$file" | head -n1 echo -n "last line: " grep -v '^\s*$' "$file" | tail -n1 done As per the question, OP wants to print the «first & last lines that aren’t whitespace». So you could do something like grep -v ‘^\s*$’ «$file» | head -n 1 and grep -v ‘^\s*$’ «$file» | tail -n 1 to get the expected result.
for file in file.log.*; do echo "FILE: $file"; perl -ne 'if(/\S/)<$k++; $l=$_>; print "First line: $_" if $k==1; END' "$file"; done Explanation
- for file in file.log.* : iterate over all files whose names starts with file.log. in the current directory and save each of them as $file .
- echo «FILE: $file»; : print the file name.
- perl -ne : read the current input file line by line ( -n ), saving each line as the special Perl variable $_ , and run the script given by -e on it.
- if(/\S/) <$k++; $l=$_>: if the current line matches a non-whitespace character ( \S ), save the line as $l and increment the counter $k by one.
- print «First line: $_» if $k==1; : print the current line ( $_ ) if $k is 1 . This will print the 1st non-whitespace line.
- END : this is executed after all input lines have been read. Since we save each non-whitespace line as $l , at the end of the file, $l will be the last non-whitespace line. Therefore, this will print the last line.
for file in file.log.*; do printf "FILE: %s\nFirst line: %s\nLast line: %s\n\n" \ "$file" \ "$(grep -Em 1 '\S' "$file")" \ "$(tac "$file" | grep -Em1 '\S' )"; done Explanation
This is the same for loop only here we’re using printf to print three strings. The file name, and the output of these two commands:
- grep -Pm 1 ‘\S’ «$file» : The -E activates Extended Regular Expressions which let us use \S for «non-whitespace». The -m1 means «exit after the first match found».
- tac «$file» | grep -Em1 ‘\S’ : tac is the inverse of cat . It will print the contents of a file, but from the last line to the first line. Therefore, this command will print the last non-whitespace line.
Print a file, skipping the first X lines, in Bash [duplicate]
I have a very long file which I want to print, skipping the first 1,000,000 lines, for example. I looked into the cat man page, but I did not see any option to do this. I am looking for a command to do this or a simple Bash program.
13 Answers 13
You’ll need tail. Some examples:
If you really need to SKIP a particular number of «first» lines, use
That is, if you want to skip N lines, you start printing line N+1. Example:
If you want to just see the last so many lines, omit the «+»:
in centos 5.6 tail -n +1 shows the whole file and tail -n +2 skips first line. strange. The same for tail -c +
@JoelClark No, @NickSoft is right. On Ubuntu, it’s tail -n +
this must be outdated, but, tail -n+2 OR tail -n +2 works, as with all short commands using getopt, you can run the parameter right next to it’s switch, providing that the switch is the last in the group, obviously a command like tail -nv+2 would not work, it would have to be tail -vn+2. if you dont believe me try it yourself.
Easiest way I found to remove the first ten lines of a file:
In the general case where X is the number of initial lines to delete, credit to commenters and editors for this:
In the more general case, you’d have to use sed 1,Xd where X is the number of initial lines to delete, with X greater than 1.
This makes more sense if you don’t know how long the file is and don’t want to tell tail to print the last 100000000 lines.
@springloaded if you need to know the number of lines in the file, ‘wc -l’ will easily give it to you
If you have GNU tail available on your system, you can do the following:
tail -n +1000001 huge-file.log It’s the + character that does what you want. To quote from the man page:
If the first character of K (the number of bytes or lines) is a `+’, print beginning with the Kth item from the start of each file.
Thus, as noted in the comment, putting +1000001 starts printing with the first item after the first 1,000,000 lines.
@Lloeki Awesome! BSD head doesn’t support negative numbers like GNU does, so I assumed tail didn’t accept positives (with +) since that’s sort of the opposite. Anyway, thanks.
Also, to clarify this answer: tail -n +2 huge-file.log would skip first line, and pick up on line 2. So to skip the first line, use +2. @saipraneeth’s answer does a good job of exaplaining this.
If you want to skip first two line:
If you want to skip first x line:
This is somewhat misleading because someone may interpret (x+1) literally. For example, for x=2, they may type either (2+1) or even (3) , neither of which would work. A better way to write it might be: To skip the first X lines, with Y=X+1, use tail -n +Y
A less verbose version with AWK:
But I would recommend using integer numbers.
This version works in the Cygwin tools that come with Git for Windows, whereas tail and sed do not. For example git -c color.status=always status -sb | awk ‘NR > 1’ gives a nice minimal status report without any branch information, which is useful when your shell already shows branch info in your prompt. I assign that command to alias gs which is really easy to type.
How to use head and tail Command in Linux
The head command is used to output a subset of lines from the file starting from the top. By default it will output the first 10 lines.
Syntax of head command
Example

will display the first 10 lines of the file “grepfile”. So make sure you have more than 10 lines in your file to understand the working of head command.
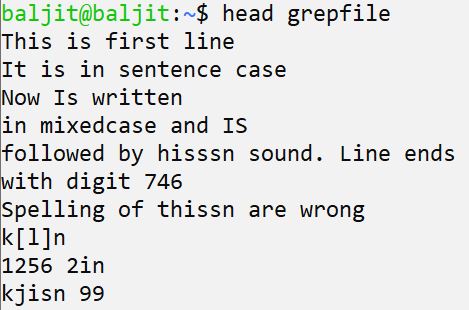
Options used with head
1. Printing Some Characters and not lines
-c: option prints first few bytes of the file. For example:

prints the first 10 characters from the file “grepfile”.
The same option can also be used to print all but the last few characters. For example suppose you want to print all the file content except for the last 10 characters.

All the contents are printed except for the last 10 characters. The result can be compared with the output of cat command which shows the entire content of the file.
2. Print first n lines
-n: prints the first n lines instead of 10. For example,

prints the first two lines of the file “grepfile”
tail
The tail command is used to output a subset of lines of a file from the bottom. By default it prints the last 10 lines
Syntax
Example
will display the last 10 lines of the file “grepfile”. So make sure you have more than 10 lines in your file to understand the working of tail command.

Options Used with tail command
1. Printing Some Characters and not lines
-c: option prints last few bytes of the file. For example:
will print the last 10 characters of the file “grepfile”
2. Print first n lines
-n: prints the last n lines instead of 10. For example,
will print the last 5 lines of the file “grepfile”
3. To see a real time view of data being added to file
-f: This option allows you see the contents being added at real time. Open two terminals. In terminal 1 type the command
where f1.txt is a file having some content. Now you will see the last few lines of the file but the control will not come back to command prompt

Now, in second another terminal type the command
$cat>>f1.txt
write some content
You see that in the first terminal this new line “write some content” is added to the output. So, as you keep on appending content to the file it will come up in the output of tail -f command
Practice Questions on how to use head and tail command in Linux
Q1. How to display the lines starting from the 5 line?
Q2. How can you view all the contents of a file except the last 5 characters